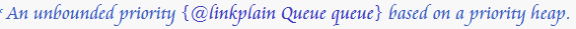要去哪里找 像你这么好 ――从堆到优先队列的实现_JAVA_编程开发_程序员俱乐部
中国优秀的程序员网站
程序员频道
CXYCLUB技术
地图
最新资讯
|
百度新闻
|
GOOGLE地图
|
RSS订阅
|
更多
职场话题
生活休闲
恋爱交友
程序人生
学习进修
职业发展
项目管理
求职面试
程序员创业
JAVA
.NET
C/C++
Ruby
Delphi
JavaScript
PHP
ASP
JSP
HTML
XML
移动开发
开发工具
其他
编程开发
数据库
操作系统
新闻资讯
互联网
非技术区
非技术区
生活休闲
恋爱交友
职业发展
求职面试
程序人生
移动开发
开发工具
DB2
MySql
Sybase
开发
JAVA
.NET
PHP
C/C++
数据库
SQL Server
Oracle
互联网
运营
推广
营销
SEO
系统
Linux
Unix
Windows
资讯
动态
产品
人物
创业
职场
学习
管理
热搜:
异步
同步
编码
冒泡排序
下拉联动
序列化
回调机制
Maven
版本
端口扫描
Flex
Play框架
加密解密
J2EE
缓存
异步
同步
编码
冒泡排序
下拉联动
序列化
回调机制
Maven
版本
端口扫描
更多>>
您所在的位置:
程序员俱乐部
>
编程开发
>
JAVA
> 要去哪里找 像你这么好 ――从堆到优先队列的实现
要去哪里找 像你这么好 ――从堆到优先队列的实现
2011/12/2 7:30:30 风子柒 http://februus.iteye.com
我要评论(
0
)
摘要:
优先队列,顾名思义,就是一种根据一定优先级存储和取出数据的队列。它可以说是队列和排序的完美结合体,不仅可以存储数据,还可以将这些数据按照我们设定的规则进行排序。先说说优先队列的实现吧。有一点需要澄清,很多人一直以为PriorityQueue就是一个PriorityHeap,这种说法当然是片面的。既然优先队列只是存储数据和排序的结合,那么根据我们学过的知识,可以列出以下的实现方法:无序数组、无序链表、有序数组、有序链表以及二叉查找树,当然还有堆。这些方法在实现中当然也有优先级
标签:
实现
队列
优先
队列
,顾名思义,就是一种根据一定优先级存储和取出数据的队列。它可以说是队列和排序的完美
结合
体,不仅可以存储数据,还可以将这些数据按照我们设定的规则进行排序。
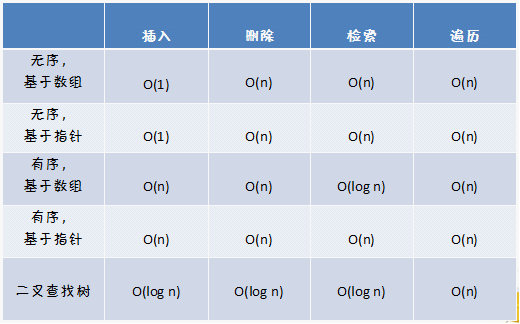
先说说优先队列的实现吧。有一点需要澄清,很多人一直以为Priority Queue就是一个Priority Heap,这种说法当然是片面的。既然优先队列只是存储数据和排序的结合,那么根据我们学过的知识,可以列出以下的实现方法:无序数组、无序链表、有序数组、有序链表以及二叉查找树,当然还有堆。这些方法在实现中当然也有优先级,下表就是一些方法的实现基本操作的时间性能对比:
图1.一些优先队列的实现方案的时间性能对比
从这张表里我们可以按照时间复杂度这个优先级来进行一次排序,当然,你会选用最后一种二叉查找树作为实现优先队列的方案,但是实际上我们采用的是堆。堆,就是一种
has
hu.html" target="_blank">二叉树,堆和二叉查找树是类似的,但是也有些许不同:从形状来看,二叉查找树可以有不同的形状,而堆只能是完全二叉树;在时间性能上,二者并无明显的区别。堆也是有序的,我们一般将其分为大顶堆和小顶堆。小顶堆,顾名思义,就是这个堆的子结点的值小于父结点的值;相反的,大顶堆就是堆的子结点的值都大于父结点的值。
在实现的时候,我们常常使用基于数组的堆,即堆中的元素保存在一个数组中,而这个数组元素的保存也是按照一定规律的:如果父结点的位置为n,那么,其对应的左右子结点的位置分别是2n+1和2n+2。也就是说,我们在视觉上(如果用
画图
形象化表示堆的话)和本质上将堆打扮成两种东西,这样既便于
理解
,也利于实现,本质的实现是用数组是因为考虑到数组的一些性能。
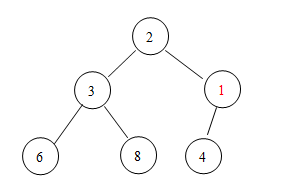
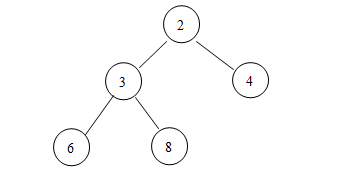
堆有两个很基本的操作:增加、删除。先来说说增加元素,假设有下面这样一个堆:
这时候,有一个元素1要添加进来,这时候应该怎么办呢?第一步,将元素添加到堆的最后一个位置:
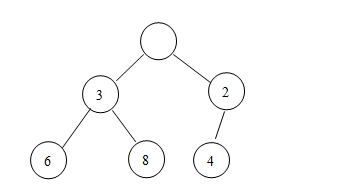
第二步,将新加入的元素与其父结点的值进行比较,若新结点的值比其父结点的值要小(就像这个
例子
一样),那么,交换两个结点的值,重复第二步,直到形成一个小顶堆:
这样,一个新的小顶堆诞生了!
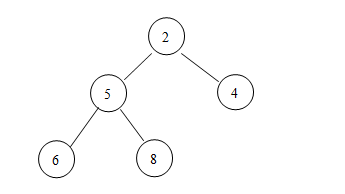
然后就是从堆中删除一个元素了,假设在这个新的小顶堆中,我们
打算
删除值为1的那个结点:
第一步,将这个1删掉,假设其结点上当前没有值:
第二步,比较该删除结点(当前是最上面的那个)的两个子结点,看谁的值小,交换其中较小值和这个空结点的值(假设是null),然后重复这一步,直到该空值到最小面一行:
第三步,就是将这个空的结点从视线中移除了,这样,删除的过程就告一段落了(好吧,这个堆又回到解放前了)!
知道了这些基本的原理,对数据量更大的增加和删除也应该是触类旁通了吧。
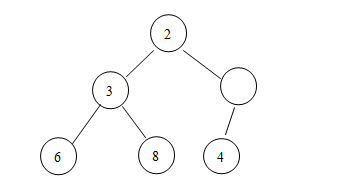
有人会质疑堆中除堆顶元素之外的其他元素的顺序问题:
比如这里为什么4会放在5的右边兄弟结点上,这明显是受了二叉查找树的影响,因为堆对我们来说,一般只有堆顶元素有用,因此只要保证堆顶元素是最小的就行了(对小顶堆)。
下面,简单介绍一下sun提供的PriorityQueue的一些基本的方法,以此来较为深入地理解优先队列的实现机制:
1.下面是PriorityQueue的声明的第一句话:
这句话表明:sun提供的优先队列是基于优先堆实现的;
2.下面是声明一个Object数组时的
注释
:
由此可知,堆中的元素在数组中的保存方案;并且队列中的优先级最小的元素总是保存在queue[0]中,前提是该优先队列不为空。
下面是往PriorityQueue中上滤的方法:
这段代码中,k代表当前加入元素的位置,即最后一个位置+1,x表示要添加的元素。首先得到父结点的值,然后将x的值和父结点的值进行比较,如果子结点的值大于父结点值,不作更改,否则交换两者的值。这个方法主要用于添加元素的时候。与之相对应的有一个下滤方法siftDownComparable(),其功能是向下比较,用在删除元素的实现中;
接下来就讲添加元素的实现:
这里可以看到用到了siftUp方法,其实,siftUp中分情况调用了 siftUpUsingComparator()、siftUpComparable()。这在刚才已经介绍了上滤的实现了。这里的添加元素就是上滤的过程。
当然,我们在使用时,一般使用的方法是这三种:add、poll以及peek,add用以添加元素,其内部是用offer方法实现的,peek用来得到堆顶元素,但是不删除,而poll在返回堆顶元素之后,将堆顶元素删除。
以上只是对优先队列的简要介绍,作为一个应用比较广泛的数据结构,优先队列还有许许多多奇妙的地方,它们都等着你去
发现
。
大小: 19.3 KB
大小: 5.1 KB
大小: 5.8 KB
大小: 5.4 KB
大小: 5.6 KB
大小: 5.8 KB
大小: 5.7 KB
大小: 5.8 KB
大小: 5.4 KB
大小: 5.4 KB
大小: 9.3 KB
大小: 15.7 KB
大小: 17.4 KB
大小: 16.4 KB
查看图片附件
上一篇:
用POI生成Excel文件的典型例子【基于poi3.0 附源码】
下一篇:
EhCache之初试
相关文章
・
Java实现二维码QRCod
・
Java多线程 Web服务
・
Java 实现 FTP上传下
・
使用AutoMapper实现
・
使用AutoMapper实现
・
使用AutoMapper实现
・
在Windows下配置VIM
・
365测压网程序语言实现及网
・
实现多域名下共用一个SESS
・
项目代码行统计工具(Java
查看所有评论(
0
)
我要评论
发表评论
用户名:
匿名
最新文章
J..
h..
・
后台json传递
・
Java实现二维码QRCod
・
Java面向对象(讲义)请各
・
在HBase中应用MemSt
・
java继承中的一些 错误认
・
JXL copySheet
・
在CMD下对Java程序的调
・
同步与异步--阻塞与非阻塞
・
JDBC连接各种数据库
・
Java 对象句柄
・
jna调用dll文件遇见问题
・
hadoop0.20.1在c
・
JSTL一些详细解析
・
Java多线程 Web服务
・
word,ppt,excel
最新标签
异步
同步
编码
冒泡排序
下拉联动
序列化
回调机制
Maven
版本
端口扫描
今日热点
・
全面认识Eclipse中JVM内存设置
・
struts标签实现菜单动态级联
・
JDK1.6官方下载地址
・
后台json传递
・
Java实现二维码QRCod
・
Java面向对象(讲义)请各
・
在HBase中应用MemSt
・
java继承中的一些 错误认
・
JXL copySheet
・
在CMD下对Java程序的调
推荐文章
unable ..
老..
・
The last pack
・
unable to find valid
・
老三携剑出山,Swing法力
・
java poi 创建exc
・
Errors occurre
・
[linux]ubuntu下
・
java 两数相除 四舍五入
・
Java 调用远程webservice接
・
Hadoop学习全程记录――
・
JAVA 比较两张图片的相似
・
J2EE、JAVA开源版OA发布了(JO
・
在linux下用tomcat
・
异常ognl.OgnlExc
・
Eclipse设置Tomcat启动超时时
・
org.springfra
English
|
关于我们
|
诚聘英才
|
联系我们
|
网站大事
|
友情链接
|
意见反馈
|
网站地图
Powered by
程序员俱乐部
程序提供: HugoCMS 2.0
网站备案:苏ICP备11048748号-1