Hiphop��Facebook����һ��PHP����������һ�����ߣ��ʼ����phpתΪC++�����Ǻ�����������Ϊc++�Ļ��������ʱ��Ứ���ڱ���������棬���Բ����㣬���ڴ�����˵Ҳ���Ǽ��������á�
����hiphop��������ô�����Σ�
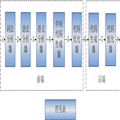
HPHPC=>HPHPI=>HHVM
HPHPC�Ǿ�̬���룬Ҳ���ǰ�phpתΪc++
HPHPI��һ�����ɲ�Ʒ������php zend����������ܻ�����zend����������ǿ������в鿴Ч����
HHVM����HPHPI�����ϣ�Ӧ����JIT�����������Ѿ��ӽ���HPHPC,Ŀǰfacebook������������HPHPC��
������HPHPC��HHVM��zend�����+������Ҫ��Լcpu��50%��300%�䣨�ٷ��ṩ������ʵ��Ӧ���У�һ���ԼCPU��100%-300%�����ң�����Խ��Խ���ԡ�
Ŀǰ����ʹ�õ�HHVM���������ȷ���HPHPC��HPHPC����������Hiphop������ԭ����HHVM���Խ�һ�����������ԭ�����������������HHVM�����Ǹ���������Ŀ��
?
��HPHP2.0��ǰ��HIPHOP������ͨ����̬�������б���������������������������ȣ�HPHP2.0�Ժ�̬���Ѿ�ȡ���ˡ�
?
��Ŀǰ��������HPHPC�Ĺ��̣�HHVM�Ժ��һ��ٷ�����
ԭ������һ������ԭ��+�������������
ԭ����������hiphop�ʷ���������������������1
ԭ����������hiphop��������������2
ԭ�������ģ�hiphop��Ƶ����Ż�����
ԭ�������壺hiphop?���������server����
?
���ڿ�ʼ������һ�ڣ�����ԭ��+�ʷ������
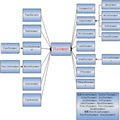
1.??????����ԭ������
1.1??�������ṹ
1.2? hiphop?�������ṹ
1.3??�ʷ�������
1.4??�������
1.5??���������
1.6??����������
1.7??�����Ż���
1.8??����������
2.hiphop?����ԭ������
???????? 2.1hiphop?���봦������
? ? ? ? ?2.2 hiphop?�ʷ�����
? ? ? ? ?2.3 hiphop?�����
?
Ҫ����ϤHPHP������Ҫ�Ա���ԭ����һ�����˽⣬�ſ�����Ϥhiphop��ԭ����
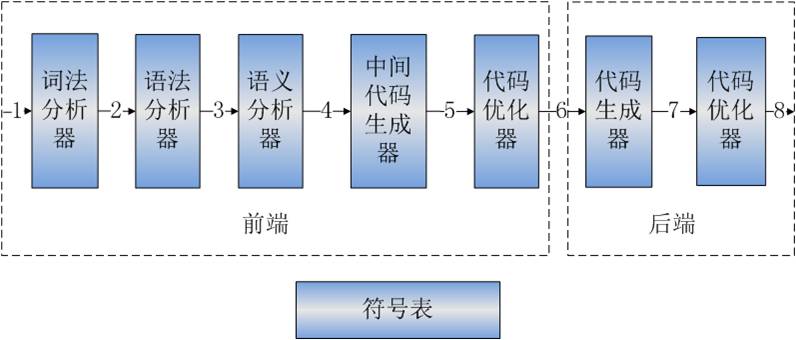
1.�ַ���
2.����Token
3.�������
4.��Ƶ����룬���ɳ������������������Ϣ�浽���ű���
5.ͨ���������������ַ���������м���ʽ����
6.���м���ʽ��������Ż�
7.����Ŀ�������
8.Ŀ��������ڽ��д����Ż�����Ŀ�������
?
����a=b+c*60
�ʷ�������
���ȣ����������ʽ���ɲ�ͬ�Ĵʣ��������Ͳ�⣬Ȼ���ע��ID
<float,1> < equal ,2> <float,3> < add ,4> <float ,5> < mul,6> <int,7>
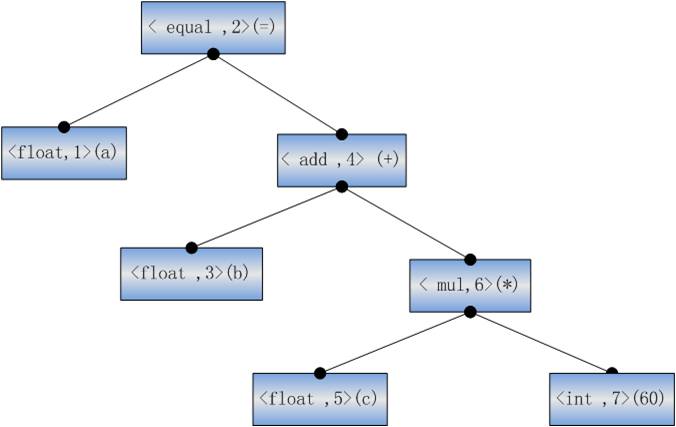
�������
?
���ォ�������ʽ���Ϊһ������������������ID�������Ҷ���У���ע�˾���IJ��Ĵʣ�������һ�������
�������:
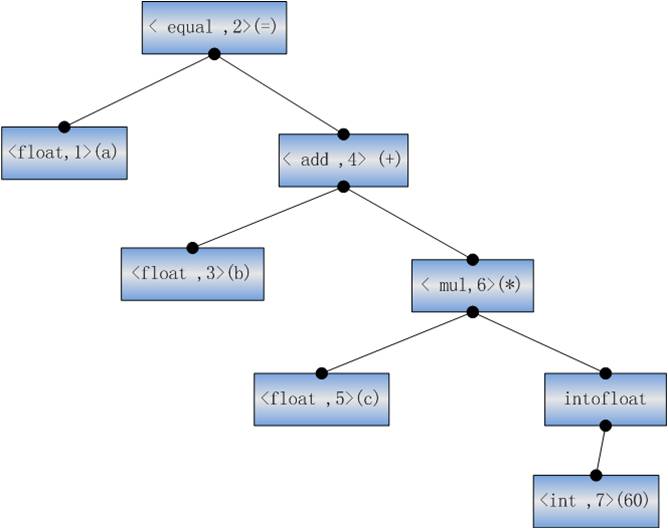
����һ�������������hphp�лḴ�ӵĶ࣬��c��һ��float��60��һ��int���������ォ60ת��Ϊfloat���������岻������ô��
?
�м�������ɣ�
�м�������ɣ������������Ȼ�����ɸ��м���룬��HPHPC��������C++?�����м���룬�����һ��С���������������Ͻ����������γ�һ���м����Σ�
?????????t1=intfloat(60)
? ? ? ? t2=float3*t1
? ? ? ? t3=float2+t2
? ? ? ? float1=t3
�����Ż�����
?????????�γ��м�����Ȼ����Խ�һЩ���Ժϲ����Ż��Ĵ����������Ż�����������ܣ���HPHP�ͷ�Ϊpreoptimizer��postoptimizer���ڴ����Ƶ�ǰ��ֱ����һ���Ż�����ʵ��̬����ֻ�����˱�������ǰһ���ֶ��ѣ�
? ? ?t1=float3*60.0
? ? ?float1=float2+t1
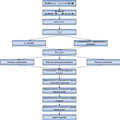
����������:
���ɻ�����
�����HPHPC����Ļ�����ô�������ɻ������HHVM�������ɻ����룬��������һ���������ڲ����Լ���һ�����ƻ���һ���������
?
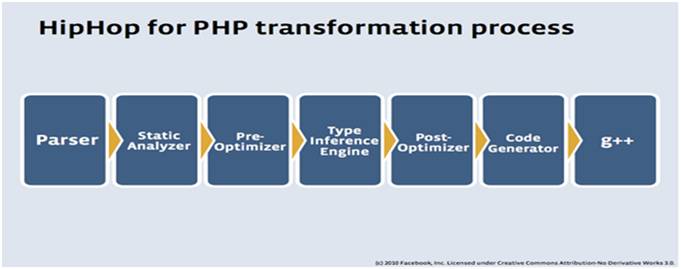
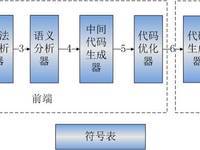
ǰ�ˣ�
Parser?���ʷ��������
Static Analyzer:?��Ƶ����룬���ɳ�����������������
Type Inference Engine:?�������
Pre-optimizer,Post-optimizer�������Ż�����
Code generate:�м�������ɲ���
��ˣ�
G++
?
�ʷ�������Ҫ�ǽ��л��ִʷ�Ԫ�ص�Ԫ��token)���ʷ���Ԫ��ʽ��<token-name,attribute-value>
һ��ʷ������ζ���ͨ���������������л��ִʷ���Ԫ
һ��ʷ�������ʹ��lex���߽��з���
����?a=b+c*60
���ִʷ���Ԫ��
a :<float,1>
= : < equal ,2>
b : <float ,3>
+ : < add ,4>
c : <float ,5>
* : < mul,6>
60 : <int,7>
?
��������������ǴӴʷ�������ȡһ���ɴʷ���Ԫ��ɵĴ������ܹ������ͻָ����е��������������������֣�Ȼ�����һ������������������ṩ���������������ֽ�����һ��������
1.4.1?����ķ�
1.4.2?�Զ����µ������
1.4.3?�Ե����ϵ������
?
��1���ʷ�Ϊ��ʹ���������ʽ��
��ṹ��Ϊ�ʷ��ͷǴʷ����㽲������ǰ��ģ�黯
�ʷ��Ƚϼ���Ҫ�������ǿ���ܽ�����������
�����ȣ��������ʽ�ṩ�˸��Ӽ������������ı�ʾ�ʷ���Ԫ�ķ���
�������ʽ�Զ�����õ��Ĵʷ�������Ч��Ҫ���ڸ��������ķ��Զ�����õ��ķ�����
��2���ʷ�����
�������ʽ�ʺ����������ʾ�����������ؼ������հ����������Խṹ
��3�������
�ķ��ʺ�����Ƕ�ṹ������Գ����Ŷԣ���Ե�beigin-end�������Ӧ��if-then-else,��ЩǶ�ṹ����ʹ���������ʽ������
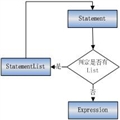
�ķ�Stmt?if expr then stmt
???????? ????????????| if expr then stmt else stmt
???????????????????? | other
����������䣺if E1 then S1else if E2 then S2 else S3
?
ע��
���ߺ���չ����statement,��С����expression
�˴���else�������ֽ��ͣ�
��?if? E1?????????????????????????????????????????��?if? E1
??????? then S1????????????????????????????????????????? thenS1
else? ??????????????????????????????????????????????????????????????????????????????????????????????????????????????????????
if E2??????????????????????????????????? ??????????????????? ??else?
if E2??????????
?????????? ? ?then S2???????????????????????????????????????? thenS2
??? else??????????????????????? ??????????????????????????????else
??????? then S3????????????????????????????????????????????????then S3
?
������������if?��else��?û��else if��������ɵڶ���else��֪���Ǻ͵�һ��ifƥ�仹�Ǻ͵ڶ���ifƥ����
expr?expr+term
�����Ļ���expr�ͻ��������ѭ����
expr? expr+term+term
expr?expr+term+term+term
expr?expr+term+term+����+term
������û���ս��ˣ�����һ���дΪ��
expr?expr+term|term
�������ҵ��ս��termʱ�����Ͳ����ٽ��еݹ��ˣ���������������ݹ�
һ���ķ�ת���������ɲ����������Զ����·������ķ���
��?stmt��if exprthen stmt?else stmt
???????????? | if expr then stmt
������ifʱ��֪��ѡ���ĸ�����ʽչ��stmt��
A?a?? |a��2��A����������ʽ�����Ƿǿմ�����ʱ���ǽ�Aչ��Ϊ��A��?�Ӷ����������ӡ��ڶ�������Ƶ����ھ�����A��չ��Ϊ1����2�������ȡ������ԭ������ʽ��Ϊ
A����A��
A������1|��2
?
�ٸ�������˵��
����
If a==1 then b=1
��ô��ʱ��Ҫѡ�����ʽ��ѡ��ifexpr then stmt?����if expr then stmt?else stmt
��ô����ô�Ƶ�
����if expr then stmt
A =>if expr then stmt?A��
?????????A��=>|?else stmt
??????????????????
Number
Expr :Number|
Expr+Expr|
Expr �C Expr|
Expr * Expr|
Expr / Expr;
����˵���Ǵ���������Ҷ
?
�磺���ǽ���1+2/3+4*6-3-2������ַ��ƽ���ջ��������ʾ��
?????????? .1+2/3+4*6-3????
???????? E= num?��Լa 0
E = E / E?��Լb 1
E = E * E?��Լc 1
E = E + E?��Լd 2
E = E - E?��Լe 2?
=================================================
??? 1?????1.+2/3+4*6-3?????�ƽ�
??? 2?????E.+2/3+4*6-3?????��Լa
??? 3?????E+.2/3+4*6-3?????�ƽ�
??? 4?????E+2./3+4*6-3?????�ƽ�
??? 5?????E+E./3+4*6-3?????��Լa
??? 6?????E+E/.3+4*6-3?????�ƽ�
??? 7????? E+E/3.+4*6-3????�ƽ�
??? 8?????E+E/E.+4*6-3?????��Լa
??? 9?????E+E/E+.4*6-3?????�ƽ�
??? 10????E+E/E+4.*6-3?????�ƽ�
??? 11????E+E/E+E.*6-3?????��Լa
???12????E+E/E+E*.6-3?????�ƽ�
??? 13????E+E/E+E*6.-3?????�ƽ�
??? 14????E+E/E+E*E.-3?????��Լa
??? 15???? E+E/E+E*E-.3????�ƽ�
??? 16????E+E/E+E*E-3.?????�ƽ�
??? 17????E+E/E+E*E-E.?????��Լa???
??? 18????E+E+E*E-E.???????��Լb
??? 19????E+E+E-E.?????????��Լc?
??? 20????E+E-E.???????????��Լd
??? 21????E-E.?????????????��Լd
??? 22????E.??????????????��Լe
?
���������ʹ������ͷ��ű��е���Ϣ�����Դ�����Ƿ�����Զ��������һ�¡�ͬʱҲ�ռ�������Ϣ��������Щ��Ϣ�ŵ��������ű��С�
���������Ҫ���֣����ͼ��ͳ��������
���ͼ������������ͼ�����
?????????????????????????????������ת����
?????????????????????????????�ۺ����������������
?????????????????????????????�������Ƶ��Ͷ�̬������
���������
�磺����ʽ: 9-5+2
���������
9-5+2
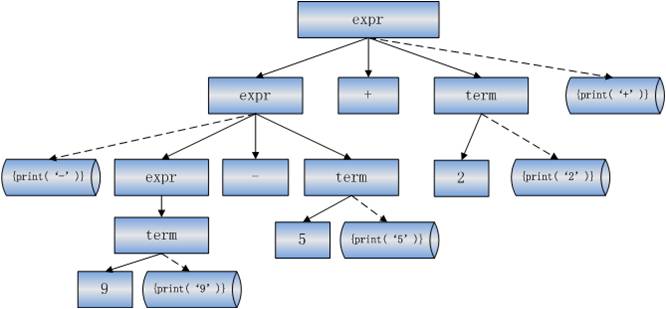
?
ʵ���dz������
���ߴ������������
?
??????�м������ö��ַ�ʽ��ʾ�����������������ַ���룬���г��������ʽ�ܹ��Խṹ����б�����������ַ��ʽ���ܽ��п�����������Ľ������顣
??????���������
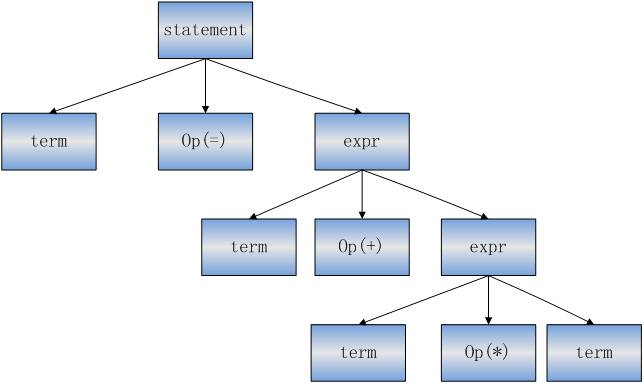
?
?
?
��??����ַ���룺������������(x=y op z)
�磺x+y*z���������ַָ������t1= y*z?? t2=x+t1???? (t1��t2Ϊ��ʱ����)
a=b*-c+b*-c������ַ��������
t1=-c
t2=b*t1
t3=-c
t4=b*t3
t5=t2+t4
a=t5
If??x goto y
?
?
1.7�����Ż���
?????????�����Ż����Ƕ��м��������Ż�ʹ�����ɸ��ٵ�ָ������ַ������ټ��ٿ���ָ�����Ŀ���ڳ�ֿ��������ĵ���������������ָ��ʱ�ͼ������ɵ�ָ��
?
1.8?����������
????????����Ŀ�������
?
���
��ľ�ϵ�yacc��lex�̳̣�
http://blog.csdn.net/liwei_cmg/article/details/1530492
����ԭ������2�棩?????����������������
?
��һ�ڣ�hiphopԭ������1��2����hiphop?����ԭ��������
?

 class='magplus' title='����鿴ԭʼ��СͼƬ' />
class='magplus' title='����鿴ԭʼ��СͼƬ' />