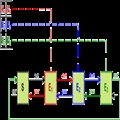
Hash表的基本思想是:
?? 将一组数存放到hash表中,我们使用一个函数,叫做hash函数,它的自变量是这些数据,它的函数值就是这个数据在hash表中的位置。因此这个hash函数又叫做hash地址。
?? 使用这样的函数,我们必然会设想到这样的一个问题,就是函数值相同。也就是两个不同的数据具有相同的位置,这显然是有问题的。这对于存储数据来说是不允许的。我们把上面的的这种情况叫做hash冲突,而出现这种情况的数据对象(hash函数的自变量)我们把它们称之为同义词,那么这种冲突又叫做同义词冲突。这个问题出现的原因是在这个hash函数身上。但是在实际情况下这个问题的还有别的原因。我们先这样理解:我们要存放数据的空间是不够的,那么这样以来理论上必然有些数据的是要放在一起的。当然这是一种错的理解。事实上空间肯定是够的。不过我们要知道这样的一件事:数据的取值的区间是一定比hash函数的变化范围大的。那么自然我们是要开辟新的空间来保证数据的存储。可能说的有点多,总结一下两个概念:1hash函数,2hash冲突。(胡哥说,我们对一个新的概念真正理解的标准是离开术语,最好是用比喻的方式谈自己的观点。显然根据这个标准我是没有理解这两个概念的,但是我这样认为,胡哥的标准是一种高的标准。那么就会存在中间的一个标准:就是把这些知识在自己的脑海沉淀一下,然后能有自己的理解,尽管和书上或者和别人讲的有些雷同,这就可以表示我们达到了中间的那个标准(虽然是雷同,但毕竟是自己虚构的吗呵呵)。有些问题,我们一开始不可能马上就达到胡哥所倡导的标准。不过我们需要先达到某个标准。)
对于这个hash表?呢,我只是根据我的理解,写了一下。其中的很多东西,是没有用到的,比如hash函数的创建方法,有好多种,显然我只用了一种。不过可从感性上先了解了解,别的方法的思想也是不错的,以后用到的话也不会陌生。
hash函数的构造方法:
1.是直接定址法:
它的计算法hash地址的方法就是,对关键字做一个简单的加法运算。公式是:h(k)=k+c;
这个方法的应用环境就是关键字的分布比较连续的时,因为不连续的话,就会造成资源的浪费。而且这种方法,是不会产生hash冲突的。
2.除留余数法(我用的就是这种方法):
???公式是:?h(k)=k??mod??p;
?其中p最好是素数,我在使用的时候:p是小于hash表长度的最大的素数。这种方法自然产生冲突,我解决冲突的方法就是所谓的拉链法(就是出现冲突以后,就在这个位置上在申请空间,然后放数据),不过在我的代码中解决冲突的方法不太明显,好像就是在潜意识中解决的。
3数字分析法
??简单的说,就是对我们要存方法的数据,单纯考察他们的数据的规律,来得到hash函数,这个东西会在什么地方用到,一时想不起来,好像没什么地方(除了数学中)在实际生活中不太好找这样有规律的数据。这东西可能科学家经常用,在实际生活中估计用到的不多。
????
处理hash函数的方法
?就是当冲突产生的时候,为hash地址产生冲突的关键字,再提供新的位置(如果还是冲突的就在提供新的位置)。
??? 开放定址法:当产生冲突时,就根据这个冲突的hash地址的值,计算新的hash地址(直到不出现冲突)。会有这样的情形出现:就是本来不是同义词的关键字,也会出现冲突,术语叫做非关键字冲突。
?? 拉链法:就是当冲突出现的时候,把这个数据加到以这个地址为头节点的链表的后面。
?
以上是自己所知道一些总结。下面简单的说说自己的代码。
?
我自己构造了一个链表,然后又以链表的类型够造了数组。这样呢,处理hash冲突的方法自然就是所谓的拉链法了。
?然后我的装载因子也大于1了。实际是这样的情况:当某一个链表的长度,超过了数组长度开平方后的值的话,就要rehash。(其中数组长度开平方就是我的装载因子)
还有就是我想说一下,一开始我的这个hash只是int型,但是大圣一说最好是Object,然后就想办法改了,显然最好是用Object的地址,但这个行不通,因为字符串的toString()方法不配合,最后用的是hashCode(),这个方法可能会返回负值,所以也要稍微处理一下。
?
下面是代码,其中的解释是当时自己写代码时候的想法,我想这个解释最好是留着。
?package myhash;
/**
* 这是我定义的链表的类 我应该好好想想
*
* @author 田西超
*
*/
public class TxcNode {
// 里面的一些基本的属性
public TxcNode next = null;
public TxcNode previce; // 取得前面的一个节点,在本程序中只有tail使用这个属性
public Object data;// 表示这个结点的值
public TxcNode() {
}
public TxcNode(Object data) {
this.data = data;
}
}
?
package myhash;
public class TxcLink {
// 这里边的属性应该是长度,头结点 尾结点之类的东西
public TxcNode head;
public TxcNode tail;
public int length = 0;
// 每一个链表 都应该有结点和尾节点
public TxcLink() {// 构造函数中就要有这个 头和尾结点
head = new TxcNode();
tail = new TxcNode();
}
// 链表中应该有添加一个结点的方法
public void add(Object o) {
TxcNode tn = new TxcNode(o);
if (length == 0) {
head.next = tn;
tn.next = tail;
tail.previce = tn;
length++;
} else {
// 取得当前的结点
TxcNode tem = tail.previce;
tem.next = tn;
tn.next = tail;
tail.previce = tn;
length++;
}
}
}
?
package myhash;
public class TxcHash {
private int modelLen;// 这个属性是那个 hash我在写hash函数的 那个分母 (这是个素数)
public TxcLink[] txcArray;
private int loadFactor;// 这个是装载因子
private int endlength = 0;
// 我写了两个构造函数
public TxcHash() {
// 首先创建一个数组
txcArray = new TxcLink[100]; // 这里边放的是head
// 这个数组里面是 存放地址还是 数据呢,我看最好是地址。也就是一个链表
modelLen = 97;// modelLen一般小于TxcNode的长度
loadFactor = 10;
endlength = 100;
}
public TxcHash(int initLength, int modelLen) {
txcArray = new TxcLink[initLength];
this.modelLen = modelLen;
loadFactor = (int) Math.sqrt(initLength);
}
// 这里边也要有添加元素的方法 其实就是构造hash的方法 我用的是 除模取余的方法
// 我是定义了这个 TxcNode的
public int hashFun(Object o) {
int i = Math.abs(o.hashCode());
int index = i % modelLen;
return index;
}
/**
* 现在是处理hash冲突 其实我一开想好了或者说是定义了 处理hash冲突的方法 在这个地方就不明显了 首先有这个 数值计算出
* 位置,然后在这个位置上我们创建一个 链表的对象 放到这个位置上, 然后用这个链表的来添加数据 由hash 函数计算出这个 这个对象的位置,
*
* @param i
*/
public void hashAdd(Object i) {
int index = hashFun(i);// 求得i元素的位置 如果这个位置不冲突的话 就要申请一个新的结点, 冲
// 突的话 就不需要了
if (txcArray[index] != null) {// 冲突不发生时 的情况
if (txcArray[index].length != 0)
txcArray[index].add(i);// 。
} else {
TxcLink tl = new TxcLink();
tl.add(i);//
txcArray[index] = tl;// 调用添加数据的方法
}
if (txcArray[index].length > loadFactor) {
System.out.println(loadFactor);
rehash();
}
}
/**
* 这个rehash函数
*/
public void rehash() {
// 下面开始 rehash 这个是非常重要的环节
int l = txcArray.length;
TxcLink newtxcArray[] = new TxcLink[2 * l];
endlength = 2 * l;
loadFactor = (int) Math.sqrt(2 * l);// 修改装载因子
modelLen = prime(2 * l);// 这个是 模的修改
// 以上是一些属性的修改
// 下面是 数据的 重放
for (int j = 0; j < l; j++) {
if (txcArray[j] != null) {
int ll = txcArray[j].length;// 连表的长度
if (ll > 0) {
TxcNode tn = txcArray[j].head.next;
while (ll > 0) {
int newindex = hashFun(tn.data);// 重新分配位置
if (newtxcArray[newindex] != null) {
if (newtxcArray[newindex].length != 0)
newtxcArray[newindex].add(tn.data);// 。
} else {
TxcLink tl = new TxcLink();
tl.add(tn.data);
newtxcArray[newindex] = tl;
}
tn = tn.next;
if (newtxcArray[newindex].length > modelLen) {
rehash();
}
ll--;
}
}
}
}
txcArray = newtxcArray;
}
/**
* 这个打印hash中的所有的数据
*/
public void printall() {
for (int i = 0; i < endlength; i++) {
if (txcArray[i] != null) {
TxcLink tk = txcArray[i];
TxcNode tem = tk.head.next;
for (int j = 0; j < tk.length; j++) {
Object d = tem.data;
System.out.print("这些数据是:" + d);
tem = tem.next;
}
}
}
}
/**
* 查找数据的方法
*
* @param d
* @return
*/
public boolean search(Object d) {
System.out.println("这个数是:" + d);
int index = hashFun(d);
TxcLink tk = txcArray[index];
if (tk == null) {
return false;
} else {
TxcNode tem = tk.head.next;
for (int i = 0; i < tk.length; i++) {
if (tem.data.equals(d)) {
System.out.println("找到了是:" + tem.data);
return true;
} else {
tem = tem.next;
}
}
}
return false;
}
/**
* 这个是求得不超过某个数的最大的素数
*
* @param l
* @return
*/
private int prime(int l) {
int modelLen = 0;
for (int i = l - 1; i >= 0; i--) {
if (isPrimeNumber(i)) {
modelLen = i;
return modelLen;
}
}
return modelLen;
}
/**
* 判断某个数是否为素数
*
* @param i
* @return
*/
private boolean isPrimeNumber(int i) {
if (i >= 2) {
for (int j = 2; j <= Math.sqrt(i); j++) {
if (i % j == 0)
return false;
}
return true;
}
return false;
}
}
?
package myhash;
public class HashTest {
public static void main(String args[]) {
// java.util.Random ra = new java.util.Random();
TxcHash th = new TxcHash();
Long beginTime = System.currentTimeMillis();// 记录 开始时间
for (int j = 0; j < 1000000; j++) {
th.hashAdd("txc" + j);
}
th.hashAdd("jjs");
Long endTime = System.currentTimeMillis();// 记录结束时间
System.out.println("该程序总用时为:" + (endTime - beginTime));
Long beginTime2 = System.currentTimeMillis();
boolean b = th.search("txc" + 3532);
// th.printall();
Long endTime2 = System.currentTimeMillis();
System.out.println("查找的时间:" + (endTime2 - beginTime2) + "是否找到:" + b);
}
}
?该程序总用时为:2374