关于数据库的逻辑设计,是一个很广泛的问题。本文主要针对开发应用中遇到在MS SQL Server上进行表设计时,对表的主键设计应注意的问题以及相应的解决办法。
主键设计现状和问题
关于数据库表的主键设计,一般而言,是根据业务需求情况,以业务逻辑为基础,形成主键。
比如,销售时要记录销售情况,一般需要两个表,一个是销售单的概要描述,记录诸如销售单号、总金额一类的情况,另外一个表记录每种商品的数量和金额。对于第一个表(主表),通常我们以单据号为主键;对于商品销售的明细表(从表),我们就需要将主表的单据号也放入到商品的明细表中,使其关联起来形成主从关系。同时该单据号与商品的编码一起,形成明细表的联合主键。这只是一般情况,我们稍微将这个问题延伸一下:假如在明细中,我们每种商品又可能以不同的价格方式销售。有部分按折扣价格销售,有部分按正常价格销售。要记录这些情况,那么我们就需要第三个表。而这第三个表的主键就需要第一个表的单据号以及第二个表的商品号再加上自身需要的信息一起构成联合主键;又或者其他情况,在第一个主表中,本身就是以联合方式构成联合主键,那么也需要在从表中将主表的多个字段添加进来联合在一起形成自己的主键。
数据冗余存储:随着这种主从关系的延伸,数据库中需要重复存储的数据将变得越来越庞大。或者当主表本身就是联合主键时,就必须在从表中将所有的字段重新存储一次。
SQL复杂度增加:当存在多个字段的联合主键时,我们需要将主表的多个字段与子表的多个字段关联以获取满足某些条件的所有详细情况记录。
程序复杂度增加:可能需要传递多个参数。
效率降低:数据库系统需要判断更多的条件,SQL语句长度增加。同时,联合主键自动生成联合索引
WEB分页困难:由于是联合主键方式(对于多数的子表),那么在WEB页面上要进行分页处理时,在自关联时,难于处理。
解决方案
从上面,我们已经看到现有结构存在着相当多的弊端,主要是导致程序复杂、效率降低并且不利于分页。
为解决上述问题,本文提出:当应用系统后台数据库表间存在主从关系时,数据库表额外增加一非业务字段作为主键,该字段为数值型;或者当该表需要在应用中进行分页查询时,也应考虑如此设计。一般地,我们也可以几乎为任何表增加一个与业务逻辑无关的字段作为该表的主键字段。
由于该字段要作为表的主键,那么其首要条件是要保证在该表中要具有唯一性。同时,结合SQL Server数据库自身的特性,可以为其建立一个自增列:
以下为引用的内容:
create TABLE T_PK_DEMO
(
U_ID BIGINT NOT NULL IDENTITY(1,1),
--唯一标识记录的ID
COL_OTHER VARchar(20) NOT NULL ,
--其他列
CONSTRAINT PK_T_PK_DEMO PRIMARY KEY NONCLUSTERED
(U_ID)--定义为主键
)
但是,SQL Server中的自增列却存在一个比较尴尬的事实,那就是该字段一旦定义和使用,用户无法直接干预该字段的值,完全由数据库系统自身控制:
完全数据库系统控制,用户无法修改值
在数据库的发布和订阅时,使用自增列会比较麻烦
恢复部分数据时,使用自增列会比较麻烦
该列的值必须在插入数据后才能获取
鉴于此,建议不以自增列的方式来定义,而是参考Oracle数据库系统中序列,在SQL Server系统中实现类似Oracle数据库系统序列功能。这个具体在下面的小节中介绍。我们只需要按照普通字段的定义方式修改表定义为:
以下为引用的内容:
create TABLE T_PK_DEMO
(
U_ID BIGINT NOT NULL ,--唯一标识记录的ID
COL_OTHER VARchar(20) NOT NULL ,--其他列
CONSTRAINT PK_T_PK_DEMO PRIMARY KEY NONCLUSTERED (U_ID)--定义为主键
)
参照Oracle序列的功能,我们需要在SQL Server数据库中创建一个新表,以管理序列值:
以下为引用的内容:
create TABLE T_DB_SEQ
(
SEQ_NAMEVARchar(50) NOT NULL ,--序列名称
SEQ_OWNER VARchar(50) NOT NULL DEFAULT ’DBO’,
--序列所有者(SYSTEM_USER)
SEQ_CURRENT BIGINT NOT NULL DEFAULT 0,--序列当前值
SEQ_MIN BIGINT NOT NULL DEFAULT 0,--序列最小值
SEQ_MAX BIGINT NOT NULL DEFAULT 0,--序列最小值
SEQ_MAX BIGINT NOT NULL DEFAULT 0,--序列最大值
SEQ_STEPINT NOT NULL DEFAULT 1,--序列增长步长
IF_CYCLEINT NOT NULL DEFAULT 0,--是否循环(0,不循环;1,循环)
CONSTRAINT T_DB_SEQ PRIMARY KEY CLUSTERED
(SEQ_NAME,SEQ_OWNER)--主键
)
应用系统为需要创建自增列的表创建一个序列名称,在表“T_DB_SEQ”中反映为数据库中的一行。
12 3 下一页 IDC123.COM
第一,需要为需要建立序列的表创建一个序列。采用方法:F_create_SEQ(序列名)。该函数传入序列的名称,在表“T_DB_SEQ”插入一行。序列的所有者,采用系统变量SYSTEM_USER。
第二,获取下一个值。采用方法:F_GET_NEXT_SEQ_VAL(序列名)。该函数根据序列名获取该序列的下一个值,根据当前值与增长步长得到。同时,该函数保证在同时获取同一个序列时,应保证并发一致性。
第三、将返回值返回到应用使用。
此外,为保证应用的完整性,可能还需要提供一些方法的重载方法,同时提供一些其他方法:
获取序列当前值:F_GET_SEQ_CUR_VAL(序列名)
设置序列值:F_SET_SEQ_VAL(序列名)
删除序列:F_DEL_SEQ(序列名)
判断序列是否存在:F_SEQ_exists(序列名)
在主从关系的表设计中,子表也使用序列字段作为唯一主键,将父表的序列字段作为外键关联:
以下为引用的内容:
create TABLE T_PK_DEMO_C
(
U_ID BIGINT NOT NULL ,--唯一标识记录的ID
COL_OTHER VARchar(20) NOT NULL ,--其他列
P_ID INT NOT NULL ,--父表ID
CONSTRAINT PK_T_PK_DEMO_C PRIMARY KEY
NONCLUSTERED (U_ID)--定义为主键
CONSTRAINT FK_T_PK_DEMO_C FOREIGN KEY (P_ID)
REFERENCES T_PK_DEMO(U_ID) ON delete CASCADE,
)
使用序列的问题及解决办法
由于系统使用一个额外增加一个字段作为主键,因此没有为业务逻辑建立主键约束。比如在企业用户信息表中,要求企业中用户登录名必须唯一。一般在创建表时,以登录名作为主键,这个时候在数据库层自然的创建另一个主键唯一性约束。而现在没有使用登录名作为主键,那么就没有这个约束。解决办法:
一是在数据库层解决。可以为该表创建一个唯一(UNIQUE)约束或者唯一索引。如:
alter TABLE T_PK_DEMO ADD CONSTRAINT C_T_PK_DEMO UNIQUE NONCLUSTERED(COL_OTHER)-唯一约束
create UNIQUE INDEX IX_T_PK_DEMO ON T_PK_DEMO(COL_OTHER) – 唯一索引
二是在应用端解决。也就是在应用中判断该列是否有重复值,然后根据判断结果来保证唯一性。
我们注意到,在之前的例子中,主键采用了NONCLUSTERED(非聚蔟)的索引方式。关于如何设计索引,不是本文的重点,在这里仅提供一个建立索引时采用聚蔟方式还是非聚蔟方式的一个一般原则:
作为非业务字段的主键列,是一个没有重复值的、基本不进行更新操作的列。并且,在SQL Server数据库中,聚蔟索引在一个表中只能有一个。因此,聚蔟索引非常重要,需要留给更重要的字段来使用。因此,对照上表和根据聚蔟索引的重要程度,在此处采用非聚蔟方式创建其索引。
IDC123.COM
具体应用
采用这种主键设计方式,有诸多好处,这已经在前文说明。现在就以一个具体的应用来说明如何使用这个主键。
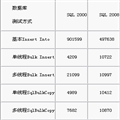
当前的应用系统基本上都已经采用B/S方式,尽管现在的网络速度已经有大幅度的提高,但是由于在WEB应用上用户数量众多、同时基本上所有的运算都集中在WEB应用服务器上,所以在WEB设计上更要考虑到性能的优化,以减少网络流量和对服务器的压力。最常见的一个应用就是列表方式展现时的分页方式。一般的,在数据量小的情况下,一般不会怎么注意这个问题,通常采用将数据完全取出,然后在WEB服务器上进行分页。但是,当数据量庞大时,这种方式就会导致速度降低,甚至根本不可用。所以,一般采用存储过程,在数据库端进行分页。