(转载)
在去年(其实只是半个月前而已),Tomcat就紧急发布
安全漏洞通知,同时微软也发布了相应的安全漏洞通知,
他们都是通过变通的方式来解决此拒绝服务漏洞。而在这风口浪的碰撞拒绝服务漏洞是什么呢?
1.什么是HashTable 碰撞?
我觉得有必要先阐述一下什么是HashTable碰撞,因为这个拒绝服务漏洞不是因为服务器的
编码原因或是
疏忽造成的,而是程序语言自身的问题,此问题除了perl,ruby外,几乎无一幸免,可怜的JAVA当然也在其中了.
HashTable是原意是将所有数据能足够散列的以键值对的形式存在,这样能极大的提高读取效率又能有一定的
安全性,哪怕被截了包也不会轻易的让人读出数据。
在java中:
Hashtable<String,String> hashTable = new Hashtable<String,String>();
hashTable.put("test123", "123");
上面的代码,展示了JAVA如何进行HASH键值的存储,其中dreamforce是key,me代表value,这个key在放入hashtable时,会进行hash加密转换成hash码,但是知道HASH加密
算法的都知道,hash密文和hash明文绝对会存在一对多的关系,也就是说现实生活中一定会有几条数据hash加密后产生的hash值是一样的,这是必然的结果。那么hash就从此不再安全了吗?其实不然,只是说这种必然的概率相当的小,同时我们在进行hash算法的时候也一定要会使这种必然事件的概率降到最低,这才是一个极好的hash加密算法.
那么一旦这种必然条件触发后,就会引起了所谓的碰撞:
这种碰撞的出现要满足两个条件,key的真实值必须要不同,因为相同的key值会被hash表给过滤掉,其二就是key值的hashcode一定要一样,举例说明:
在JAVA中,Aa 和 BB这两个值的hashcode是一样的,都是2112, 有兴趣的同学可以试试
那么如果我进下以下的编码,大家会看到一个很诡异的事情:
Hashtable<String,String> hashTable = new Hashtable<String,String>();
hashTable.put("test123", "123");
hashTable.put("Aa", "456");
hashTable.put("BB", "789");
通过调试,你们可以看到不一样的地方:
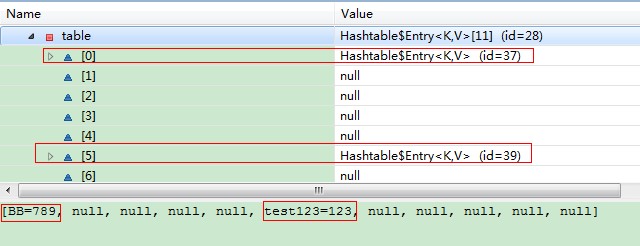
在上图中,你们可以看到 table中,只有两条记录存在 (BB=789, test123=123),按道理来说,应该是三条,那么有一条记录(Aa=456)去了哪里了?

通过上图,大家应该恍然大悟了,那一条记录并没有消失,而是变成了链表结构追加到了key=BB 这条记录的下一个节点之上。。这样就打破了hashtable的结构,如果有N条这样的碰撞出现,那么hashTable的效率也将荡然无存了.数据就成了链表结构,而这时要获取一个在链表之上的节点的value,就会进行N次迭代进行获取,那么算法效率就从o(1)变成了o(n)……..
2.拒绝服务式攻击
接着上面阐述了hashTable的碰撞原理后,各位同学们也应该了解了这个拒绝服务式攻击了吧,其实就是因为这个hashTable的漏洞的存在,如果有人通过传递精心设计好的可以产生碰撞的超大数据,那么就会导致服务器不断的进行迭代读取,CPU一下子就会被全额占满,这是相当恐怖的。有数据说,10kb的数据量就会导致一个i7的CPU马上占用率飙升100%,本人没有试过,但也相信应该差不多..
3.如何是好?
关于tomcat 以及微软的解决之道就是很变通的告知大家,将请求参数据
缓存值设小,也就是说,一次性的请求量不会导致CPU被全部占满。。。其实这也是无奈之举。
除此之外,就是设计好HASH算法,一定要保证必然碰撞事件的概率降低,也就是说提高生产位数,带来的痛苦就是请求效率降低。各有取舍吧,
鱼与熊掌不可兼得.
做好
异常检测,不要来者不拒,还是要理性的区分正常与恶意的数据请求.
==========================================
另外我验证以上说法的时候,碰到一个问题:
Hashtable<String,String> hashTable = new Hashtable<String,String>();
hashTable.put("test", "123");
hashTable.put("Aa", "456");
hashTable.put("BB", "789");
在JAVA中,Aa和BB的hashcode是一样的,都是2112,而test的hashcode是3556498。奇怪的现象发生了。(由于不懂原理,只能称之为“奇怪现象”)如下图:
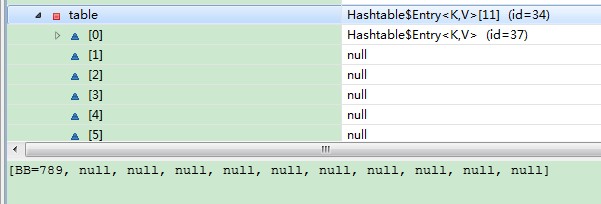
在上图中,hashtable中只有一条记录(BB=789),test的记录到哪里去了呢。请看下图:
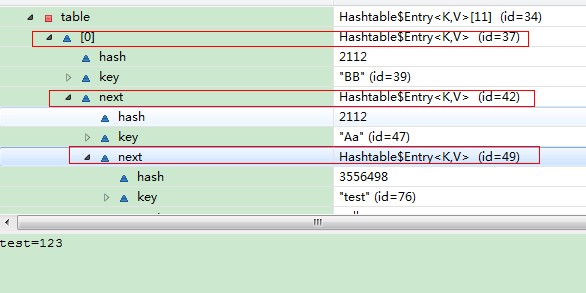
为什么test会追加到Aa后面呢?他们的hashcode又不相同?

- 大小: 39.5 KB

- 大小: 36 KB

- 大小: 26.8 KB

- 大小: 42.2 KB




