����õ��ˣ�������Ȼ��ת��
ArrayList ��Vector�Dz������鷽ʽ�洢���ݣ�������Ԫ��������ʵ�ʴ洢�������Ա����ӺͲ���Ԫ�أ�������ֱ���������Ԫ�أ����Dz�������Ҫ��Ƶ�����Ԫ���ƶ����ڴ������������������ݿ������������Vector����ʹ����synchronized�������߳���ȫ�����������ϱ�ArrayListҪ�LinkedListʹ��˫������ʵ�ִ洢�����������������Ҫ������ǰ�������������Dz�������ʱֻ��Ҫ��¼�����ǰ����ɣ����Բ������ȽϿ죡
���Ա�����������ϣ���dz��õ����ݽṹ���ڽ���Java����ʱ��JDK�Ѿ�Ϊ�����ṩ��һϵ����Ӧ������ʵ�ֻ��������ݽṹ����Щ�����java.util���С�������ͼͨ��������������߲���������������Լ������ȷʹ����Щ�ࡣ?
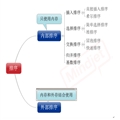
Collection
��List
����LinkedList
����ArrayList
����Vector
������Stack
��Set
Map
��Hashtable
��HashMap
��WeakHashMap
Collection�ӿ�
����Collection��������ļ��Ͻӿڣ�һ��Collection����һ��Object����Collection��Ԫ�أ�Elements����һЩCollection������ͬ��Ԫ�ض���һЩ���С�һЩ���������һЩ���С�Java?SDK���ṩֱ�Ӽ̳���Collection���࣬Java?SDK�ṩ����Ǽ̳���Collection�ġ��ӽӿڡ���List��Set��
��������ʵ��Collection�ӿڵ�������ṩ�����������캯���������Ĺ��캯�����ڴ���һ���յ�Collection����һ��Collection�����Ĺ��캯�����ڴ���һ���µ�Collection������µ�Collection�봫���Collection����ͬ��Ԫ�ء���һ�����캯�������û�����һ��Collection��
������α���Collection�е�ÿһ��Ԫ�أ�����Collection��ʵ��������Σ�����֧��һ��iterator()�ķ������÷�������һ�������ӣ�ʹ�øõ����Ӽ�����һ����Collection��ÿһ��Ԫ�ء����͵��÷����£�
��������Iterator?it?=?collection.iterator();?//?���һ��������
��������while(it.hasNext())?{
������������Object?obj?=?it.next();?//?�õ���һ��Ԫ��
��������}
������Collection�ӿ������������ӿ���List��Set��
List�ӿ�
����List�������Collection��ʹ�ô˽ӿ��ܹ���ȷ�Ŀ���ÿ��Ԫ�ز����λ�á��û��ܹ�ʹ��������Ԫ����List�е�λ�ã������������±꣩������List�е�Ԫ�أ���������Java�����顣
������Ҫ�ᵽ��Set��ͬ��List��������ͬ��Ԫ�ء�
�������˾���Collection�ӿڱر���iterator()�����⣬List���ṩһ��listIterator()����������һ��ListIterator�ӿڣ��ͱ���Iterator�ӿ���ȣ�ListIterator����һЩadd()֮��ķ������������ӣ�ɾ�����趨Ԫ�أ�������ǰ����������
����ʵ��List�ӿڵij�������LinkedList��ArrayList��Vector��Stack��
LinkedList��
����LinkedListʵ����List�ӿڣ�����nullԪ�ء�����LinkedList�ṩ�����get��remove��insert������LinkedList���ײ���β������Щ����ʹLinkedList�ɱ�������ջ��stack����������queue����˫����У�deque����
����ע��LinkedListû��ͬ���������������߳�ͬʱ����һ��List��������Լ�ʵ�ַ���ͬ����һ������������ڴ���Listʱ����һ��ͬ����List��
��������List?list?=?Collections.synchronizedList(new?LinkedList(...));
ArrayList��
����ArrayListʵ���˿ɱ��С�����顣����������Ԫ�أ�����null��ArrayListû��ͬ����
size��isEmpty��get��set��������ʱ��Ϊ����������add��������Ϊ��̯�ij���������n��Ԫ����ҪO(n)��ʱ�䡣�����ķ�������ʱ��Ϊ���ԡ�
����ÿ��ArrayListʵ������һ��������Capacity���������ڴ洢Ԫ�ص�����Ĵ�С��������������Ų���������Ԫ�ض��Զ����ӣ����������㷨��û�ж��塣����Ҫ�������Ԫ��ʱ���ڲ���ǰ���Ե���ensureCapacity����������ArrayList����������߲���Ч�ʡ�
������LinkedListһ����ArrayListҲ�Ƿ�ͬ���ģ�unsynchronized����
Vector��
����Vector�dz�����ArrayList������Vector��ͬ���ġ���Vector������Iterator����Ȼ��ArrayList������Iterator��ͬһ�ӿڣ����ǣ���ΪVector��ͬ���ģ���һ��Iterator�������������ڱ�ʹ�ã���һ���̸߳ı���Vector��״̬�����磬���ӻ�ɾ����һЩԪ�أ�����ʱ����Iterator�ķ���ʱ���׳�ConcurrentModificationException����˱��벶����쳣��
Stack?��
����Stack�̳���Vector��ʵ��һ������ȳ��Ķ�ջ��Stack�ṩ5������ķ���ʹ��Vector���Ա�������ջʹ�á�������push��pop����������peek�����õ�ջ����Ԫ�أ�empty�������Զ�ջ�Ƿ�Ϊ�գ�search�������һ��Ԫ���ڶ�ջ�е�λ�á�Stack�մ������ǿ�ջ��
Set�ӿ�
����Set��һ�ֲ������ظ���Ԫ�ص�Collection�������������Ԫ��e1��e2����e1.equals(e2)=false��Set�����һ��nullԪ�ء�
���������ԣ�Set�Ĺ��캯����һ��Լ�������������Collection�������ܰ����ظ���Ԫ�ء�
������ע�⣺����С�IJ����ɱ����Mutable?Object�������һ��Set�еĿɱ�Ԫ�ظı�������״̬����Object.equals(Object)=true������һЩ������
Map�ӿ�
������ע�⣬Mapû�м̳�Collection�ӿڣ�Map�ṩkey��value��ӳ�䡣һ��Map�в��ܰ�����ͬ��key��ÿ��keyֻ��ӳ��һ��value��Map�ӿ��ṩ3�ּ��ϵ���ͼ��Map�����ݿ��Ա�����һ��key���ϣ�һ��value���ϣ�����һ��key-valueӳ�䡣
Hashtable��
����Hashtable�̳�Map�ӿڣ�ʵ��һ��key-valueӳ��Ĺ�ϣ�����κηǿգ�non-null���Ķ�����Ϊkey����value��
������������ʹ��put(key,?value)��ȡ������ʹ��get(key)������������������ʱ�俪��Ϊ������
Hashtableͨ��initial?capacity��load?factor���������������ܡ�ͨ��ȱʡ��load?factor?0.75�Ϻõ�ʵ����ʱ��Ϳռ�ľ��⡣����load?factor���Խ�ʡ�ռ䵫��Ӧ�IJ���ʱ�佫�������Ӱ����get��put�����IJ�����
ʹ��Hashtable�ļ�ʾ�����£���1��2��3�ŵ�Hashtable�У�������key�ֱ��ǡ�one������two������three����
��������Hashtable?numbers?=?new?Hashtable();
��������numbers.put(��one��,?new?Integer(1));
��������numbers.put(��two��,?new?Integer(2));
��������numbers.put(��three��,?new?Integer(3));
����Ҫȡ��һ����������2������Ӧ��key��
��������Integer?n?=?(Integer)numbers.get(��two��);
��������System.out.println(��two?=?��?+?n);
����������Ϊkey�Ķ���ͨ��������ɢ�к�����ȷ����֮��Ӧ��value��λ�ã�����κ���Ϊkey�Ķ�����ʵ��hashCode��equals������hashCode��equals�����̳��Ը���Object����������Զ������൱��key�Ļ���Ҫ�൱С�ģ�����ɢ�к����Ķ��壬�������������ͬ����obj1.equals(obj2)=true�������ǵ�hashCode������ͬ���������������ͬ�������ǵ�hashCode��һ����ͬ�����������ͬ�����hashCode��ͬ�����������Ϊ��ͻ����ͻ�ᵼ�²�����ϣ����ʱ�俪���������Ծ�������õ�hashCode()�������ܼӿ��ϣ���IJ�����
���������ͬ�Ķ����в�ͬ��hashCode���Թ�ϣ���IJ�����������벻���Ľ�����ڴ���get��������null����Ҫ�����������⣬ֻ��Ҫ�μ�һ����Ҫͬʱ��дequals������hashCode����������Ҫֻд����һ����
����Hashtable��ͬ���ġ�
HashMap��
����HashMap��Hashtable���ƣ���֮ͬ������HashMap�Ƿ�ͬ���ģ���������null����null?value��null?key�������ǽ�HashMap��ΪCollectionʱ��values()�����ɷ���Collection����������Ӳ���ʱ�俪����HashMap�������ɱ�������ˣ�������������������൱��Ҫ�Ļ�����Ҫ��HashMap�ij�ʼ��������ù��ߣ�����load?factor���͡�
WeakHashMap��
����WeakHashMap��һ�ָĽ���HashMap������keyʵ�С������á������һ��key���ٱ��ⲿ�����ã���ô��key���Ա�GC���ա�
�ܽ�
��������漰����ջ�����еȲ�����Ӧ�ÿ�����List��������Ҫ���ٲ��룬ɾ��Ԫ�أ�Ӧ��ʹ��LinkedList�������Ҫ�����������Ԫ�أ�Ӧ��ʹ��ArrayList��
������������ڵ��̻߳����У����߷��ʽ�����һ���߳��н��У����Ƿ�ͬ�����࣬��Ч�ʽϸߣ��������߳̿���ͬʱ����һ���࣬Ӧ��ʹ��ͬ�����ࡣ
����Ҫ�ر�ע��Թ�ϣ���IJ�������Ϊkey�Ķ���Ҫ��ȷ��дequals��hashCode������
�����������ؽӿڶ���ʵ�ʵ����ͣ��緵��List����ArrayList����������Ժ���Ҫ��ArrayList����LinkedListʱ���ͻ��˴��벻�øı䡣�������Գ����̡�
ͬ����
Vector��ͬ���ġ�������е�һЩ������֤��Vector�еĶ������̰߳�ȫ�ġ���ArrayList�����첽�ģ����ArrayList�еĶ������̰߳�ȫ�ġ���Ϊͬ����Ҫ���Ӱ��ִ�е�Ч�ʣ���������㲻��Ҫ�̰߳�ȫ�ļ�����ôʹ��ArrayList��һ���ܺõ�ѡ���������Ա�������ͬ�������IJ���Ҫ�����ܿ�����
��������
���ڲ�ʵ�ֻ�������ArrayList��Vector����ʹ������(Array)�����Ƽ����еĶ�����������������������Ԫ�ص�ʱ�����Ԫ�ص���Ŀ�������ڲ�����Ŀǰ�ij������Ƕ���Ҫ��չ�ڲ�����ij��ȣ�Vectorȱʡ������Զ�����ԭ��һ�������鳤�ȣ�ArrayList��ԭ����50%,����������õ����������ռ�Ŀռ����DZ���ʵ����Ҫ��Ҫ�����������Ҫ�ڼ����б��������������ôʹ��Vector��һЩ���ƣ���Ϊ�����ͨ�����ü��ϵij�ʼ����С�����ⲻ��Ҫ����Դ������
ʹ��ģʽ
��ArrayList��Vector�У���һ��ָ����λ�ã�ͨ���������������ݻ����ڼ��ϵ�ĩβ���ӡ��Ƴ�һ��Ԫ�������ѵ�ʱ����һ���ģ����ʱ��������O(1)��ʾ�����ǣ�����ڼ��ϵ�����λ�����ӻ��Ƴ�Ԫ����ô���ѵ�ʱ��������������O(n-i)������n����������Ԫ�صĸ�����i����Ԫ�����ӻ��Ƴ�Ԫ�ص�����λ�á�Ϊʲô�������أ���Ϊ�ڽ�������������ʱ���е�i�͵�i��Ԫ��֮�������Ԫ�ض�Ҫִ��λ�ƵIJ�������һ����ζ��ʲô�أ�
����ζ�ţ���ֻ�Dz����ض�λ�õ�Ԫ�ػ�ֻ�ڼ��ϵ�ĩ�����ӡ��Ƴ�Ԫ�أ���ôʹ��Vector��ArrayList�����ԡ����������������������ѡ�������ļ��ϲ����ࡣ���磬LinkList�����������ӻ��Ƴ��������κ�λ�õ�Ԫ�������ѵ�ʱ�䶼��һ����?O(1)������������һ��Ԫ�ص�ʹ��ȱ�Ƚ�����O(i),����i��������λ��.ʹ��ArrayListҲ�����ף���Ϊ����Լ�ʹ�����������洴��iterator����IJ�����LinkListҲ��Ϊÿ�������Ԫ������������������Ҫ������Ҳ���������Ŀ�����
����ڡ�Practical?Java��һ����Peter?Haggar����ʹ��һ�������飨Array��������Vector��ArrayList�������Ƕ���ִ��Ч��Ҫ��ߵij����Ӧ��ˡ���Ϊʹ������(Array)������ͬ��������ķ������úͲ���Ҫ�����·���ռ�IJ�����