Head First Search Engine 1――Web Crawlers――bitmap
搜索引擎中的ADT(Abstract Data Type)及
算法是我本科毕业论文所涉及的内容,谈不上
研究,只是粗略的涉及了点皮毛,拿Lucene做了套小规模的搜索引擎。本来这个毕业设计是为了考研复试准备的,遗憾的是连初试都没有过。但是这并不影响我再考一年的决心,现在一边工作一边考研,累的时候就上来写点儿东西,将之前学到的东西都记录下来,做个总结,也当是分享吧,如果其中有什么
错误,还请见谅,本人水平一般。
这个系列主要想介绍一下搜索引擎的相关知识,以及在搜索引擎中涉及到的ADT及算法。这些ADT将和我们传统的数据结构教学中的ADT做比较。这些内容比较适合对数据结构这门课程的扩展教学。之所以喜欢用ADT,可能是受了清华朱忠涛老师的影响吧,当时在听他课的时候老用ADT(当然我不是清华的),所以自己也用
习惯了。好像严蔚敏老师上课也用的是ADT。
我大致规划了一下,这个系列主要会讲到如下方面:
Head First Search Engine 1――Web Crawlers bitmap、图算法、哈希表等。
Head First Search Engine 2――analytical
system 堆栈。
Head First Search Engine 3――Index System 归并排序。
Head First Search Engine 4――Query System
堆排序。
在这些文章中,我基本会涉及到所有的传统数据结构,就当是为接下来的考研做个
复习。在文章列表里有个Algorithms的分类,不再写有关传统ADT了,那里主要会放一些比较精巧的算法,比如协同过滤、多分树存储这些。
下面开始讲述这节的主要内容Bitmap:
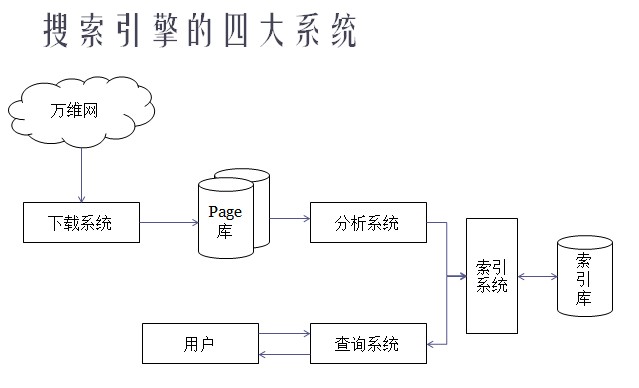
在搜索引擎这套系统中,如果按照运行流程来分,可以分为四个子系统,分别是:下载系统、分析系统、索引系统和查询系统。
下载系统:其中有我们熟知的
网络爬虫,他主要负责抓取网络当中的页面,并交由分析系统做处理。
分析系统:主要做页面的
解析工作,这些解析包括页面中链接的分析、对页面内容进行分词、对网页的内容按照一定的规则进行打分等。
索引系统:主要对处理完的页面建立索引,并做简单的排序工作。
查询系统:直接面向用户,是我们所说的“检索”的门户,主要负责对大规模数据查找和排序,找出符合
用户需求的信息。
下面我们模拟这样一个环境:
我们将一个页面当作是图(Graph)中的顶点(Vertex),将指向其他页面的链接(link)看作是图中的边(edge)。有了这个假设之后,整个互联网就可以看作是一张巨大的有向连通图。假设我们的爬虫从一个导航页面开始对互联网进行遍历,下面问题来了,你怎样保证爬虫所走过的路不会产生环路?或者,怎样保证在同一次抓取过程中,被抓取过的页面不再被重复抓取?
我觉得很容易可以想到用哈希表,或者更直接的说,如果我用Java语言,我可以使用Map或者Set这样去重复的集合来做这件事情。当然也会有人想到用数据库来做帮助,因为那也有唯一
主键。是的,我们需要的就是唯一。可是用上述的方法来做,是否会太浪费空间了,如果用数据库了,每次抓取前先遍历一遍数据库,是不是太小题大做了。
我们知道
hash表的查找效率是非常高的,为O(1),在Java中如果我们将链接映射到hash表中,那样的话很容易通过hash code就能找到原纪录是否存在。其核心只要我们能减少存储空间即可。
采用bitmap这种数据结构的好处主要是在不改变查询效率的同时,可以节省空间。
拿java为例,一个Int类型的数占了4个字节(B),即32位(bit),如果建立一个存放整型数据且长度为8的hash表,则需要32字节,共256位。如果采用传统的hash表使用方式,长度为8的哈希表,
最多只能存放8条互不相同的记录。
我相信写到这里很多人已经想到了,如果我们按位(bit)存储,而不是传统的按字节存储,即用
比特(bit)位来区分这些记录,那长度为8的哈希变不就能存放256条互不相同的记录了么?

确实,bitmap就是用这种思路来压缩存储的,这样一来,上面的
例子中,一下子节省了1/32的空间。bitmap这种ADT,借助按位与和按位或,以及左移运算(<<)和右移(>>)运算来实现压缩存储信息。下面我们来看具体的实现细节:
public static void testBitmap(int num) {
int MD5 = num;
int index_int = MD5 & 31;
int index_Hash = (MD5 >> 5) & 7;// (34/32)%8=1
System.out.println(index_Hash);
if ((Hash_MD5[index_Hash] & (1 << index_int)) != 0) {// 查询某个比特为是否为1
System.out.println("has been used");
} else {
Hash_MD5[index_Hash] = Hash_MD5[index_Hash] | (1 << index_int);
if ((Hash_MD5[index_Hash] & (1 << index_int)) == 1) {
System.out.println("successful");
}
}
}
其中:传入的参数num为通过MD5单项函数处理过的链接,这部分内容我会放在下一讲关于hash数据结构中讲述。现在你只要知道,一个URL通过MD5函数转换成了一个整型的数据,及num,然后将num按位存储。
我们对上述细节再做一些描述:
例如一个URL:www.baidu.com经过MD5函数计算后,转换成了数值34,然后,我们将对34做bitmap处理。在这里我们使用长度为8的整型数组做示例,即Hash_MD5[0…7]。
第一步,(34/32)%8==1,即程序中的index_Hash = (MD5 >> 5) & 7,求出这个num应存放在Hash_MD5[1]中。
第二步,34%32==2,即程序中的Hash_MD5[index_Hash] | (1 << index_int),这样就能确定在Hash_MD5[1]中,低位的第2位被置为1(低位从0开始,二进制
编码为:00000000 00000000 00000000 00000100)。所以在Hash_MD5[1]中存放的值为4。
当然,有一种更简单的方法:
直接将34化为二进制形式,即0010 0010,因为每个单元是长度是32bit,所以我们将二进制前后分为001 | 00010,这样一来,前面的值代表存储在数组中的位置(即按字节存,Hash_MD5[1]),后面的值为2,代表了按bit存,将低位第三位置为1。
例如:又有一个URL经过MD5函数转换为45,转化为二进制后即 001 | 00111,这样可知,按bit存,将低位第13位置为1(低位从零开始)。然后将Hash_MD5[1]中原本的4,加上现在的2^13,相加后为:2^13+2^2。
以上算法在实际处理中也会遇到问题:
面对相当庞大的数据集时,很容易造成数据在定位上的冲突,针对这一问题,当然有很多解决办法,比如在数据结构课程中讲到的开放定址法、拉链法等。但是这样做会给查找也带来一定的麻烦。产生这种冲突的主要原因就是bitmap的前期处理――将URL转换成数值的过程。因为这里的处理做的比较简单,只通过一个MD5函数进行转换,所以才增大了冲突的概率。就个人认为,这种概率上的问题并不是由bitmap这种数据结构本身带来的,至于前期如何做处理才能保证没有冲突,那是前期的问题。Bitmap确实是给了我们一种很好的解决问题的办法。
有一种ADT叫Bloom Filter,据说可以解决以上问题。其实Bloom Filter解决问题的原因并不在处理存储的过程上,而是前期对数据的处理。Bloom Filter用了多个哈希函数来确保转换的唯一性。
综上,bitmap很厉害,可以给我们的处理带来很多启发,不论实在查重或者数据压缩上,但是根据bitmap存在的风险,我们需要由哈希函数来解决。所以下一节,将写关于哈希的相关知识。
以上只是一种思路,具体的实现网上应该都有成篇的代码。个人愚见,谢谢观看。
本文原创,转载请指明出处,谢谢。

- 大小: 40.1 KB

- 大小: 29 KB