好久没写技术博客了,今天
兴起写上一篇。
最近安排新来的同事写爬虫抓站,咨询我如何对ajax型的网页数据进行抓取。比如http://www.chewen.com这个站点,“更多
新问题”就是发送的ajax请求。
其实抓ajax的页面和抓普通的页面区别不大。ajax只不过是做了一次
异步的http请求,只要使用firebug类似的工具,找到请求的后端服务url和传值的参数,然后对该url传递参数进行抓取即可。利用firebug的网络工具,如图所示:
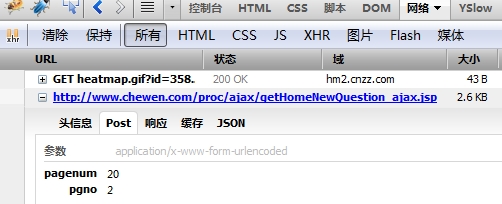
下面代码就是以车问网站为例,通过curl发送POST请求,获取一页的数据。(其实该url的数据可以直接通过GET获取)
<?php
$opt = "http://www.chewen.com/proc/ajax/getHomeNewQuestion_ajax.jsp";
$post = "lastqid=50934&pgno=1&pagenum=20";
$curl = curl_init();
curl_setopt($curl, CURLOPT_RETURNTRANSFER, true);
curl_setopt($curl, CURLOPT_POST, 1);
curl_setopt($curl, CURLOPT_POSTFIELDS, $post);
curl_setopt($curl, CURLOPT_URL, $opt);
$rs = curl_exec($curl);
$rs = json_decode($rs);
var_dump($rs);
?>
每次只需要更改参数pgno就相当于更改了分页的页码,然后再经行处理就与抓普通的列表页无异了。

- 大小: 75 KB