最近做爬虫,在check阶段最后这几天总是遇到内存溢出的问题,分析了一下java堆,发现就是过多的url string存储导致的。今天就总结下url查重的几种方法。
看到网上也有些文章讨论了这个问题,但会略有不同,希望能用两天晚上内存溢出的经验帮助到做爬虫的同志们。当然还要说明一下,这里的爬虫主要是单站的定制爬虫,全网爬虫不是主要考虑的范围。
?
首先,罗列一下所有的方法:
1. HashSet存URL
2. 压缩字符串存入HashSet
3. 改写的字典树
4. Bloom Filter
5. BerkeleyDB
6. NormalDB
?
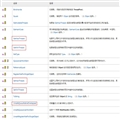
1. HashSet存URL
这是最简单最直观的方式了,但看一下我直接用webmaigc框架中的文件cache调度器调度时候吃到得麻烦也许就比较直观了。这是仅仅存储了很小一部分数据后的情况。
?
2. 压缩字符串存入HashSet
既然太占空间,压缩每个的长度是个比较好的办法。通过md5单向编码url值,可以将每个url的大小都控制在16byte。这种方法没有实践,但如果较小的站点改方法可以很快的修改代码并有不错的效果,因为实际的url存储起来是很占内存空间的。
?
3. 改写的字典树
当时遇到问题后走的不同的思考路线,对于单站而言,公用前缀是非常多的而且长的,因此就希望利用这种特性,字典树肯定是最好的选择。通过屏蔽特殊符号的方式使用字典树可以得到不错的效果,目前测试过程中10w数量级的网页在普通机器不存在任何问题。附上具体代码:
?
class="java" name="code">/**
* URL查找树,去除掉非字符和数字的符号,构造字典树
*
* @author Jason wu
*/
public class URLTrieTree {
//单词查找树根节点,根节点为一个空的节点
private Vertex root = new Vertex();
//单词查找树的节点(内部类)
private class Vertex {
//单词出现次数统计
int wordCount;
//以某个前缀开头的单词,它的出现次数
int prefixCount;
//子节点用数组表示
Vertex[] vertexs = null;
/**
* 树节点的构造函数
*/
public Vertex() {
wordCount = 0;
prefixCount = 0;
}
}
/**
* 单词查找树构造函数
*/
public URLTrieTree() {}
/**
* 向单词查找树添加一个新单词
*
* @param word
* 单词
*/
public synchronized void addWord(String word) {
if(countWord(word)<=0)
addWord(root, word.toLowerCase());
}
/**
* 向单词查找树添加一个新单词
*
* @param root 单词查找树节点
* @param word 单词
*/
private void addWord(Vertex vertex, String word) {
if (word.length() == 0) {
vertex.wordCount++;
} else if (word.length() > 0) {
int index = -1, i=0;
try{
for(;(index = getIndex(word.charAt(i)))==-1;i++){}
}catch(IndexOutOfBoundsException e){
vertex.wordCount++;
return;
}
if(vertex.vertexs == null)
vertex.vertexs = new Vertex[26+10];
if (null == vertex.vertexs[index]) {
vertex.vertexs[index] = new Vertex();
}
vertex.prefixCount++;
addWord(vertex.vertexs[index], word.substring(i+1));
}
}
/**
* 统计某个单词出现次数
*
* @param word 单词
* @return 出现次数
*/
public synchronized int countWord(String word) {
return countWord(root, word.toLowerCase());
}
/**
* 统计某个单词出现次数
*
* @param root 单词查找树节点
* @param word 单词
* @return 出现次数
*/
private int countWord(Vertex vertex, String word) {
if (word.length() == 0) {
return vertex.wordCount;
} else {
int index = -1, i=0;
try{
for(;(index = getIndex(word.charAt(i)))==-1;i++){}
}catch(IndexOutOfBoundsException e){
return vertex.wordCount;
}
if (vertex.vertexs == null
|| null == vertex.vertexs[index]) {
return 0;
} else {
return countWord(vertex.vertexs[index], word.substring(i+1));
}
}
}
/**
* 调用深度递归算法得到所有单词,用于测试
* @return 单词集合
*/
private List<String> listAllWords() {
List<String> allWords = new ArrayList<String>();
return depthSearchWords(allWords, root, "");
}
/**
* 递归生成所有单词
* @param allWords 单词集合
* @param vertex 单词查找树的节点
* @param wordSegment 单词片段
* @return 单词集合
*/
private List<String> depthSearchWords(List<String> allWords, Vertex vertex,
String wordSegment) {
if(vertex.vertexs == null)
return allWords;
Vertex[] vertexs = vertex.vertexs;
for (int i = 0; i < vertexs.length; i++) {
if (null != vertexs[i]) {
if (vertexs[i].wordCount > 0) {
allWords.add(wordSegment + buildChar(i));
if(vertexs[i].prefixCount > 0){
depthSearchWords(allWords, vertexs[i], wordSegment + buildChar(i));
}
} else {
depthSearchWords(allWords, vertexs[i], wordSegment + buildChar(i));
}
}
}
return allWords;
}
private int getIndex(char c){
int index = -1;
if(c>='a' && c<='z')
index = c - 'a';
else if(c>='0' && c<='9')
index = c - '0' + 26;
return index;
}
/**
* 返回对应的char,需要保证index正确
* @param index
* @return
*/
private char buildChar(int index){
if(index>=0 && index<26){
return (char)(index + 'a');
}else{
return (char)(index-26 + '0');
}
}
}
?
?
这是参考网上的代码的实现,有个需要注意的地方就是vertexs数组一定要在使用的时候初始化,不然就像我刚改动完这个代码之后第二天发现只比方法1多出几倍的网页。
?
4. Bloom Filter
第一次接触Bloom Filter,但感觉到了它的美妙,今天跑半天的网页量占据的内存空间就足够支持整站的存储,但需要提前预估和计算m、n、k的大小来解决错误率问题,上一中字典树的方式只是理论上存在错误的可能,但实际使用过程中没有这种问题出现。
具体原理和参数计算这有篇很好的文章
http://blog.csdn.net/jiaomeng/article/details/1495500
既然是学习的,具体实现肯定仍旧是参考网上的代码。但是通过Java自带的BitSet管理位图就会遇到问题了,因为boolean占用一个bit仅仅是java虚拟机标准里面的规定,hotspot的boolean是占用一个字节的,也就是白白浪费了很多字节,当申请的空间较大的时候这是很严重的浪费。因此需要自己实现一个Bitmap,这也比较简单,另外不同hash可以通过简单的种子不同来区分。
附上代码
?
public class BloomFilter{
// BitMap 的大小,如果利用Java自带的BitSet则由于boolean在hotspot虚拟机下是占用一个字节的原因无法设置很大。
private static final int DEFAULT_SIZE = 1<<28;
// 不同哈希函数的种子,一般应取质数
private static final int[] seeds = new int[] {
2, 5, 7, 11, 13, 23, 31, 37, 41, 47, 61, 71, 89};
private BitMap bits = new BitMap(DEFAULT_SIZE);
// 哈希函数对象
private SimpleHash[] func =new SimpleHash[seeds.length];
public BloomFilter(){
for (int i =0; i < seeds.length; i++){
func[i] =new SimpleHash(DEFAULT_SIZE, seeds[i]);
}
}
/**
* 将字符串标记到bits中
* @param value
*/
public synchronized void add(String value){
for (SimpleHash f : func){
bits.set(f.hash(value));
}
}
/**
* 判断字符串是否已经被bits标记
* @param value
* @return
*/
public synchronized boolean contains(String value){
if (value == null){
return false;
}
boolean ret =true;
for (SimpleHash f : func){
ret = ret && bits.get(f.hash(value))==0?false:true;
}
return ret;
}
/**
* 哈希函数类
* @author admin
*/
public static class SimpleHash {
private int cap;
private int seed;
public SimpleHash(int cap, int seed){
this.cap = cap;
this.seed = seed;
}
/**
* hash函数,采用简单的加权和hash
* @param value
* @return
*/
public int hash(String value){
int result =0;
int len = value.length();
for (int i =0; i < len; i++){
result = seed * result + value.charAt(i);
}
return (cap -1) & result;
}
}
public static class BitMap{
private final int INT_BITS = 32;
private final int SHIFT = 5 ;// 2^5=32?
private final int MASK = 0x1f; // 2^5=32
int bitmap[];
public BitMap(int size){
bitmap = new int[size/INT_BITS];
}
/**
* 设置第i位
* i >> SHIFT 相当于 i / (2 ^ SHIFT),
* i&MASK相当于mod操作 m mod n 运算
* @param i
*/
void set(int i) {
bitmap[i >> SHIFT] |= 1 << (i & MASK);
}
/**
* 获取第i位
* @param i
* @return
*/
int get(int i) {
return bitmap[i >> SHIFT] & (1 << (i & MASK));
}
/**
* 清除第i位
* @param i
* @return
*/
int clear(int i) {
return bitmap[i >> SHIFT] & ~(1 << (i & MASK));
}
}
}
?
?
5. BerkeleyDB
Heritrix的实现方式,这里就不多说了,因为BerkeleyDB支持Key-value的方式,而且与程序在同一进程空间执行,因此是个不错的选择。但是相比于之前的而言,将查重工作放在磁盘上做当然是在内存不够使用的时候才采用,注:对于JD、Amazon这样的电商网站规模是不需要采用这种方式的,所以预计单站爬虫查重操作不需要移到外存。另外如果有并行需求,只要量不大,在服务器上3、4两种方法一般都是可以满足的。
6. DB
普通数据库就不细了,单站可以采取sqlite加快查重速度,但如果避免数据重复读写等采用DB也是可选的方案,但是时间开销确实增加较多。
?
就不做总结陈词了,以上这些方案足够普通的爬虫需要了,但像搜索引擎这种肯定还有很多改善的方案。
?