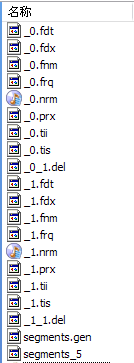
����ͼ������������Ϣ���ļ��У�
- segments_N�����˴������������ٸ��Σ�ÿ���ΰ�������ƪ�ĵ���
- XXX.fnm�����˴˶ΰ����˶��ٸ���ÿ��������Ƽ�������ʽ��
- XXX.fdx��XXX.fdt�����˴˶ΰ����������ĵ���ÿƪ�ĵ������˶�����ÿ��������Щ��Ϣ��
- XXX.tvx��XXX.tvd��XXX.tvf�����˴˶ΰ��������ĵ���ÿƪ�ĵ������˶�����ÿ��������˶��ٴʣ�ÿ���ʵ��ַ�����λ�õ���Ϣ��
��ν������Ϣ��
- �����˴ʵ䵽���ű���ӳ�䣺��(Term) �C> �ĵ�(Document)
- ����ͼ������������Ϣ���ļ��У�
- XXX.tis��XXX.tii�����˴ʵ�(Term Dictionary)��Ҳ���˶ΰ��������еĴʰ��ֵ�˳�������
- XXX.frq�����˵��ű���Ҳ������ÿ���ʵ��ĵ�ID�б���
- XXX.prx�����˵��ű���ÿ�����ڰ����˴ʵ��ĵ��е�λ�á�
?
���˽�Lucene��������ϸ�ṹ֮ǰ���ȿ���Lucene�����еĻ����������͡�
?
?
������������
Lucene�����ļ��У���һ�»���������������Ϣ��
- Byte��������������ͣ���8λ(bit)��
- UInt32����4��Byte��ɡ�
- UInt64����8��Byte��ɡ�
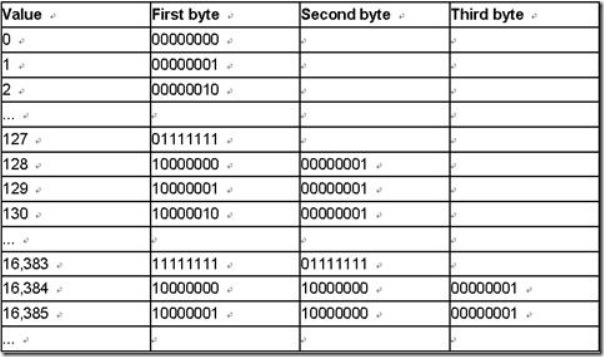
- VInt��
- �䳤���������ͣ������ܰ������Byte������ÿ��Byte��8λ�����к�7λ��ʾ��ֵ�����1λ��ʾ�Ƿ�����һ��Byte��0��ʾû�У�1��ʾ�С�
- Խǰ���Byte��ʾ��ֵ�ĵ�λ��Խ�����Byte��ʾ��ֵ�ĸ�λ��
- ����130��Ϊ������Ϊ 1000, 0010���ܹ���Ҫ8λ��һ��Byte��ʾ���ˣ������Ҫ����Byte����ʾ����һ��Byte��ʾ��7λ�����������λ��1����ʾ���滹��һ��Byte������Ϊ(1) 0000010���ڶ���Byte��ʾ��8λ���������λ��0����ʾ����û��������Byte�ˣ�����Ϊ(0) 0000001��
?
- Chars����UTF-8������һϵ��Byte��
- String��һ���ַ���������һ��VInt����ʾ���ַ����������ַ��ĸ��������ű���UTF-8������ַ�����Chars��
������������
LuceneΪ��ʹ����Ϣ�Ĵ洢ռ�õĿռ��С�������ٶȸ��죬��ȡ��һЩ����ļ��ɣ�Ȼ���ڿ�Lucene�ļ���ʽ��ʱ����Щ����ȴ����ʹ���Ǹе����������б�Ҫ����Щ����ļ��ɹ�����ȡ��������һ�¡�
���²��ţ����Ҹ���Щ��������һЩ���֣���Ϊ�˷������Ӧ����Щ�����ʱ���ܹ�������֮�������½⡣
1. ǰ������(Prefix+Suffix)
Lucene�ڷ��������У�Ҫ����ʵ�(Term Dictionary)����Ϣ�����еĴ�(Term)�ڴʵ����ǰ����ֵ�˳��������еģ�Ȼ���ʵ��а������ĵ��еļ������еĴʣ������еĴʻ��Ƿdz��ij��ģ����������ļ���dz��Ĵ���νǰ��������ij���ʺ�ǰһ�����й�ͬ��ǰ��ʱ����Ĵʽ�������ǰ�ڴ��е�ƫ��(offset)���Լ���ǰ������ַ���(��Ϊ��)��

����Ҫ�洢���´�:term��termagancy��termagant��terminal��
�������������ʽ���洢����Ҫ�Ŀռ����£�
[VInt = 4] [t][e][r][m]��[VInt = 10][t][e][r][m][a][g][a][n][c][y]��[VInt = 9][t][e][r][m][a][g][a][n][t]��[VInt = 8][t][e][r][m][i][n][a][l]
����Ҫ35��Byte.
���Ӧ��ǰ��������Ҫ�Ŀռ����£�
[VInt = 4] [t][e][r][m]��[VInt = 4 (offset)][VInt = 6][a][g][a][n][c][y]��[VInt = 8 (offset)][VInt = 1][t]��[VInt = 4(offset)][VInt = 4][i][n][a][l]
����Ҫ22��Byte��
�����С�˴洢�ռ䣬�������ڰ��ֵ�˳�����������£�ǰ���غ��ʴ����ߡ�
2. ��ֵ����(Delta)
��Lucene�ķ��������У���Ҫ����ܶ��������ֵ���Ϣ�������ĵ�ID�ţ������(Term)���ĵ��е�λ�õȵȡ�
��������ܣ�����֪����������������VInt�ĸ�ʽ�洢�ġ�������ֵ������ÿ������ռ�õ�Byte�ĸ���Ҳ�����ࡣ��ν��ֵ����(Delta)�����Ⱥ�����������ʱ������������������ǰ�������IJ�ɡ�

����Ҫ�洢����������16386��16387��16388��16389
�������������ʽ���洢����Ҫ�Ŀռ����£�
[(1) 000, 0010][(1) 000, 0000][(0) 000, 0001]��[(1) 000, 0011][(1) 000, 0000][(0) 000, 0001]��[(1) 000, 0100][(1) 000, 0000][(0) 000, 0001]��[(1) 000, 0101][(1) 000, 0000][(0) 000, 0001]
����12��Byte��
���Ӧ�ò�ֵ�������洢����Ҫ�Ŀռ����£�
[(1) 000, 0010][(1) 000, 0000][(0) 000, 0001]��[(0) 000, 0001]��[(0) 000, 0001]��[(0) 000, 0001]
����6��Byte��
�����С�˴洢�ռ䣬�����������ĵ�ID�����Ǵ����ĵ��е�λ�ã����ǰ���С�����˳��������ġ�
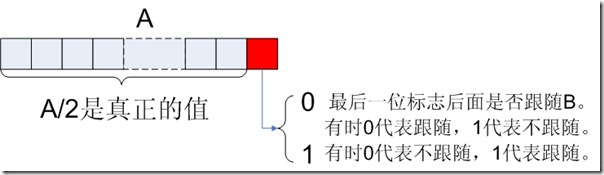
3. ��Ȼ�������(A, B?)
Lucene�������ṹ�д��������������ij��ֵA������ܴ���ij��ֵB��Ҳ���ܲ����ڣ���Ҫһ����־����ʾ�����Ƿ������B��
һ�������£���A�������һ��Byte��Ϊ0����治����B��Ϊ1��������B������0��������B��1����治����B��
������Ҫ�˷�һ��Byte�Ŀռ䣬��ʵһ��Bit�Ϳ����ˡ�
��Lucene�У���ȡ���µķ�ʽ��A��ֵ����һλ���ճ����һλ����Ϊ��־λ������ʾ�����Ƿ����B����������������£�A/2��������Aԭ����ֵ��
���ȥ��Apache Lucene - Index File Formats��ƪ���£��ᷢ�ֺܶ�������ֹ���ģ�
- .frq�ļ��е�DocDelta[, Freq?]��DocSkip,PayloadLength?
- .prx�ļ��е�PositionDelta,Payload? (������ȫ�ǣ����±�����)
?
��Ȼ����һЩ��?�ĵ������ڴ˹���ģ�
- .frq�ļ��е�SkipChildLevelPointer?���Ƕ����Ծ���У�ָ����һ�����ָ�룬��Ȼ��������һ�㣬��ֵ�Ͳ����ڣ�Ҳ����Ҫ��־��
- .tvf�ļ��е�Positions?, Offsets?��
- �ڴ�������£���?��ֵ�Ƿ���ڣ�����ȡ����ǰ���ֵ�����һλ��
- ����ȡ����Lucene��ij�����ã���Ȼ��Щ����Ҳ�DZ�����Lucene�����ļ��еġ�
- ��Position��Offset�Ƿ�洢��ȡ����.fnm�ļ��ж���ÿ���������(TermVector.WITH_POSITIONS��TermVector.WITH_OFFSETS)
?
Ϊʲô��������������������ʵ�ǿ��������ģ�
- ���ڷ��ϻ�Ȼ�������ģ�����Ϊ����ÿһ��A��B�Ƿ���ڶ�����ͬ������������������ڵ�ʱ��һ��Byte��һ��Bit���8���Ŀռ��Լ���Ǻ�ֵ�õġ�
- ���ڲ����ϻ�Ȼ�������ģ�����Ϊij��ֵ���Ƿ���ڵ����ö���������(Field)������������������Ч�ģ�����ÿ�ε����������ͬ���������ͳһ���һ����־��
�����ж����¸�ʽ��������������
?
Positions --> <PositionDelta,Payload?> Freq
Payload --> <PayloadLength?,PayloadData>
PositionDelta��Payload�Ƿ����û�Ȼ��������أ���α�ʶPayloadLength�Ƿ�����أ�
��ʵPositionDelta��Payload�������ϻ�Ȼ�������Payload�Ƿ���ڣ�����.fnm�ļ��ж���ÿ������������й�Payload�����þ�����(FieldOption.STORES_PAYLOADS) ��
��Payload������ʱ��PayloadDelta��������ӻ�Ȼ����ԭ��
��Payload����ʱ����ʽӦ�ñ�����£�Positions --> <PositionDelta,PayloadLength?,PayloadData> Freq
�Ӷ�PositionDelta��PayloadLengthһ�����û�Ȼ�������
?
?
4. ��Ծ������(Skip list)?
Ϊ����߲��ҵ����ܣ�Lucene�ںܶ�ط���ȡ����Ծ�������ݽṹ��
��Ծ��(Skip List)����ͼ��һ�����ݽṹ�������¼�������������
- Ԫ���ǰ�˳�����еģ���Lucene�У����ǰ��ֵ�˳�����У����ǰ���С����˳�����С�
- ��Ծ���м����(Interval)��Ҳ��ÿ����Ծ��Ԫ������������������úõģ���ͼ��Ծ���ļ��Ϊ3��
- ��Ծ�����ɲ�ε�(level)��ÿһ���ÿ��ָ�������Ԫ�ع�����һ�㣬��ͼ��Ծ������2�㡣
?
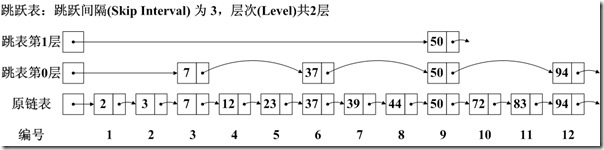
��Ҫע��һ����ǣ��ںܶ����ݽṹ���㷨���ж�������Ծ����������ԭ�����Ǵ�����ͬ�ģ����Ƕ������в��
- �Լ��(Interval)�Ķ��壺 ��ͼ�У��е���Ϊ���Ϊ2���������ϲ�Ԫ��֮���Ԫ�����������������ϲ�Ԫ�أ��е���Ϊ��3���������ϲ�Ԫ��֮��IJ���������ϲ�Ԫ�أ�������ǰ����ϲ�Ԫ�أ��е���Ϊ��4�����������ϲ�Ԫ��֮���Ԫ���⣬�Ȱ���ǰ�棬Ҳ����������ϲ�Ԫ�ء�Lucene�Dz�ȡ�ĵڶ��ֶ��塣
- �Բ��(Level)�Ķ��壺��ͼ�У��е���ΪӦ�ð���ԭ�����㣬����1��ʼ���������ܲ��Ϊ3��Ϊ1��2��3�㣻�е���ΪӦ�ð���ԭ�����㣬����0������Ϊ0��1��2�㣻�е���Ϊ��Ӧ�ð���ԭ�����㣬�Ҵ�1��ʼ��������Ϊ1��2�㣻�е���Ϊ��Ӧ�ð��������㣬�Ҵ�0��ʼ��������Ϊ0��1�㡣Lucene��ȡ�������һ�ֶ��塣
?
��Ծ����˳����ң��������˲����ٶȣ������Ԫ��72��ԭ��Ҫ����2��3��7��12��23��37��39��44��50��72�ܹ�10��Ԫ�أ�Ӧ����Ծ����ֻҪ���ȷ��ʵ�1���50������72����50������1������һ���ڵ㣬Ȼ����ʵ�2���94������94����72��Ȼ�����ԭ������72���ҵ�Ԫ�أ�����Ҫ����3��Ԫ�ؼ��ɡ�
Ȼ��Lucene�ھ���ʵ���ϣ���������������ͬ���ھ���ĸ�ʽ�У�����ϸ˵����
?
?
Lucene�ܵ���˵�ǣ�
- һ����Ч�ģ�����չ�ģ�ȫ�ļ����⡣
- ȫ����Javaʵ�֣��������á�
- ��֧�ִ��ı��ļ�������(Indexing)������(Search)��
- ��������������ʽ���ļ���ȡ���ı��ļ������������ץȡ�ļ��Ĺ��̡�
?
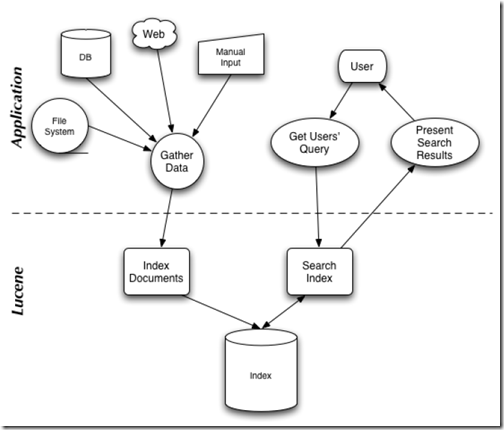
��Lucene in action�У�Lucene �Ĺ��ܺ�������ͼ��
 �ܹ� - j2ee_.net - Welcome to my Blog!">
�ܹ� - j2ee_.net - Welcome to my Blog!">
˵��Lucene�����������������������̣�����������������������������Ҫ�㡣
�����Ǹ�ϸһЩ��Lucene�ĸ������
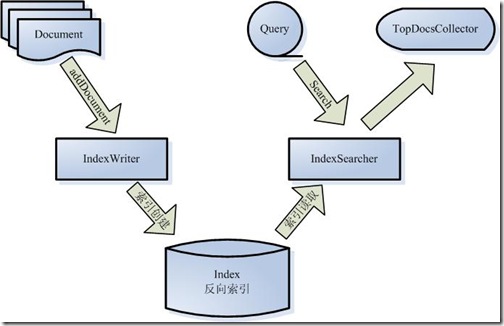
- ���������ĵ���Document�����ʾ��
- IndexWriterͨ������addDocument���ĵ����ӵ������У�ʵ�ִ��������Ĺ��̡�
- Lucene��������Ӧ�÷���������
- ���û�������ʱ��Query�����û�����ѯ�����
- IndexSearcherͨ������search����Lucene Index��
- IndexSearcher����term weight��score���ҽ�������ظ��û���
- ���ظ��û����ĵ�������TopDocsCollector��ʾ��
?
?
��ô���Ӧ����Щ����أ�
����������ϸ����Lucene API �ĵ���ʵ���������������̡�
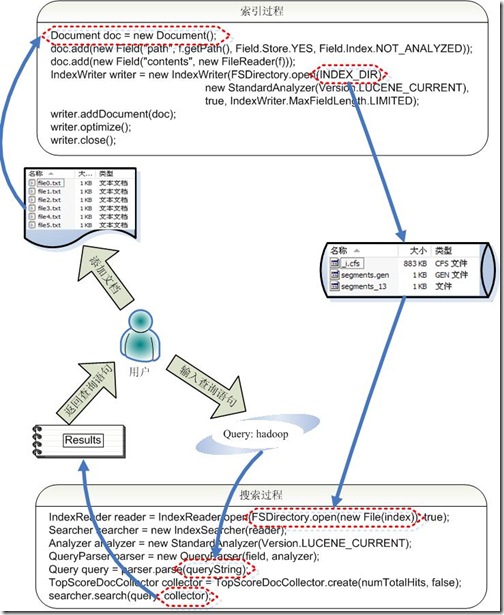
- �����������£�
- ����һ��IndexWriter����д�����ļ������м���������INDEX_DIR���������ļ�����ŵ�λ�ã�Analyzer�����������ĵ����дʷ����������Դ����ġ�
- ����һ��Document��������Ҫ�������ĵ���
- ����ͬ��Field���뵽�ĵ��С�����֪����һƪ�ĵ��ж�����Ϣ������Ŀ�����ߣ���ʱ�䣬���ݵȡ���ͬ���͵���Ϣ�ò�ͬ��Field����ʾ���ڱ������У�һ����������Ϣ������������һ�����ļ�·����һ�����ļ����ݡ�����FileReader��SRC_FILE�ͱ�ʾҪ������Դ�ļ���
- IndexWriter���ú���addDocument������д�������ļ����С�
- �����������£�
- IndexReader�������ϵ�������Ϣ���뵽�ڴ���INDEX_DIR���������ļ���ŵ�λ�á�
- ����IndexSearcher������������
- ����Analyer�����Բ�ѯ�����дʷ����������Դ�����
- ����QueryParser�����Բ�ѯ�������������
- QueryParser����parser������������γɲ�ѯ������ŵ�Query�С�
- IndexSearcher����search�Բ�ѯ���Query�����������õ����TopScoreDocCollector��
?
���ϱ���Lucene API�����ļ��á�
Ȼ��������Lucene��Դ�������Lucene�кܶ������ϵ���۸��ӡ�
Ȼ��ͨ����ͼ�����Dz��ѷ��֣�Lucene�ĸ�Դ��ģ�飬���Ƕ���ͨ�������������̵�һ��ʵ�֡�
��ͼ����һ�ڽ��ܵ�ȫ�ļ��������̶�Ӧ��Luceneʵ�ֵİ��ṹ��(����http://www.lucene.com.cn/about.htm�����¡�����Դ�����ȫ�ļ�������Lucene��)
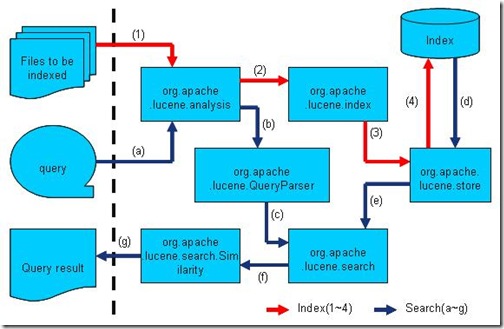
- Lucene��analysisģ����Ҫ����ʷ����������Դ������γ�Term��
- Lucene��indexģ����Ҫ���������Ĵ�����������IndexWriter��
- Lucene��storeģ����Ҫ���������Ķ�д��
- Lucene��QueryParser��Ҫ�����������
- Lucene��searchģ����Ҫ�����������������
- Lucene��similarityģ����Ҫ���������Դ�ֵ�ʵ�֡�
?
�˽���Lucene�������ṹ�����DZ���Կ�ʼLucene��Դ��֮���ˡ�
?
?
�ġ������ʽ
����������������Lucene�����˴�Index��Segment��Document��Fieldһֱ��Term��������Ϣ��Ҳ�����˴�Term��Documentӳ��ķ�����Ϣ����������һЩLucene���е���Ϣ���������������Ϣһһ���ܡ�
4.1. ������Ϣ
Index �C> Segments (segments.gen, segments_N) �C> Field(fnm, fdx, fdt) �C> Term (tvx, tvd, tvf)
����IJ�νṹ����ʮ�ֵ�ȷ����Ϊsegments.gen��segments_N������Ƕ�(segment)��Ԫ������Ϣ(metadata)����ʵ��ÿ��Indexһ���ģ����ε�������������Ϣ���DZ�������(Field)�ʹ�(Term)�еġ�
4.1.1. �ε�Ԫ������Ϣ(segments_N)
һ������(Index)����ͬʱ���ڶ��segments_N(������δ��ڶ��segments_N������������ϸ��Ϣ֮������˵��)��Ȼ��������Ҫ��һ��������ʱ�����DZ���Ҫѡ��һ�����������ѡ���ĸ�segments_N�أ�
Lucene��ȡ���¹��̣�
- ��һ�������е�segments_N��ѡ��N����һ��������������SegmentInfos.getCurrentSegmentGeneration(File[] files)�������˼·������������segments��ͷ�����Ҳ���segments.gen���ļ��У�ѡ��N����һ����ΪgenA��
- �������segments.gen�����б����˵�ǰ��Nֵ�����ʽ���£������汾��(Version)��Ȼ���ٶ�������N�����������ȣ�����ΪgenB��
-

?
IndexInput genInput = directory.openInput(IndexFileNames.SEGMENTS_GEN);//"segments.gen"
int version = genInput.readInt();//�����汾��
if (version == FORMAT_LOCKLESS) {//����汾����ȷ
??? long gen0 = genInput.readLong();//������һ��N
??? long gen1 = genInput.readLong();//�����ڶ���N
??? if (gen0 == gen1) {//������������ΪgenB
??????? genB = gen0;
??? }
}
- �������������õ���genA��genB��ѡ�������Ǹ���Ϊ��ǰ��N�����Ŵ�segments_N�ļ�������������£�
?
if (genA > genB)
??? gen = genA;
else
??? gen = genB;
?
?
����ͼ��segments_N�ľ����ʽ��
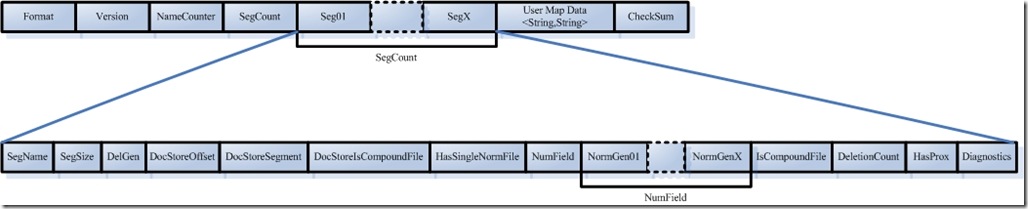
- Format��
- �����ļ���ʽ�İ汾�š�
- ����Lucene���ڲ��Ͽ��������еģ������ͬ�汾��Lucene���������ļ���ʽҲ������ͬ�����ǹ涨һ���汾�š�
- Lucene 2.1��ֵ-3��Lucene 2.9ʱ����ֵΪ-9��
- ����ij���汾�ŵ�IndexReader��ȡ��һ���汾�����ɵ�������ʱ����Ϊ��ֵ��ͬ��������
- Version��
- �����İ汾�ţ���¼��IndexWriter�����ύ�������ļ��еĴ�����
- ���ʼֵ���������´������ļ����������������������ʼ������ʱ�����赱ǰ��ʱ�䣬��ȡ��һ��Ψһֵ��
- ��ֵ�ı���IndexWriter.commit->IndexWriter.startCommit->SegmentInfos.prepareCommit->SegmentInfos.write->writeLong(++version)
- ���ʼֵ֮�����ȡһ��ʱ�䣬����Ϊ���Dz�������IndexWriter�����ύ�������ľ���������������ĵ����ĸ������µġ�IndexReader�г��Ƚ��Լ���version�������ļ��е�version�Ƿ���ͬ���жϴ�IndexReader������û�б�IndexWriter���¡�
?
//��DirectoryReader����һ�º�����
public boolean isCurrent() throws CorruptIndexException, IOException {
? return SegmentInfos.readCurrentVersion(directory) == segmentInfos.getVersion();
}
- NameCount
- ����һ���¶�(Segment)�Ķ�����
- ��������ͬһ���ε������ļ����Զ�����Ϊ�ļ�����һ��Ϊ_0.xxx, _0.yyy,? _1.xxx, _1.yyy ����
- �����ɵĶεĶ���һ��Ϊԭ����������һ��
- ��ͬ��������NameCount��������2��˵���µĶ�Ϊ_2.xxx, _2.yyy
?
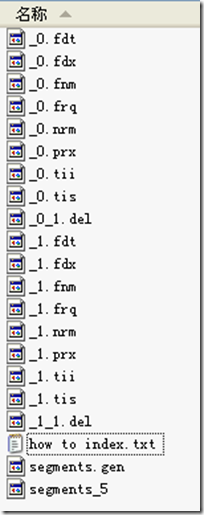
- SegCount
- ��(Segment)�ĸ�����
- ����ͼ����ֵΪ2��
- SegCount���ε�Ԫ������Ϣ��
- SegName
- ��������������ͬһ���ε��ļ������Զ�����Ϊ�ļ�����
- ����ͼ����һ���εĶ���Ϊ"_0"���ڶ����εĶ���Ϊ"_1"
- SegSize
- �˶��а������ĵ���
- Ȼ�����ĵ����ǰ����Ѿ�ɾ������û��optimize���ĵ��ģ���Ϊ��optimize֮ǰ��Lucene�Ķ��а��������б����������ĵ�������ɾ�����ĵ��DZ�����.del�ļ��еģ��������Ĺ����У����ȴӶ��ж����˱�ɾ�����ĵ���Ȼ������.del�еı�־������ƪ�ĵ����˵���
- ���µĴ����γ�����ͼ�����������Կ�����������ƪ�ĵ��γ���_0�Σ�Ȼ����ɾ��������һƪ���γ���_0_1.del������������ƪ�ĵ��γ�_1�Σ�Ȼ����ɾ��������һƪ���γ�_1_1.del��������������У���ֵ����2��
?
IndexWriter writer = new IndexWriter(FSDirectory.open(INDEX_DIR), new StandardAnalyzer(Version.LUCENE_CURRENT), true, IndexWriter.MaxFieldLength.LIMITED);
writer.setUseCompoundFile(false);
indexDocs(writer, docDir);//docDir��ֻ����ƪ�ĵ�
//�ĵ�һΪ��Students should be allowed to go out with their friends, but not allowed to drink beer.
//�ĵ���Ϊ��My friend Jerry went to school to see his students but found them drunk which is not allowed.
writer.commit();//�ύ��ƪ�ĵ����γ�_0�Ρ�
writer.deleteDocuments(new Term("contents", "school"));//ɾ���ĵ���
writer.commit();//�ύɾ�����γ�_0_1.del
indexDocs(writer, docDir);//�ٴ�������ƪ�ĵ���Lucene�����б��ĵ����ĵ��IJ�ͬ���������ƪ�µ��ĵ���
writer.commit();//�ύ��ƪ�ĵ����γ�_1��
writer.deleteDocuments(new Term("contents", "school"));//ɾ���ڶ������ӵ��ĵ���
writer.close();//�ύɾ�����γ�_1_1.del
- ?
- DelGen
- .del�ļ��İ汾��
- Lucene�У���optimize֮ǰ��ɾ�����ĵ��DZ�����.del�ļ��еġ�
- ��Lucene 2.9�У��ĵ�ɾ�������¼��ַ�ʽ��
- IndexReader.deleteDocument(int docID)����IndexReader���ĵ���ɾ����
- IndexReader.deleteDocuments(Term term)����IndexReaderɾ�������˴�(Term)���ĵ���
- IndexWriter.deleteDocuments(Term term)����IndexWriterɾ�������˴�(Term)���ĵ���
- IndexWriter.deleteDocuments(Term[] terms)����IndexWriterɾ��������Щ��(Term)���ĵ���
- IndexWriter.deleteDocuments(Query query)����IndexWriterɾ��������˲�ѯ(Query)���ĵ���
- IndexWriter.deleteDocuments(Query[] queries)����IndexWriterɾ����������Щ��ѯ(Query)���ĵ���
- ԭ���İ汾��Lucene��ɾ��һֱ����IndexReader����ɵģ���Lucene 2.9���������IndexWriter��ɾ����������ʵ������ʵ������IndexWriter�У�������readerpool����IndexWriter�������ļ��ύɾ����ʱ����Ȼ�Ǵ�readerpool�еõ���Ӧ��IndexReader������IndexReader������ɾ���ġ�����Ĵ������˵����
?
IndexWriter.applyDeletes()
-> DocumentsWriter.applyDeletes(SegmentInfos)
???? -> reader.deleteDocument(doc);
- ?
- ?
- ?
- DelGen��ÿ��IndexWriter�������ļ����ύcaozuo.html" target="_blank">ɾ��������ʱ��1���������µ�.del�ļ���
?
IndexWriter.commit()
-> IndexWriter.applyDeletes()
??? -> IndexWriter$ReaderPool.release(SegmentReader)
???????? -> SegmentReader(IndexReader).commit()
???????????? -> SegmentReader.doCommit(Map)
????????????????? -> SegmentInfo.advanceDelGen()
?????????????????????? -> if (delGen == NO) {
????????????????????????????? delGen = YES;
?????????????????????????? } else {
????????????????????????????? delGen++;
?????????????????????????? }
?
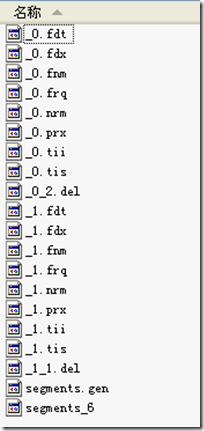
IndexWriter writer = new IndexWriter(FSDirectory.open(INDEX_DIR), new StandardAnalyzer(Version.LUCENE_CURRENT), true, IndexWriter.MaxFieldLength.LIMITED);
writer.setUseCompoundFile(false);
indexDocs(writer, docDir);//������ƪ�ĵ���һƪ����"school"����һƪ����"beer"
writer.commit();//�ύ��ƪ�ĵ��������ļ����γɶ�(Segment) "_0"
writer.deleteDocuments(new Term("contents", "school"));//ɾ������"school"���ĵ�����ʵ��ɾ������ƪ�ĵ��е�һƪ��
writer.commit();//�ύɾ���������ļ����γ�"_0_1.del"
writer.deleteDocuments(new Term("contents", "beer"));//ɾ������"beer"���ĵ�����ʵ��ɾ������ƪ�ĵ��е���һƪ��
writer.commit();//�ύɾ���������ļ����γ�"_0_2.del"
indexDocs(writer, docDir);//������ƪ�ĵ������ϴε��ĵ���ͬ������Lucene�����֣���Ϊ��������ƪ�ĵ���
writer.commit();//�ύ��ƪ�ĵ��������ļ����γɶ�"_1"
writer.deleteDocuments(new Term("contents", "beer"));//ɾ������"beer"���ĵ������ж�"_0"�Ѿ���ɾ������"_1"��ɾ��һƪ��
writer.close();//�ύɾ���������ļ����γ�"_1_1.del"
�γɵ������ļ����£�
?
?
- ?
- DocStoreOffset
- DocStoreSegment
- DocStoreIsCompoundFile
- ������(Stored Field)�ʹ�����(Term Vector)�Ĵ洢�����в�ͬ�ķ�ʽ��������ÿ����(Segment)�����洢�Լ�����ʹ�������Ϣ��Ҳ���Զ���ι�����ʹ������������Ǵ洢��һ������ȥ��
- ���DocStoreOffsetΪ-1����˶ε����洢�Լ�����ʹ��������Ӵ洢�ļ�������������˶ζ���ΪXXX����˶����Լ���XXX.fdt��XXX.fdx��XXX.tvf��XXX.tvd��XXX.tvx�ļ���DocStoreSegment��DocStoreIsCompoundFile�ڴ˴��������档
- ���DocStoreOffset��Ϊ-1����DocStoreSegment�����˹����Ķε����֣�����ΪYYY��DocStoreOffset��Ϊ�˶ε���������Ϣ�ڹ������е�ƫ��������˶�û���Լ���XXX.fdt��XXX.fdx��XXX.tvf��XXX.tvd��XXX.tvx�ļ������ǽ���Ϣ����ڹ����ε�YYY.fdt��YYY.fdx��YYY.tvf��YYY.tvd��YYY.tvx�ļ��С�
- DocumentsWriter����������Ա������String segment�ǵ�ǰ������Ϣ��ŵĶΣ�String docStoreSegment����ʹ�������Ϣ�洢�ĶΡ����߿�����ͬҲ���Բ�ͬ����������ʹ�������Ϣ�Ǵ洢�ڱ����У����Ǻ������Ķι�����
- IndexWriter.flush(boolean triggerMerge, boolean flushDocStores, boolean flushDeletes)�еڶ�������flushDocStores��Ӱ�쵽�Ƿ����ǹ����洢����ʵ����Ӱ�����DocumentsWriter.closeDocStore()��ÿ��flushDocStoresΪfalseʱ��closeDocStore�������ã�˵���´����ӵ������ļ��е���ʹ�������Ϣ��ͬ�˴ι���һ���εġ�ֱ��flushDocStoresΪtrue��ʱ��closeDocStore�����ã��Ӷ��´����ӵ������ļ��е���ʹ�������Ϣ����������һ���µĶ��У���ͬ�˴ι���һ����(��������Ҫָ������Lucene��һ������ֵ�ʵ�֣���Ȼ�´���ʹ�������Ϣ�DZ����浽�µĶ��У�Ȼ������ȴ����α�ȷ���˵ģ���initSegmentName�е�docStoreSegment == nullʱ������Ϊ��ǰ��segment��������һ���µ�segment��docStoreSegment = segment�����ǻ��������������ӵ�����)��
- ���ڹ�����ʹ������洢�����Ǿ�����ʹ�õ���ʵ��Ҳ����ȱ�ݣ����ҽ��͵��ˡ�
?
????? IndexWriter writer = new IndexWriter(FSDirectory.open(INDEX_DIR), new StandardAnalyzer(Version.LUCENE_CURRENT), true, IndexWriter.MaxFieldLength.LIMITED);
????? writer.setUseCompoundFile(false);
?
????? indexDocs(writer, docDir);
????? writer.flush();
//flush����segment "_0"������flush�����У�flushDocStores��Ϊfalse��Ҳ���¸��ν�ͬ���ι�����ʹ�������Ϣ����ʱDocumentsWriter�е�docStoreSegment= "_0"��
????? indexDocs(writer, docDir);
????? writer.commit();
//commit����segment "_1"�������ϴ�flushDocStores��Ϊfalse�����Ƕ�"_1"�����Լ���������Ϣ�DZ�����"_0"�еģ������ʱ�̣���"_1"���������Լ���"_1.fdx"��"_1.fdt"��Ȼ����commit�����У�flushDocStores��Ϊtrue��Ҳ���¸��ν�����ʹ���µĶ����洢��ʹ�������Ϣ��Ȼ����ʱ��DocumentsWriter�е�docStoreSegment= "_1"��Ҳ������"_2"�洢����ʹ�������Ϣ��ʱ���Ǵ���"_1.fdx"��"_1.fdt"�еģ�����"_1"����ʹ�������Ϣȴ�Ǵ���"_0.fdt"��"_0.fdx"�еģ���һ��dz��������� ��ͼwriter.commit��ʱ��_1.fdt��_1.fdx��û���γɡ�
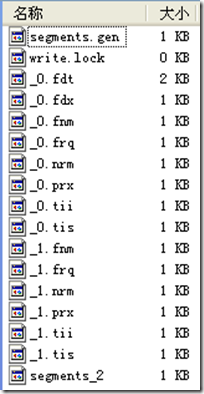
????? indexDocs(writer, docDir);
????? writer.flush();
//��"_2"�γɣ������ϴ�flushDocStores��Ϊtrue������ʹ�������Ϣ���´���һ���α���ģ�ȴ�DZ�����_1.fdt��_1.fdx�еģ���ʱ��Ų����˴˶��ļ���
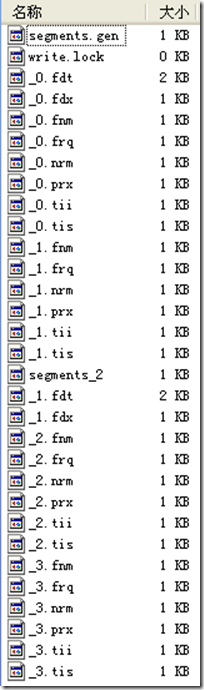
????? indexDocs(writer, docDir);
????? writer.flush();
//��"_3"�γɣ������ϴ�flushDocStores��Ϊfalse������ʹ�������Ϣ�ǹ���һ���α���ģ�Ҳ���DZ�����_1.fdt��_1.fdx�е�
????? indexDocs(writer, docDir);
????? writer.commit();
//��"_4"�γɣ������ϴ�flushDocStores��Ϊfalse������ʹ�������Ϣ�ǹ���һ���α���ģ�Ҳ���DZ�����_1.fdt��_1.fdx�еġ�Ȼ������commit��flushDocStores��Ϊtrue��Ҳ��ζ����һ���ν��´���һ���α�����ʹ�������Ϣ����ʱDocumentsWriter��docStoreSegment= "_4"��Ҳ��������Ȼ��"_4"����ʹ�������Ϣ�������˶�"_1"�У���������ʹ�������ϢȴҪ�����ڶ�"_4"�С���ʱ"_4.fdx"��"_4.fdt"��δ������???

????? indexDocs(writer, docDir);
????? writer.flush();
//��"_5"�γɣ������ϴ�flushDocStores��Ϊtrue������ʹ�������Ϣ���´���һ���α���ģ�ȴ�DZ�����_4.fdt��_4.fdx�еģ���ʱ��Ų����˴˶��ļ���
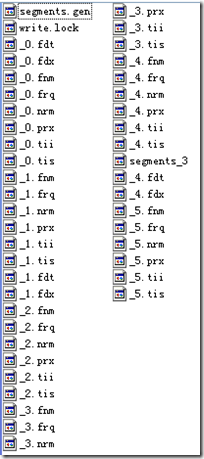
????? indexDocs(writer, docDir);
????? writer.commit();
????? writer.close();
//��"_6"�γɣ������ϴ�flushDocStores��Ϊfalse������ʹ�������Ϣ�ǹ���һ���α���ģ�Ҳ���DZ�����_4.fdt��_4.fdx�е�
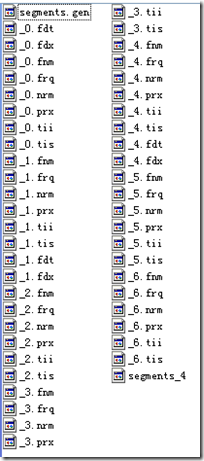
- ?
- HasSingleNormFile
- �������Ĺ����У���������(Normalization Factor)��Ӱ���ĵ��������֡�
- ��ͬ���ĵ���Ҫ�Բ�ͬ����ͬ������Ҫ��Ҳ��ͬ�����ÿ���ĵ���ÿ���������Լ��ı������ӡ�
- ���HasSingleNormFileΪ1�������еı������Ӷ��Ǵ���.nrm�ļ��еġ�
- ���HasSingleNormFile����1����ÿ�������Լ��ı��������ļ�.fN
- NumField
- NormGen
- ���ÿ�������Լ��ı��������ļ����������������ÿ�����������ļ��İ汾�ţ�Ҳ��.fN��N��
- IsCompoundFile
- �Ƿ�Ϊ�����ļ���Ҳ����ͬһ�����е��ļ�����һ����ʽ��������һ���ļ����У��������Լ���ÿ�δ��ļ��ĸ�����
- �Ƿ�Ϊ�����ļ������ӿ�IndexWriter.setUseCompoundFile(boolean)�趨��?
- �Ƿ����ļ�ͬ�����ļ��ĶԱ�����ͼ��
�Ǹ����ļ���
?
�����ļ���
?
?
?
- ?
- DeletionCount
- HasProx
- ���������һ����omitTfΪfalse��Ҳ����Ƶ(term freqency)��Ҫ�����棬��HasProxΪ1������Ϊ0��
- Diagnostics
- User map data
- �������û����ַ������ַ�����ӳ��Map
- CheckSum
?
��ȡ���ļ���ʽ�ο�SegmentInfos.read(Directory directory, String segmentFileName):
- int format = input.readInt();
- version = input.readLong(); // read version
- counter = input.readInt(); // read counter
- for (int i = input.readInt(); i > 0; i--) // read segmentInfos
- add(new SegmentInfo(directory, format, input));
- name = input.readString();
- docCount = input.readInt();
- delGen = input.readLong();
- docStoreOffset = input.readInt();
- docStoreSegment = input.readString();
- docStoreIsCompoundFile = (1 == input.readByte());
- hasSingleNormFile = (1 == input.readByte());
- int numNormGen = input.readInt();
- normGen = new long[numNormGen];
- for(int j=0;j
- normGen[j] = input.readLong();
- isCompoundFile = input.readByte();
- delCount = input.readInt();
- hasProx = input.readByte() == 1;
- diagnostics = input.readStringStringMap();
userData = input.readStringStringMap();
final long checksumNow = input.getChecksum();
final long checksumThen = input.readLong();
?
?
4.1.2. ��(Field)��Ԫ������Ϣ(.fnm)
һ����(Segment)���������ÿ������һЩԪ������Ϣ��������.fnm�ļ��У�.fnm�ļ��ĸ�ʽ���£�
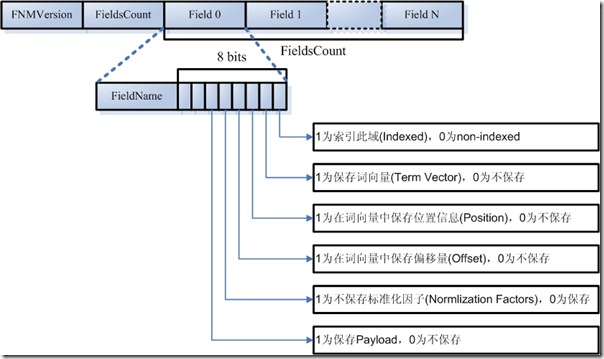
- FNMVersion
- ��fnm�ļ��İ汾�ţ�����Lucene 2.9Ϊ-2
- FieldsCount
- һ���������(Fields)
- FieldName����������"title"��"modified"��"content"�ȡ�
- FieldBits:һϵ�б�־λ�������Դ����������ʽ
- ���λ��1��ʾ����������0����������ν��������Ҳ���ŵ����ű���ȥ��
- ����������������ܹ����ѵ���
- Field.Index.NO���ʾ����������
- Field.Index.ANALYZED���ʾ���������������ұ��ִʣ���������"hello world"����������"hello"��������"world"���ܹ����ѵ���
- Field.Index.NOT_ANALYZED��ʾ��Ȼ�����������Dz��ִʣ���������"hello world"������"hello world"ʱ���ܹ��ѵ�����"hello"����"world"���Ѳ�����
- һ��������ܹ������������ܹ����洢���������洢���������������ģ�������ͨ���ĵ��Ų鵽�������ڲ��뱻��������������ͨ���������ܹ�������������£��ܹ������ĵ��ŷ��ظ��û�����
- Field.Store.Yes���ʾ�洢����Field.Store.NO���ʾ���洢����
- �����ڶ�λ��1��ʾ�����������0Ϊ�������������
- Field.TermVector.YES��ʾ�����������
- Field.TermVector.NO��ʾ�������������
- ��������λ��1��ʾ�ڴ������б���λ����Ϣ��
- Field.TermVector.WITH_POSITIONS
- ��������λ��1��ʾ�ڴ������б���ƫ������Ϣ��
- Field.TermVector.WITH_OFFSETS
- ��������λ��1��ʾ�������������
- Field.Index.ANALYZED_NO_NORMS
- Field.Index.NOT_ANALYZED_NO_NORMS
- ��������λ���Ƿ�payload
?
Ҫ�˽����Ԫ������Ϣ����Ҫ�˽����¼��㣺
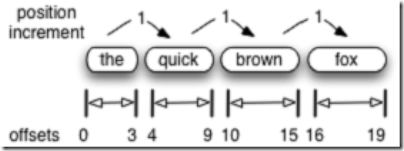
- λ��(Position)��ƫ����(Offset)������
- λ���ǻ��ڴ�Term�ģ�ƫ�����ǻ�����ĸ���ֵġ�
?
- ������(Indexed)�ʹ洢��(Stored)������
- һ����Ϊʲô�ᱻ�洢(store)����������(Index)�أ���һ���ĵ��е�������Ϣ�У�������һ������Ϣ�����ܲ��뱻�����Ӷ����������������ǵ�����ĵ�������������Ϣ��������ʱ������ͬ������Ϣһͬ���ء�
- �ٸ����ӣ����о���ʱ�����ò�����д��һƪ���Ľ������ĵ�ʦ�����ĵ�ʦȴҪ������һ���߶������ڶ����ߣ�Ȼ������ʦ�������������ϵͳ��������������ʱ�ҵ���ƪ���ģ�����������ϵͳ�У��ѵڶ��������Field��Indexed��Ϊfalse���������������������֣���Զ��֪����д����ƪ���ģ�ֻ���ڱ�����������ʦ�����ִӶ��ҵ���������ʱ����һ����������ŵڶ�����������
- payload��ʹ��
- ����֪�����������Ե��ű���ʽ�洢�ģ�����ÿһ���ʣ��������˰�������ʵ�һ����������ȻΪ�˼ӿ��ѯ�ٶȣ�������������Ծ�����д洢��
- Payload��Ϣ���Ǵ洢�ڵ��ű��еģ�ͬ�ĵ���һ���ţ������ڴ洢��ÿƪ�ĵ���ص�һЩ��Ϣ����Ȼ�ⲿ����ϢҲ���Դ洢����(stored Field)�����ߴӹ����ϻ�����һ���ģ�Ȼ����Ҫ�洢����Ϣ�ܶ��ʱ����ڵ��ű��������Ծ���������ڴ����������ٶȡ�
- Payload�Ĵ洢��ʽ����ͼ��
?
- ?
- Payload��Ҫ�����¼����÷���
- �洢ÿ���ĵ����е���Ϣ�������е�ʱ���������ÿ���ĵ���һ�������Լ����ĵ��ţ���������Lucene�Լ����ĵ��š��������ǿ�������һ���������(Field)"_ID"������Ĵ�(Term)"_ID"��ʹ��ÿƪ�ĵ���������"_ID"�������ڴ�"_ID"�ĵ��ű��������ÿƪ�ĵ�����һ�ÿһ���һ��payload���������ǿ�����payload���汣�������Լ����ĵ��š�ÿ�����ǵõ�һ��Lucene���ĵ��ŵ�ʱ���ܴ���Ծ���в��ҵ������Լ����ĵ��š�
//����һ��������������Ĵ�
?
public static final String ID_PAYLOAD_FIELD = "_ID";
public static final String ID_PAYLOAD_TERM = "_ID";
public static final Term ID_TERM = new Term(ID_PAYLOAD_TERM, ID_PAYLOAD_FIELD);
//����һ�������TokenStream����ֻ����һ����(Term)�������Ǹ�����Ĵʣ�������������档
static class SinglePayloadTokenStream extends TokenStream {
??? private Token token;
??? private boolean returnToken = false;
??? SinglePayloadTokenStream(String idPayloadTerm) {
??????? char[] term = idPayloadTerm.toCharArray();
??????? token = new Token(term, 0, term.length, 0, term.length);
??? }
??? void setPayloadValue(byte[] value) {
??????? token.setPayload(new Payload(value));
??????? returnToken = true;
??? }
??? public Token next() throws IOException {
??????? if (returnToken) {
??????????? returnToken = false;
??????????? return token;
??????? } else {
??????????? return null;
??????? }
??? }
}
//����ÿһƪ�ĵ��������������������Ĵʣ��������������
SinglePayloadTokenStream singlePayloadTokenStream = new SinglePayloadTokenStream(ID_PAYLOAD_TERM);
singlePayloadTokenStream.setPayloadValue(long2bytes(id));
doc.add(new Field(ID_PAYLOAD_FIELD, singlePayloadTokenStream));//ÿ���õ�һ��Lucene���ĵ���ʱ��ͨ�����µķ�ʽ�õ�payload������ĵ���
long id = 0;
TermPositions tp = reader.termPositions(ID_PAYLOAD_TERM);
boolean ret = tp.skipTo(docID);
tp.nextPosition();
int payloadlength = tp.getPayloadLength();
byte[] payloadBuffer = new byte[payloadlength];
tp.getPayload(payloadBuffer, 0);
id = bytes2long(payloadBuffer);
tp.close();
?
?
- ?
- ?
- Ӱ��ʵ�����
- ��Similarity���������к���public float scorePayload(byte [] payload, int offset, int length)? ���Ը���payload��ֵӰ�����֡�
- ��ȡ��Ԫ������Ϣ�Ĵ������£�
?
FieldInfos.read(IndexInput, String)
- int firstInt = input.readVInt();
- size = input.readVInt();
- for (int i = 0; i < size; i++)
- String name = input.readString();
- byte bits = input.readByte();
- boolean isIndexed = (bits & IS_INDEXED) != 0;
- boolean storeTermVector = (bits & STORE_TERMVECTOR) != 0;
- boolean storePositionsWithTermVector = (bits & STORE_POSITIONS_WITH_TERMVECTOR) != 0;
- boolean storeOffsetWithTermVector = (bits & STORE_OFFSET_WITH_TERMVECTOR) != 0;
- boolean omitNorms = (bits & OMIT_NORMS) != 0;
- boolean storePayloads = (bits & STORE_PAYLOADS) != 0;
- boolean omitTermFreqAndPositions = (bits & OMIT_TERM_FREQ_AND_POSITIONS) != 0;
?
?
4.1.3. ��(Field)��������Ϣ(.fdt��.fdx)
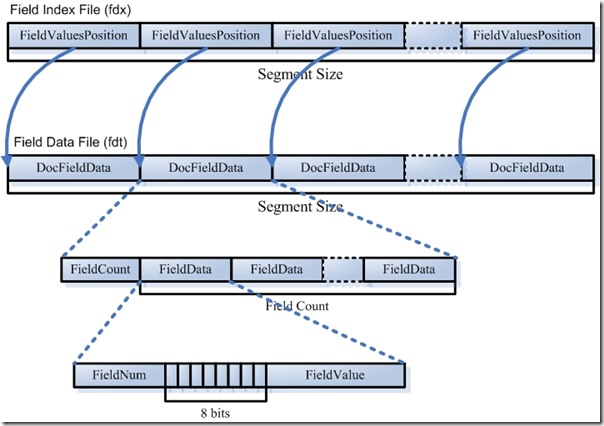
- �������ļ�(fdt):
- ��������洢��(stored field)��Ϣ����fdt�ļ�
- ��һ����(segment)���ܹ���segment sizeƪ�ĵ�������fdt�ļ��й���segment size���ÿһ���һƪ�ĵ��������Ϣ
- ����ÿһƪ�ĵ���һ��ʼ��һ��fieldcount��Ҳ�����ĵ������������Ŀ����������fieldcount���ÿһ���һ�������Ϣ��
- ����ÿһ����fieldnum����ţ�������һ��8λ��byte�����һλ��ʾ�����Ƿ�ִ�(tokenized)�������ڶ�λ��ʾ�����DZ����ַ������ݻ��Ƕ��������ݣ���������λ��ʾ�����Ƿ�ѹ�����ٽ��������Ǵ洢���ֵ������new Field("title", "lucene in action", Field.Store.Yes, ��)����˴���ŵľ���"lucene in action"����ַ�����
- �������ļ�(fdx)
- ���������ļ���ʽ����֪����ÿƪ�ĵ���������ĸ�����ÿ���洢���ֵ���Dz�һ���ģ�����������ļ���segment sizeƪ�ĵ���ÿƪ�ĵ�ռ�õĴ�СҲ�Dz�һ���ģ���ô�����fdt�б��ÿһƪ�ĵ�����ʼ��ַ����ֹ��ַ�أ�����ܹ�������ҵ���nƪ�ĵ��Ĵ洢�����Ϣ�أ�����Ҫ�����������ļ���
- �������ļ�Ҳ�ܹ���segment size���ÿƪ�ĵ�����һ���ÿһ���һ��long����С�̶���ÿһ��Ƕ�Ӧ���ĵ���fdt�ļ��е���ʼ��ַ��ƫ��������������������ҵ���nƪ�ĵ��Ĵ洢�����Ϣ��ֻҪ��fdx���ҵ���n�Ȼ����ȡ����long��Ϊƫ�������Ϳ�����fdt�ļ����ҵ���Ӧ�Ĵ洢�����Ϣ��
- ��ȡ��������Ϣ�Ĵ������£�
?
Document FieldsReader.doc(int n, FieldSelector fieldSelector)
- long position = indexStream.readLong();//indexStream points to ".fdx"
- fieldsStream.seek(position);//fieldsStream points to "fdt"
- int numFields = fieldsStream.readVInt();
- for (int i = 0; i < numFields; i++)
- int fieldNumber = fieldsStream.readVInt();
- byte bits = fieldsStream.readByte();
- boolean compressed = (bits & FieldsWriter.FIELD_IS_COMPRESSED) != 0;
- boolean tokenize = (bits & FieldsWriter.FIELD_IS_TOKENIZED) != 0;
- boolean binary = (bits & FieldsWriter.FIELD_IS_BINARY) != 0;
- if (binary)
- int toRead = fieldsStream.readVInt();
- final byte[] b = new byte[toRead];
- fieldsStream.readBytes(b, 0, b.length);
- if (compressed)
- int toRead = fieldsStream.readVInt();
- final byte[] b = new byte[toRead];
- fieldsStream.readBytes(b, 0, b.length);
- uncompress(b),
- else
- fieldsStream.readString()
?
4.1.3. ������(Term Vector)��������Ϣ(.tvx��.tvd��.tvf)
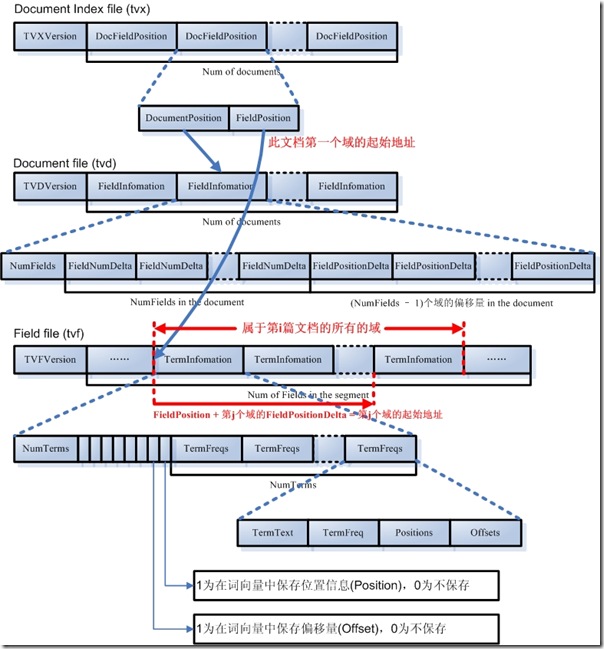
��������Ϣ�Ǵ�����(index)���ĵ�(document)����(field)����(term)��������Ϣ�����˴�������Ϣ�����ǾͿ��Եõ�һƪ�ĵ�������Щ�ʵ���Ϣ��
- �����������ļ�(tvx)
- һ����(segment)����Nƪ�ĵ������ļ�����N�ÿһ�����һƪ�ĵ���
- ÿһ�������������Ϣ����һ�����Ǵ������ĵ��ļ�(tvd)�д��ĵ���ƫ�������ڶ������Ǵ��������ļ�(tvf)�д��ĵ��ĵ�һ�����ƫ������
- �������ĵ��ļ�(tvd)
- һ����(segment)����Nƪ�ĵ������ļ�����N�ÿһ������˴��ĵ������е������Ϣ��
- ÿһ�������Ǵ��ĵ���������ĸ���NumFields��Ȼ����һ��NumFields��С�����飬�����ÿһ������š�Ȼ����һ��(NumFields - 1)��С�����飬��ǰ������֪����ÿƪ�ĵ��ĵ�һ������tvf�е�ƫ������tvx�ļ��б��棬������(NumFields - 1)������tvf�е�ƫ�������ǵ�һ�����ƫ����������(NumFields - 1)�������ÿһ���ֵ��
- ���������ļ�(tvf)
- ���ļ������˴˶��е����е��������ĵ������֣����ڼ����ڼ�������������ƪ�ĵ�������tvx�еĵ�һ�����ƫ�����Լ�tvd�е�(NumFields - 1)�����ƫ�����������ġ�
- ����ÿһ���������Ǵ�������Ĵʵĸ���NumTerms��Ȼ����һ��8λ��byte�����һλ��ָ���Ƿ�λ����Ϣ�������ڶ�λ��ָ���Ƿ�ƫ������Ϣ��Ȼ����NumTerms��������飬ÿһ�����һ����(Term)������ÿһ���ʣ��ɴʵ��ı�TermText����ƵTermFreq(Ҳ���˴��ڴ��ĵ��г��ֵĴ���)���ʵ�λ����Ϣ���ʵ�ƫ������Ϣ��
- ��ȡ������������Ϣ�Ĵ������£�
?
TermVectorsReader.get(int docNum, String field, TermVectorMapper)
- int fieldNumber = fieldInfos.fieldNumber(field);//ͨ��field���ֵõ�field��
- seekTvx(docNum);//��tvx�ļ��а�docNum�ĵ����ҵ���Ӧ�ĵ�����
- long tvdPosition = tvx.readLong();//�ҵ�tvd�ļ�����Ӧ�ĵ���ƫ����
- tvd.seek(tvdPosition);//��tvd�ļ��а�ƫ�����ҵ���Ӧ�ĵ�����
- int fieldCount = tvd.readVInt();//���ĵ���������ĸ�����
- for (int i = 0; i < fieldCount; i++) //����Ų�����
- number = tvd.readVInt();
- if (number == fieldNumber)
- position = tvx.readLong();//��tvx�ж������ĵ��ĵ�һ������tvf�е�ƫ����
- for (int i = 1; i <= found; i++)
- position += tvd.readVLong();//������Ҫ�ҵ�����tvf�е�ƫ����
- tvf.seek(position);
- int numTerms = tvf.readVInt();
- byte bits = tvf.readByte();
- storePositions = (bits & STORE_POSITIONS_WITH_TERMVECTOR) != 0;
- storeOffsets = (bits & STORE_OFFSET_WITH_TERMVECTOR) != 0;
- for (int i = 0; i < numTerms; i++)
- start = tvf.readVInt();
- deltaLength = tvf.readVInt();
- totalLength = start + deltaLength;
- tvf.readBytes(byteBuffer, start, deltaLength);
- term = new String(byteBuffer, 0, totalLength, "UTF-8");
- if (storePositions)
- positions = new int[freq];
- int prevPosition = 0;
- for (int j = 0; j < freq; j++)
- positions[j] = prevPosition + tvf.readVInt();
- prevPosition = positions[j];
- if (storeOffsets)
- offsets = new TermVectorOffsetInfo[freq];
- int prevOffset = 0;
- for (int j = 0; j < freq; j++)
- int startOffset = prevOffset + tvf.readVInt();
- int endOffset = startOffset + tvf.readVInt();
- offsets[j] = new TermVectorOffsetInfo(startOffset, endOffset);
- prevOffset = endOffset;
�ġ������ʽ
?
4.2. ������Ϣ
������Ϣ�������ļ��ĺ��ģ�Ҳ������������
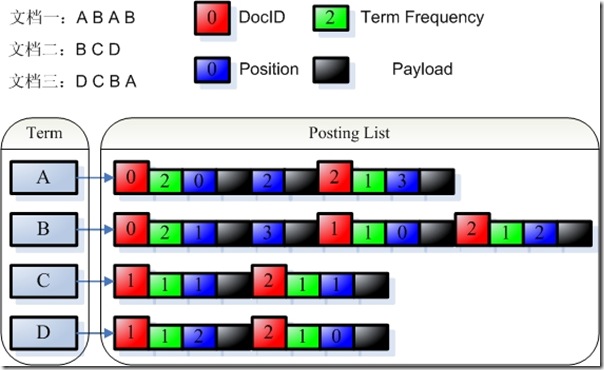
�����������������֣������Ǵʵ�(Term Dictionary)�������ǵ��ű�(Posting List)��
��Lucene�У����������Ƿ��ļ��洢�ģ��ʵ��Ǵ洢��tii��tis�еģ����ű��ְ��������֣�һ�������ĵ��ż���Ƶ��������frq�У�һ�����Ǵʵ�λ����Ϣ��������prx�С�
- Term Dictionary (tii, tis)
- �C> Frequencies (.frq)
- �C> Positions (.prx)
?
4.2.1. �ʵ�(tis)���ʵ�����(tii)��Ϣ
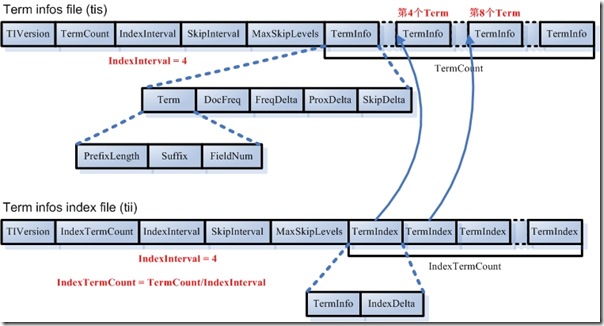
�ڴʵ��У����еĴ��ǰ����ֵ�˳������ġ�
- �ʵ��ļ�(tis)
- TermCount���ʵ��а������ܵĴ���
- IndexInterval��Ϊ�˼ӿ�ԴʵIJ����ٶȣ�ҲӦ��������Ծ���Ľṹ������IndexIntervalΪ4�����ڴʵ�����(tii)�ļ��б����4������8������12���ʣ��������Լӿ��ڴʵ��ļ��в��Ҵʵ��ٶȡ�
- SkipInterval�����ű��������ĵ��ż���Ƶ������λ����Ϣ����������Ծ���Ľṹ���ڵģ�SkipInterval����Ծ�IJ�����
- MaxSkipLevels����Ծ���Ƕ��ģ����ֵָ������Ծ������������
- TermCount��������飬ÿһ�����һ���ʣ�����ÿһ���ʣ���ǰ�������Ŵʵ��ı���Ϣ(PrefixLength + Suffix)�������ڵ�������(FieldNum)���ж���ƪ�ĵ������˴�(DocFreq)���˴ʵĵ��ű���frq��prx�е�ƫ����(FreqDelta, ProxDelta)���˴ʵĵ��ű�����Ծ����frq�е�ƫ����(SkipDelta)������֮������Delta����Ӧ�ò�ֵ����
- �ʵ������ļ�(tii)
- �ʵ������ļ���Ϊ�˼ӿ�Դʵ��ļ��дʵIJ����ٶȣ�����ÿ��IndexInterval���ʡ�
- �ʵ������ļ��ǻᱻȫ�����ص��ڴ���ȥ�ġ�
- IndexTermCount = TermCount / IndexInterval���ʵ������ļ��а����Ĵ�����
- IndexIntervalͬ�ʵ��ļ��е�IndexInterval��
- SkipIntervalͬ�ʵ��ļ��е�SkipInterval��
- MaxSkipLevelsͬ�ʵ��ļ��е�MaxSkipLevels��
- IndexTermCount��������飬ÿһ�����һ���ʣ�ÿһ����������֣���һ�����Ǵʱ���(TermInfo)���ڶ��������ڴʵ��ļ��е�ƫ����(IndexDelta)������IndexIntervalΪ4���������б����4������8������12���ʡ�����
- ��ȡ�ʵ估�ʵ������ļ��Ĵ������£�
?
origEnum = new SegmentTermEnum(directory.openInput(segment + "." + IndexFileNames.TERMS_EXTENSION,readBufferSize), fieldInfos, false);//���ڶ�ȡtis�ļ�
- int firstInt = input.readInt();
- size = input.readLong();
- indexInterval = input.readInt();
- skipInterval = input.readInt();
- maxSkipLevels = input.readInt();
?
SegmentTermEnum indexEnum = new SegmentTermEnum(directory.openInput(segment + "." + IndexFileNames.TERMS_INDEX_EXTENSION, readBufferSize), fieldInfos, true);//���ڶ�ȡtii�ļ�
- indexTerms = new Term[indexSize];
- indexInfos = new TermInfo[indexSize];
- indexPointers = new long[indexSize];
- for (int i = 0; indexEnum.next(); i++)
- indexTerms[i] = indexEnum.term();
- indexInfos[i] = indexEnum.termInfo();
- indexPointers[i] = indexEnum.indexPointer;
?
4.2.2. �ĵ��ż���Ƶ(frq)��Ϣ
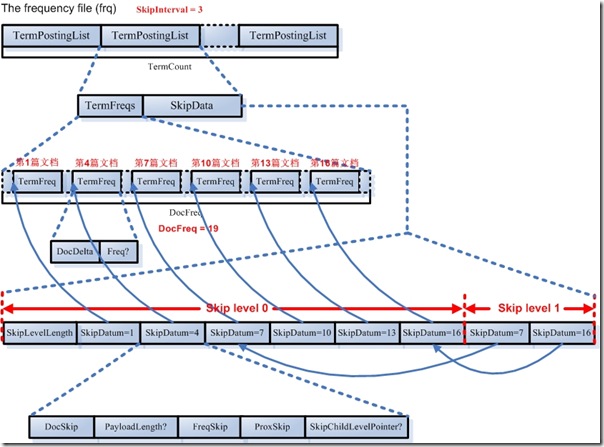
�ĵ��ż���Ƶ�ļ����汣����ǵ��ű���������Ծ����ʽ���ڵġ�
- ���ļ�����TermCount���ÿһ���ʶ���һ���Ϊÿһ���ʶ����Լ��ĵ��ű���
- ����ÿһ���ʵĵ��ű������������֣�һ�����ǵ��ű�������Ҳ��һ��������ĵ��ż���Ƶ����һ��������Ծ����Ϊ�˸���ķ��ʺͶ�λ���ű����ĵ��ż���Ƶ��λ�á�
- �����ĵ��źʹ�Ƶ�Ĵ洢Ӧ�õ��Dz�ֵ����ͻ�Ȼ�������Lucene���ĵ����������¼��仰���Ƚ��������⣬�ڴ˽���һ�£�
?
For example, the TermFreqs for a term which occurs once in document seven and three times in document eleven, with omitTf false, would be the following sequence of VInts:
15, 8, 3
If omitTf were true it would be this sequence of VInts instead:
7,4
�������ǿ�omitTf=false�������Ҳ�������������л�洢һ���ĵ���term���ֵĴ�����
������˵�ˣ���ʾ���ĵ�7�г���1�Σ����������ĵ�11�г���3�ε��ĵ����������б�ʾ��15��8��3.
����������������ô����������أ�
���ȣ����ݶ���TermFreq --> DocDelta[, Freq?]��һ��TermFreq�ṹ����һ��DocDelta�����������Freq��ɣ�Ҳ����������˵��A+B���ṹ��
DocDelta��Ȼ����洢������Term���ĵ���ID���ˣ�Freq���ڴ��ĵ��г��ֵĴ�����
���Ը������ӣ�Ӧ�ô洢��������ϢΪ[DocID = 7, Freq = 1] [DocID = 11,? Freq = 3](��ȫ�ļ����Ļ���ԭ���½�)��
Ȼ��Ϊ�˽�ʡ�ռ䣬Lucene�Ա�Ŵ�������ݶ����ò�ֵ����ʾ�ģ�Ҳ������˵�Ĺ���2��Delta���������ĵ�ID�Ͳ��ܰ�������Ϣ���ˣ���Ӧ�ô�����£�
[DocIDDelta = 7, Freq = 1][DocIDDelta = 4 (11-7), Freq = 3]
Ȼ��Lucene����A+B?���ֻ�Ȼ����Ľ������������Ĵ洢��ʽ��������3����A+B?�������DocDelta��������FreqΪ1������DocDelta���һλ��1��ʾ��
���DocDelta��������Freq����1����DocDelta�����һλ��0��Ȼ��������������ֵ���Ӷ����ڵ�һ��Term������FreqΪ1�����Ƿ���DocDelta�����һλ��ʾ��DocIDDelta = 7�Ķ�������000 0111������Ҫ����һλ�������һλ��һ��000 1111 = 15�����ڵڶ���Term������Freq����һ�����Ƿ���DocDelta�����һλ���㣬DocIDDelta = 4�Ķ�������0000 0100������Ҫ����һλ�������һλ���㣬0000 1000 = 8��Ȼ��������������Freq = 3��
���ǵõ����У�[DocDleta = 15][DocDelta = 8, Freq = 3]��Ҳ�����У�15��8��3��
���omitTf=true��Ҳ�����Dz��������д洢һ���ĵ���Term���ֵĴ�������ֻ��DocID�Ϳ����ˣ����������A+B?�����Ӧ�á�
[DocID = 7][DocID = 11]��Ȼ��Ӧ�ù���2��Delta�������ǵõ�����[DocDelta = 7][DocDelta = 4 (11 - 7)]��Ҳ�����У�7��4.
- ������Ծ���Ĵ洢�����¼�����Ҫ����һ�£�
- ��Ծ���ɸ��ݵ��ű������ij���(DocFreq)����Ծ�ķ���(SkipInterval)���ֲ�ͬ�IJ�Σ������ΪNumSkipLevels = Min(MaxSkipLevels, floor(log(DocFreq/log(SkipInterval)))).
- ��Level��Ľڵ���ΪDocFreq/(SkipInterval^(Level + 1))��level���������
- ������߲�֮�⣬�����㶼��SkipLevelLength����ʾ�˲�Ķ����Ƴ���(���ǽڵ�ĸ���)�������ȡijһ�����Ծ�����������档
- �Ͳ���ǰ���߲��ں��������еĵͲ��ʣ�µľ������һ�㣬������һ�㲻��ҪSkipLevelLength����Ҳ��ΪʲôLucene�ĵ��еĸ�ʽ����Ϊ NumSkipLevels-1, SkipLevel��Ҳ����NumSKipLevels-1����SkipLevelLength�����һ��ֻ��SkipLevel��û��SkipLevelLength��
- ����Ͳ����⣬�����㶼��SkipChildLevelPointer��ָ����һ����Ӧ�Ľڵ㡣
- ÿһ����Ծ�ڵ����������Ϣ���ĵ��ţ�payload�ij��ȣ��ĵ��Ŷ�Ӧ�ĵ��ű��еĽڵ���frq�е�ƫ�������ĵ��Ŷ�Ӧ�ĵ��ű��еĽڵ���prx�е�ƫ������
- ��ȻLucene���ĵ��������µ�������Ȼ��ʵ��Ľ��ȴ������ȫȷ�ģ�
?
Example: SkipInterval = 4, MaxSkipLevels = 2, DocFreq = 35. Then skip level 0 has 8 SkipData entries, containing the 3rd, 7th, 11th, 15th, 19th, 23rd, 27th, and 31st document numbers in TermFreqs. Skip level 1 has 2 SkipData entries, containing the 15th and 31st document numbers in TermFreqs.
������������SkipIntervalΪ4������35ƪ�ĵ���ʱ��Skip level = 0Ӧ�ð�����3����7����11����15����19����23����27����31ƪ�ĵ���Skip level = 1Ӧ�ð�����15����31ƪ�ĵ���
Ȼ��������ʵ���У���Ծ���ڵ��ʱ��ȴ��ǰƫ���ˣ�ƫ�Ƶ�ԭ����������Ĵ��룺
- FormatPostingsDocsWriter.addDoc(int docID, int termDocFreq)
- final int delta = docID - lastDocID;
- if ((++df % skipInterval) == 0)
- skipListWriter.setSkipData(lastDocID, storePayloads, posWriter.lastPayloadLength);
- skipListWriter.bufferSkip(df);
?
�Ӵ����У����ǿ��Կ�������SkipIntervalΪ4��ʱ��docID = 0ʱ��++dfΪ1��1%4��Ϊ0��������Ծ�ڵ㣬��docID = 3ʱ��++df=4��4%4Ϊ0��Ϊ��Ծ�ڵ㣬Ȼ��skipData���汣���ȴ��lastDocIDΪ2��
���������ĵ��ű�����Ծ���б���һ�µ���Ϣ��

?
4.2.3. ��λ��(prx)��Ϣ
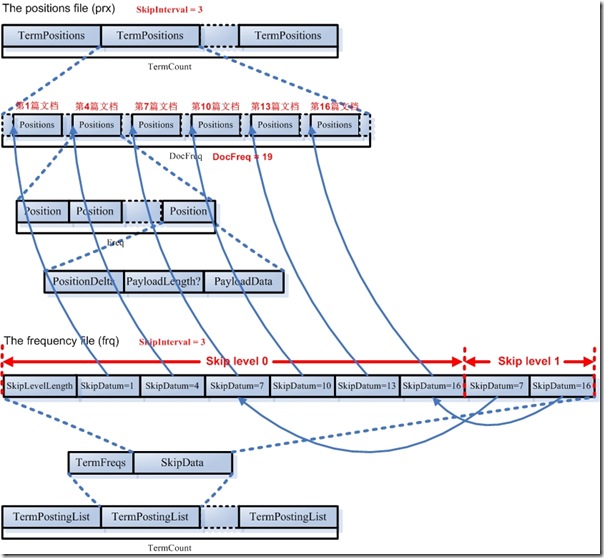
��λ����ϢҲ�ǵ��ű���Ҳ������Ծ����ʽ���ڵġ�
- ���ļ�����TermCount���ÿһ���ʶ���һ���Ϊÿһ���ʶ����Լ��Ĵ�λ�õ��ű���
- ����ÿһ���ʵĶ���һ��DocFreq��С�����飬ÿ�����һƪ�ĵ�����¼���ĵ��д˴ʳ��ֵ�λ�á�����ĵ�����Ҳ�Ǻ�frq�ļ��е���Ծ���й�ϵ�ģ�����������֪������frq����Ծ���ڵ�����ProxSkip����SkipIntervalΪ3��ʱ��frq����Ծ���ڵ�ָ��prx�ļ��еĴ������еĵ�1����4����7����10����13����16ƪ�ĵ���
- ����ÿһƪ�ĵ������ܰ���һ���ʶ�Σ������һ��Freq��С�����飬ÿһ������˴��ڴ��ĵ��г���һ�Σ�����һ��λ����Ϣ��
- ÿһ��λ����Ϣ������PositionDelta(���ò�ֵ����)�������Ա���payload��Ӧ�û�Ȼ�������
?
4.3. ������Ϣ
4.3.1. ���������ļ�(nrm)
Ϊʲô���б��������أ��ӵ�һ���е�����������֪���������������У����������ĵ�Ҫ�����ѯ�����������������Դ�Ĵ��(score)�ߣ��Ӷ�����ǰ�档����Դ��(score)ʹ�������ռ�ģ��(Vector Space Model)���ڼ��������֮ǰ��Ҫ����Term Weight��Ҳ��ijTerm�����ijDocument����Ҫ�ԡ��ڼ���Term Weightʱ����Ҫ������Ӱ�����أ�һ���Ǵ�Term�ڴ��ĵ��г��ֵĴ�����һ���Ǵ�Term����ͨ�̶ȡ���Ȼ��Term�ڴ��ĵ��г��ֵĴ���Խ�࣬��Term�ڴ��ĵ���Խ��Ҫ��
����Term Weight�ļ��㷽��������ͨ�ģ�Ȼ���������¼������⣺
- ��ͬ���ĵ���Ҫ�Բ�ͬ���е��ĵ���ҪЩ���е��ĵ���Բ���Ҫ����������������ģ��������鼮��ʱ�������ü�����������������ѵ�������ѧ������鼮����ʱ��������
- ��ͬ������Ҫ�Բ�ͬ���е�����ҪһЩ�����ؼ���������⣬�е�����ҪһЩ���總���ȡ�ͬ��һ����(Term)�������ڹؼ�����Ӧ�ñȳ����ڸ����д��Ҫ�ߡ�
- ���ݴ�(Term)���ĵ��г��ֵľ��Դ����������˴ʶ��ĵ�����Ҫ�ԣ��в������ĵط������糤���ĵ������ĵ��г��ֵĴ�����Խ϶࣬�����̵��ĵ��ȽϳԿ�������һ������һ��שͷ���г�����10�Σ�������һƪ����100�ֵ������г�����9�Σ���˵��שͷ��Ӧ������ǰ���룿��Ӧ�ã���Ȼ�˴��ڲ���100�ֵ��������ܳ���9�Σ��ɼ���Դ����µ���Ҫ�ԡ�
?
��������ԭ��Lucene�ڼ���Term Weightʱ���������һ����������(Normalization Factor)���������������������Ӱ�졣
��������(Normalization Factor)�ǻ�Ӱ�������(score)�ļ���ģ�Lucene�Ĵ�ּ���һ���ַ��������������У�һ�������ѯ����صIJ�����������ӣ��ַ��������������У������������̵Ĵ��������������
��������(Normalization Factor)�����������ܵļ������£�

����������������
- Document boost����ֵԽ��˵�����ĵ�Խ��Ҫ��
- Field boost������Խ��˵������Խ��Ҫ��
- lengthNorm(field) = (1.0 / Math.sqrt(numTerms))��һ�����а�����Term����Խ�࣬Ҳ���ĵ�Խ������ֵԽС���ĵ�Խ�̣���ֵԽ��
?
������Ĺ�ʽ������֪����һ����(Term)�����ڲ�ͬ���ĵ���ͬ�����У��������Ӳ�ͬ�������������ĵ���ÿ���ĵ�������������������ĵ����ȣ���������������ϣ�����Ҫ�ĵ�����Ҫ���У�����Ҫ�ĵ��ķ���Ҫ���У��ڷ���Ҫ�ĵ�����Ҫ���У��ڷ���Ҫ�ĵ��ķ���Ҫ���У�������ϣ�ÿ���в�ͬ�ı������ӡ�
������Lucene�У��������ӹ�������(�ĵ���Ŀ��������Ŀ)������ʽ���£�
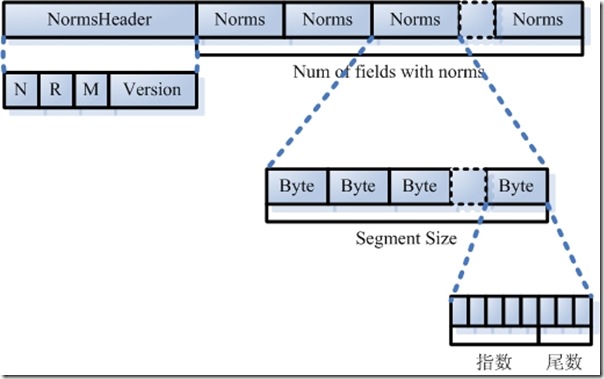
- ���������ļ�(Normalization Factor File: nrm)��
- NormsHeader���ַ�����NRM�����Version����Lucene�İ汾�IJ�ͬ����ͬ��
- ������һ�����飬��СΪNumFields��ÿ��Fieldһ�ÿһ��Ϊһ��Norms��
- NormsҲ��һ�����飬��СΪSegSize�����˶����ĵ���������ÿһ��Ϊһ��Byte����ʾһ��������������0~2Ϊβ����3~8Ϊָ����
?
4.3.2. ɾ���ĵ��ļ�(del)
?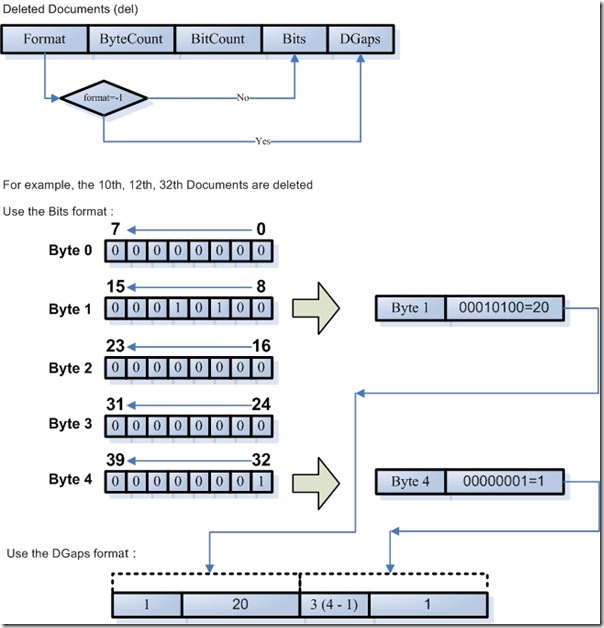
- ��ɾ���ĵ��ļ�(Deleted Document File: .del)
- Format���ڴ��ļ��У�Bits��DGapsֻ�ܱ�������֮һ��-1��ʾ����DGaps���Ǹ�ֵ��ʾ����Bits��
- ByteCount���˶����ж����ĵ������ж��ٸ�bit�����棬������byte��ʽ������Ҳ��Bits�Ĵ�СӦ����byte�ı�����
- BitCount��Bits���ж���λ����1����ʾ���ĵ��Ѿ���ɾ����
- Bits��һ�������byte����СΪByteCount��Ӧ��ʱ����Ϊ��byte*8��bit��
- DGaps�����ɾ�����ĵ�������С����Bits��λΪ0�����˷ѿռ䡣DGaps�������µķ�ʽ������ϡ�����飺�����ʮ��ʮ������ʮ�����ĵ���ɾ�������ǵ�ʮ��ʮ������ʮ��λ��Ϊ1��DGapsҲ����byteΪ��λ�ģ������治Ϊ0��byte�����1��byte����4��byte����1��byteʮ����Ϊ20����4��byteʮ����Ϊ1�����DZ����DGaps����1��byte��λ��1�ò��������������棬ֵΪ20�ö����Ʊ��棬��2��byte��λ��4�ò��������������棬�ò�ֵΪ3��ֵΪ1�ö����Ʊ��棬���������ݲ��ò�ֵ��ʾ��
?
�塢����ṹ
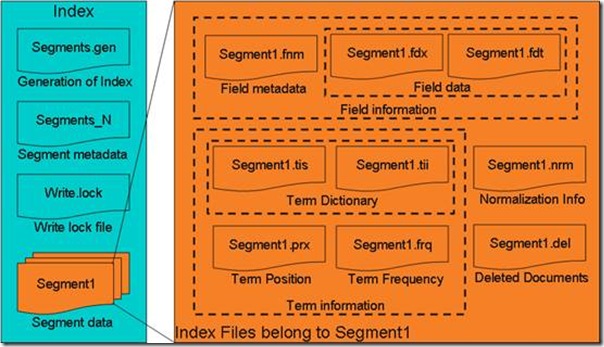
?
?
?
?
- ͼʾΪLucene�����ļ�������ṹ��
- ������������(Index)��segment.gen��segment_N���䱣����Ƕ�(segment)��Ԫ������Ϣ��Ȼ��ֶ��segment����������Ϣ��ͬһ��segment����ͬ��ǰ�ļ�����
- ����ÿһ���Σ���������Ϣ������Ϣ���Լ�������Ϣ(�������ӣ�ɾ���ĵ�)
- ����ϢҲ�������Ԫ������Ϣ����fnm�У����������Ϣ����fdx��fdt�С�
- ����Ϣ�Ƿ�����Ϣ�������ʵ�(tis, tii)���ĵ��ż���Ƶ���ű�(frq)����λ�õ��ű�(prx)��
?
��ҿ���ͨ����Դ���룬��Ӧ��Reader��Writer���˽��ļ��ṹ������Ϊ����