?
�����㷨�ܶ�ط������õ������������¿���һ���㷨�����Լ���ʵ����һ�飬�ش˼�¼������Ϊ�Ժ���ϰ������ϡ�
�ϻ�����˵��������һ��������������㷨��
?
1. ѡ������
ѡ������Ļ���˼���DZ�������Ĺ����У��� i ������ǰ��Ҫ�������ţ�����Ҫ��ʣ��� [i��n-1] ���ҳ����е���Сֵ��Ȼ���ҵ�����Сֵ�� i ָ���ֵ���н�������Ϊÿһ��ȷ��Ԫ�صĹ����ж�����һ��ѡ�����ֵ�������̣�������������س�֮Ϊѡ������
�ٸ�ʵ����������
��ʼ�� [38, 17, 16, 16, 7, 31, 39, 32, 2, 11]
i = 0: ?[2 , 17, 16, 16, 7, 31, 39, 32, 38 , 11] (0th [38]<->8th [2])
i = 1: ?[2, 7 , 16, 16, 17 , 31, 39, 32, 38, 11] (1st [38]<->4th [17])
i = 2: ?[2, 7, 11 , 16, 17, 31, 39, 32, 38, 16 ] (2nd [11]<->9th [16])
i = 3: ?[2, 7, 11, 16, 17, 31, 39, 32, 38, 16] ( ���轻�� )
i = 4: ?[2, 7, 11, 16, 16 , 31, 39, 32, 38, 17 ] (4th [17]<->9th [16])
i = 5: ?[2, 7, 11, 16, 16, 17 , 39, 32, 38, 31 ] (5th [31]<->9th [17])
i = 6: ?[2, 7, 11, 16, 16, 17, 31 , 32, 38, 39 ] (6th [39]<->9th [31])
i = 7: ?[2, 7, 11, 16, 16, 17, 31, 32, 38, 39] ( ���轻�� )
i = 8: ?[2, 7, 11, 16, 16, 17, 31, 32, 38, 39] ( ���轻�� )
i = 9: ?[2, 7, 11, 16, 16, 17, 31, 32, 38, 39] ( ���轻�� )
���������Կ�����ѡ��������������Ľ��У� i �������ȽϵĴ�����Խ��Խ�٣����Dz��������ʼ�Ƿ�����ѡ������� i ������ĩβ����һ��ѡ��Ƚϣ����Ը������ȵ����飬ѡ������ıȽϴ����ǹ̶��ģ� 1 + 2 + 3 + ��. + n = n * (n + 1) / 2 ���������Ĵ��������ʼ�����˳���йأ������ʼ����˳��Ϊ��������������£�����Ԫ�ؽ��ύ�� n �Σ���õ����������� 0 �Σ����鱾����Ϊ����
�ɴ˿����Ƴ���ѡ�������ʱ�临�ӶȺͿռ临�Ӷȷֱ�Ϊ O(n2 ) �� O(1) ��ѡ������ֻ��Ҫһ������ռ���������Ԫ�ؽ�������
ʵ�ִ��룺
?
/**
* Selection Sorting
*/
SELECTION(new Sortable() {
public <T extends Comparable<T>> void sort(T[] array, boolean ascend) {
int len = array.length;
for (int i = 0; i < len; i++) {
int selected = i;
for (int j = i + 1; j < len; j++) {
int compare = array[j].compareTo(array[selected]);
if (compare != 0 && compare < 0 == ascend) {
selected = j;
}
}
exchange(array, i, selected);
}
}
})
?
?
2. ��������
��������Ļ���˼�����ڱ�������Ĺ����У���������� i ֮ǰ��Ԫ�ؼ� [0..i-1] ���Ѿ��ź�������Ҫ�ҵ� i ��Ӧ��Ԫ�� x ����ȷλ�� k ��������Ѱ�����λ�� k �Ĺ�����������ȽϹ���Ԫ��������һλ��ΪԪ�� x ����λ�á������ k ��Ӧ��Ԫ��ֵ��Ϊ x ����������Ҳ�Ǹ�������������������ġ�
������һ��ʵ������ɫ ��ǵ�����Ϊ��������֣���������������δ����˴������Ԫ�أ���ɫ ��ǵ������뱻��������֮���Ԫ��Ϊ�������ƶ���Ԫ�أ�����ڶ��˲��������Ԫ��Ϊ [11, 31, 12] ����Ҫ�����Ԫ��Ϊ 12 ������ 12 ��ǰ��û�д�����ȷ��λ�ã�����������Ҫ������ǰ���Ԫ�� 31 �� 11 ���Ƚϣ�һ�߱Ƚ�һ���ƶ��ȽϹ���Ԫ�أ�ֱ���ҵ���һ���� 12 С��Ԫ�� 11 ʱֹͣ�Ƚϣ���ʱ 31 ��Ӧ������ 1 ���� 12 ��Ҫ�����λ�á�
��ʼ�� ? ?[11, 31, 12, 5, 34, 30, 26, 38, 36, 18]
��һ�ˣ� [11, 31 , 12, 5, 34, 30, 26, 38, 36, 18] �����ƶ���Ԫ�أ�
�ڶ��ˣ� [11, 12 , 31, 5, 34, 30, 26, 38, 36, 18] �� 31 ����ƶ���
�����ˣ� [5 , 11, 12, 31, 34, 30, 26, 38, 36, 18] �� 11, 12, 31 ������ƶ���
�����ˣ� [5, 11, 12, 31, 34 , 30, 26, 38, 36, 18] �����ƶ���Ԫ�أ�
�����ˣ� [5, 11, 12, 30 , 31, 34, 26, 38, 36, 18] �� 31, 34 ����ƶ���
�����ˣ� [5, 11, 12, 26 , 30, 31, 34, 38, 36, 18] �� 30, 31, 34 ����ƶ���
�����ˣ� [5, 11, 12, 26, 30, 31, 34, 38 , 36, 18] �����ƶ���Ԫ�أ�
�ڰ��ˣ� [5, 11, 12, 26, 30, 31, 34, 36 , 38, 18] �� 38 ����ƶ���
�ھ��ˣ� [5, 11, 12, 18 , 26, 30, 31, 34, 36, 38] �� 26, 30, 31, 34, 36, 38 ����ƶ���
�������������ѡ��������������������������ܹ�����ǰ��������Ԫ���Ѿ��ź����һ�����ƣ���Ч�ؼ���һЩ�ȽϵĴ�������Ȼ�������Ƶÿ�����ij�ʼ˳����Σ��������£�����������ǡ��Ϊ������������Ҫ�ȽϺ��ƶ��Ĵ���������� 1 + 2 + 3�� + n = n * (n + 1) / 2 �����ּ�������£����������Ч��������ѡ����������˲���������һ�����ȶ�������������Ч���������ʼ˳��ϢϢ��ء�һ������£����������ʱ�临�ӶȺͿռ临�Ӷȷֱ�Ϊ O(n2 ) �� O(1) ��
ʵ�ִ��룺
?
/**
* Insertion Sorting
*/
INSERTION(new Sortable() {
public <T extends Comparable<T>> void sort(T[] array, boolean ascend) {
int len = array.length;
for (int i = 1; i < len; i++) {
T toInsert = array[i];
int j = i;
for (; j > 0; j--) {
int compare = array[j - 1].compareTo(toInsert);
if (compare == 0 || compare < 0 == ascend) {
break;
}
array[j] = array[j - 1];
}
array[j] = toInsert;
}
}
})
?
3. ����
ð����������������������㷨�ˣ��ǵ�С����ѧʱ���ȽӴ���Ҳ��������㷨�ˣ���Ϊʵ�ַ���������� for ѭ�������ѭ�����ж���������Ԫ���Ƿ������ǵĻ�������Ԫ�ؽ��������ѭ��һ�Σ����ܽ�������ʣ�µ�Ԫ������С��Ԫ�ء���������ǰ�棬���Գ�֮Ϊð������
�����ٸ���ʵ���ɣ�
��ʼ״̬�� ? [24, 19, 26, 39, 36, 7, 31, 29, 38, 23]
�ڲ��һ�ˣ� [24, 19, 26, 39, 36, 7, 31, 29, 23 , 38 ] �� 9th [23]<->8th [38 ��
�ڲ�ڶ��ˣ� [24, 19, 26, 39, 36, 7, 31, 23 , 29 , 38] �� 8th [23]<->7th [29] ��
�ڲ�����ˣ� [24, 19, 26, 39, 36, 7, 23 , 31 , 29, 38] �� 7th [23]<->6th [31] ��
�ڲ�����ˣ� [24, 19, 26, 39, 36, 7, 23, 31, 29, 38] �� 7 �� 23 ��λ����ȷ��˳�����轻����
�ڲ�����ˣ� [24, 19, 26, 39, 7 , 36 , 23, 31, 29, 38] �� 5th [7]<->4th [36] ��
�ڲ�����ˣ� [24, 19, 26, 7 , 39 , 36, 23, 31, 29, 38] �� 4th [7]<->3rd [39] ��
�ڲ�����ˣ� [24, 19, 7 , 26 , 39, 36, 23, 31, 29, 38] �� 3rd [7]<->2nd [26] ��
�ڲ�ڰ��ˣ� [24, 7 , 19 , 26, 39, 36, 23, 31, 29, 38] �� 2nd [7]<->1st [19] ��
�ڲ�ھ��ˣ� [7 , 24 , 19, 26, 39, 36, 23, 31, 29, 38] �� 1st [7]<->0th [24] ��
��...
��ʵð�������ѡ������Ƚ����Ƚϴ���һ������Ϊ n * (n + 1) / 2 ������ð����������ѡ��Сֵ�Ĺ����л���ж���Ľ�����ð��������������ֻҪ��������Ԫ�ص�˳�Ծͻ���н�������֮��Ӧ����ѡ������ֻ�����ڲ�ѭ���ȽϽ���֮�������������Ƿ���н��������������ҿ�����ѡ����������ð������ĸĽ��档
ʵ�ִ��룺
?
/**
* Bubble Sorting, it's very similar with Insertion Sorting
*/
BUBBLE(new Sortable() {
public <T extends Comparable<T>> void sort(T[] array, boolean ascend) {
int length = array.length;
int lastExchangedIdx = 0;
for (int i = 0; i < length; i++) {
// mark the flag to identity whether exchange happened to false
boolean isExchanged = false;
// last compare and exchange happened before reaching index i
int currOrderedIdx = lastExchangedIdx > i ? lastExchangedIdx : i;
for (int j = length - 1; j > currOrderedIdx; j--) {
int compare = array[j - 1].compareTo(array[j]);
if (compare != 0 && compare > 0 == ascend) {
exchange(array, j - 1, j);
isExchanged = true;
lastExchangedIdx = j;
}
}
// if no exchange happen means array is already in order
if (isExchanged == false) {
break;
}
}
}
})
?
?
4. ϣ������
ϣ������ĵ��������ڲ��������ڴ������ģ�����ʱ���������Ҫ�ƶ�̫��Ԫ�ص����⡣ϣ�������˼���ǽ�һ��������顰�ֶ���֮��������Ϊ���ɸ�С�����飬�� gap �����֣��������� [1, 2, 3, 4, 5, 6, 7, 8] ������� gap = 2 �����֣����Է�Ϊ [1, 3, 5, 7] �� [2, 4, 6, 8] �������飨��Ӧ�ģ��� gap = 3 ���ֵ�����Ϊ�� [1, 4, 7] �� [2, 5, 8] �� [3, 6] ��Ȼ��ֱ�Ի��ֳ�����������в������������������������֮���ټ�С gap ֵ�ظ�����֮ǰ�IJ��裬ֱ�� gap = 1 ����������������в�������ʱ�������Ѿ������Ͽ��ź����ˣ�������Ҫ�ƶ���Ԫ�ػ��С��С������˲��������ڴ������ģ����ʱ�϶��ƶ����������⡣
����ʵ������ղ�������
ϣ�������Dz�������ĸĽ��棬�����������ʱ���Ч�ʵ����������ܴ�������С��ʱ����ֱ��ʹ�ò�������ͺ��ˡ�
ʵ�ִ��룺
?
/**
* Shell Sorting
*/
SHELL(new Sortable() {
public <T extends Comparable<T>> void sort(T[] array, boolean ascend) {
int length = array.length;
int gap = 1;
// use the most next to length / 3 as the first gap
while (gap < length / 3) {
gap = gap * 3 + 1;
}
while (gap >= 1) {
for (int i = gap; i < length; i++) {
T next = array[i];
int j = i;
while (j >= gap) {
int compare = array[j - gap].compareTo(next);
// already find its position
if (compare == 0 || compare < 0 == ascend) {
break;
}
array[j] = array[j - gap];
j -= gap;
}
if (j != i) {
array[j] = next;
}
}
gap /= 3;
}
}
})
?
?
5. �鲢����
�鲢������õ����ݹ���ʵ�֣����ڡ��ֶ���֮������Ŀ��������м�һ��Ϊ����֮��ֱ��������������������������֮���ٽ��ź�����������顰�鲢����һ�𣬹鲢��������Ҫ��Ҳ����������鲢���Ĺ��̣��鲢�Ĺ�������Ҫ����ĸ���Ҫ�鲢���������鳤��һ�µĿռ䣬������Ҫ�涨������ֱ�Ϊ�� [3, 6, 8, 11] �� [1, 3, 12, 15] ����Ȼ���ϱ���ΪΪ�������飬��ʵ������ЩԪ�ػ���λ��ԭ�������еģ�ֻ��ͨ��һЩ index ���仮�ֳ��������飬ԭ����Ϊ [3, 6, 8, 11, 1, 3, 12, 15 ��������������ָ�� lo, mid, high �ֱ�Ϊ 0,3,7 �Ϳ���ʵ�����ϵ������黮�֣���ô��Ҫ�Ķ�������ij���Ϊ 4 + 4 = 8 ���鲢�Ĺ��̿��Լ�Ҫ�ظ���Ϊ���£�
1�� �������������е�Ԫ�ظ��Ƶ������� copiedArray �У���ǰ���ᵽ������Ϊ������ copiedArray = [3, 6, 8, 11, 1, 3, 12, 15] ��
2�� ��������ָ��ֱ�ָ��ԭ�������ж�Ӧ�ĵ�һ��Ԫ�أ��ٶ�������ָ��ȡ��Ϊ leftIdx �� rightIdx ���� leftIdx = 0 ����Ӧ copiedArray �еĵ�һ��Ԫ�� [3] ���� rightIdx = 4 ����Ӧ copiedArray �еĵ����Ԫ�� [1] ����
3�� �Ƚ� leftIdx �� rightIdx ָ�������Ԫ��ֵ��ѡȡ���н�С��һ��������ֵ����ԭ�����ж�Ӧ��λ�� i ����ֵ��Ϻ�ֱ�Բ��븳ֵ������������������ 1 ��������� leftIdx �� rigthIdx ֵ�Ѿ��ﵽ��Ӧ�����ĩβ��������ֻ��Ҫ��ʣ�������Ԫ�ذ�˳�� copy �����µ�λ�ü��ɡ�
��������鲢�ľ���ʵ����
��һ�ˣ�
�������� [21 , 28, 39 | 35, 38] �����鱻���Ϊ�������������飬�� | �ָ�����
[21 , ?, ?, ?, ?] ����һ�� 21 �� 35 �Ƚ� , ���������ʤ���� leftIdx = 0 �� i = 0 ��
�ڶ��ˣ�
�������� [21, 28 , 39 | 35, 38]
[21 , 28, ?, ?,? ] ���ڶ��� 28 �� 35 �Ƚϣ����������ʤ���� leftIdx = 1 �� i = 1 ��
�����ˣ� [21, 28, 39 | 35 , 38]
?[21 , 28 , 35, ?, ?] �������� 39 �� 35 �Ƚϣ��ұ�������ʤ���� rightIdx = 0 �� i = 2 ��
�����ˣ� [21, 28, 39 | 35, 38 ]
?[21 , 28 , 35 , 38,? ] �����Ĵ� 39 �� 38 �Ƚϣ��ұ�������ʤ���� rightIdx = 1 �� i = 3 ��
�����ˣ� [21, 28, 39 | 35, 38]
?[21 , 28 , 35 , 38 , 39] �������ʱ�ұ��������Ѹ����꣬����Ƚ� leftIdx = 2 �� i = 4 ��
���ϱ���һ�ι鲢�Ĺ��̣����ǿ��Խ�������Ҫ��������������β�֣�ÿ��һ��Ϊ����ֱ����Ϊ����Ϊ 1 ��С����Ϊֹ������Ϊ 1 ʱ�����Ѿ����������ˡ�����֮�����������ڲ��õݹ飩���ζ���Щ������й鲢������ֱ�����һ�ι鲢����Ϊ n / 2 �������飬�鲢���֮����������Ҳ��ɡ�
�鲢������Ҫ�Ķ���ռ�����������������ģ�ÿ�ι鲢��Ҫ�����鲢���������鳤��֮����ͬ��Ԫ�أ�Ϊ���ṩ�������飩��������ƶϹ鲢����Ŀռ临�Ӷ�Ϊ 1 + 2 + 4 + �� + n = n * ( n + 2) / 4 �������� n ����ż�Ե��жϣ���ʱ�临�ӶȱȽ��ѹ�������С��Ҳ�����Ƕ����ˣ��壩��
ʵ�ִ��룺
?
/** * Merge sorting */ MERGE(new Sortable() { public <T extends Comparable<T>> void sort(T[] array, boolean ascend) { this.sort(array, 0, array.length - 1, ascend); } private <T extends Comparable<T>> void sort(T[] array, int lo, int hi, boolean ascend) { // OPTIMIZE ONE // if the substring's length is less than 20, // use insertion sort to reduce recursive invocation if (hi - lo < 20) { for (int i = lo + 1; i <= hi; i++) { T toInsert = array[i]; int j = i; for (; j > lo; j--) { int compare = array[j - 1].compareTo(toInsert); if (compare == 0 || compare < 0 == ascend) { break; } array[j] = array[j - 1]; } array[j] = toInsert; } return; } int mid = lo + (hi - lo) / 2; sort(array, lo, mid, ascend); sort(array, mid + 1, hi, ascend); merge(array, lo, mid, hi, ascend); } private <T extends Comparable<T>> void merge(T[] array, int lo, int mid, int hi, boolean ascend) { // OPTIMIZE TWO // if it is already in right order, skip this merge // since there's no need to do so int leftEndCompareToRigthStart = array[mid].compareTo(array[mid + 1]); if (leftEndCompareToRigthStart == 0 || leftEndCompareToRigthStart < 0 == ascend) { return; } @SuppressWarnings("unchecked") T[] arrayCopy = (T[]) new Comparable[hi - lo + 1]; System.arraycopy(array, lo, arrayCopy, 0, arrayCopy.length); int lowIdx = 0; int highIdx = mid - lo + 1; for (int i = lo; i <= hi; i++) { if (lowIdx > mid - lo) { // left sub array exhausted array[i] = arrayCopy[highIdx++]; } else if (highIdx > hi - lo) { // right sub array exhausted array[i] = arrayCopy[lowIdx++]; } else if (arrayCopy[lowIdx].compareTo(arrayCopy[highIdx]) < 0 == ascend) { array[i] = arrayCopy[lowIdx++]; } else { array[i] = arrayCopy[highIdx++]; } } } })
?
6. ��������
��������Ҳ���ù鲢����ʵ�ֵ�һ�����ֶ���֮���������㷨����������֮������������ÿ��partition�������㷨�ĺ������ڣ�����Ϊһ������Ԫ��ȷ��������������ȷλ�ã�һ�ξͶ�λ���´�ѭ���Ͳ��������Ԫ���ˣ���
���������partition���������������У��ٶ��������������Ϊarr��
1��?ѡ��һ��Ԫ�أ�Ϊ�˼��������ѡ��partition�ĵ�һ��Ԫ�أ���arr[0]����Ϊ��Ԫ�أ��������IJ����Ϊ��ȷ��������ɺ����յ�λ�ã�
2��?1��? ��������Ҫ����[1��n-1]��Ӧ������Ԫ�������ҵ�arr[0]ֵ����v�������Ӧ��λ�ã�����iΪ��ǰ���������������ltΪֵС��v�����������gtΪֵ����v����С��������ô�ڱ��������У��������iָ���ֵ��v��ȣ���iֵ��1��������һ�αȽϣ����iָ���ֵ��vС����i��lt��Ӧ��Ԫ�ؽ��н�����Ȼ��ֱ�����������1�����iָ���ֵ��v����i��gt��Ӧ��Ԫ�ؽ��н�����Ȼ��i������gt�Լ���ѭ��������ɣ�i > gtʱ������֮����Ա�֤[0��lt-1]��Ӧ��ֵ���DZ�vС�ģ�[lt..gt]֮���ֵ������v��ȵģ�[gt+1��n-1]��Ӧ��ֵ���DZ�v��ġ�
3��?�ֱ��[0��lt-1]��[gt+1��n-1]�������������������˵ݹ飬ֱ������������ij���Ϊ0��
?
����ٸ�partition�ľ���ʵ����
��ʼ��i = 1, lt = 0, gt = 8����
?????? [41, 59, 43, 26, 63, 30, 29, 26, 42]����Ҫȷ��λ�õ�Ϊ0th[41]��
��һ�ˣ�i = 1, lt = 0, gt = 8����
?????? [41, 42, 43, 26, 63, 30, 29, 26, 59]��1st[59] > 41��1st[59]<->8th[42]��gt--��
�ڶ��ˣ�i = 1, lt = 0, gt = 7����
?????? [41, 26, 43, 26, 63, 30, 29, 42, 59]��1st[42] > 41��1st[42]<->7th[26]��gt--��
�����ˣ�i = 1, lt = 0, gt = 6����
?????? [26, 41, 43, 26, 63, 30, 29, 42, 59]��1st[26] < 41, 1st[26]<->0st[41]��i++, lt++��
�����ˣ�i = 2, lt = 1, gt = 6����
?????? [26, 41, 29, 26, 63, 30, 43, 42, 59]��2nd[43] > 41��2nd[43]<->6th[29]��gt--��
�����ˣ�i = 2, lt = 1, gt = 5����
?????? [26, 29, 41, 26, 63, 30, 43, 42, 59]��2nd[29] < 41, 2nd[29]<->1st[41]��i++��lt++��
�����ˣ�i = 3, lt = 2, gt = 5����????
?????? [26, 29, 26, 41, 63, 30, 43, 42, 59]��3rd[26] < 41��3rd[26]<->2nd[41]��i++��lt++��
�����ˣ�i = 4, lt = 3, gt = 5����
?????? [26, 29, 26, 41, 30, 63, 43, 42, 59] ��4th[63] > 41��4th[63]<->5th[30]��gt--��
�ڰ��ˣ�i = 4, lt = 3, gt = 4����????
?????? [26, 29, 26, 30, 41, 63, 43, 42, 59]��4th[30] < 41��4th[30]<->3rd[41]��i++��lt++��
?
���Կ�������һ��partition֮����41Ϊ�ָ��ߣ�41����Ϊ����С��Ԫ�أ�41�Ҳ��Ϊ���������ȵ�Ԫ�أ���Ȼ���ʵ���Ƚ����⣬û�г��ֺ�41��ȵ�Ԫ�أ��������������˼����������ٶȷdz��죬�����һ�����һ������ܸ���������ʱ��Ա�ͼ��ֵ��һ�����JDK����Arrays�����������õ�sort�������ǽӺϲ����������·��������ʵ�ֵģ�����Ȥ��ͬѧ���Կ���JDK��Դ�롣
?
ʵ�ִ��룺
?
/**
* Quick Sorting
*/
QUICK(new Sortable() {
public <T extends Comparable<T>> void sort(T[] array, boolean ascend) {
this.sort(array, 0, array.length - 1, ascend);
}
private <T extends Comparable<T>> void sort(T[] array, int lo, int hi, boolean ascend) {
if (lo >= hi) {
return;
}
T toFinal = array[lo];
int leftIdx = lo;
int rightIdx = hi;
int i = lo + 1;
while (i <= rightIdx) {
int compare = array[i].compareTo(toFinal);
if (compare == 0) {
i++;
} else if (compare < 0 == ascend) {
exchange(array, leftIdx++, i++);
} else {
exchange(array, rightIdx--, i);
}
}
// partially sort left array and right array
// no need to include the leftIdx-th to rightIdx-th elements
// since they are already in its final position
sort(array, lo, leftIdx - 1, ascend);
sort(array, rightIdx + 1, hi, ascend);
}
})
?
?
�����ϣ���鿴�������룬���Ƽ����ҵ�GoogleCode�鿴�������š�
�������Ҳ���ʱ�IJ���������������ö���Ͳ���ģʽ�����ƣ��л������㷨ʱ��Ի�Ƚ����ס�
?
����Ϊ���������㷨���һ��������еĺ�ʱ�Ա�ͼ�������õ�������鳤��Ϊ50000����ֱ�ӽصIJ���������ͼ��
?
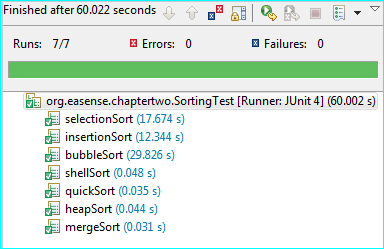
?
?
?�����в����ᵽ������GoogleCode,�ҽ���Ŀ�����Ը����ķ�ʽ�ϴ���,��Ҫ�IJ��������ذ�.
?
?




