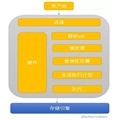
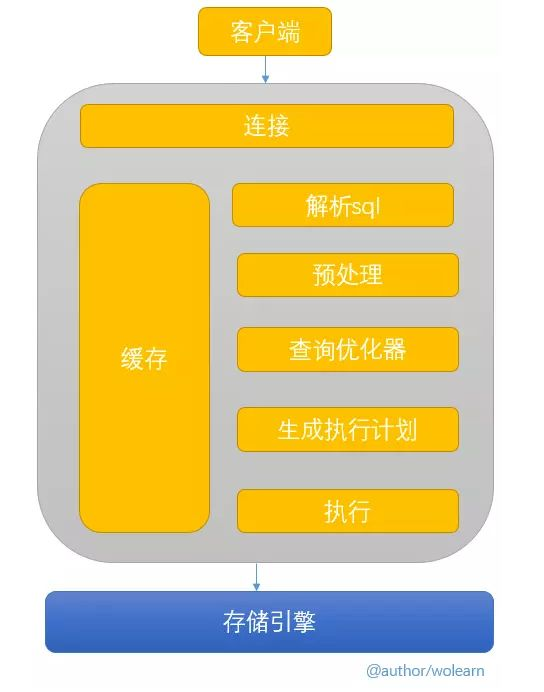
class="content">ЧАбд
БОЮФжївЊеыЖдЕФЪЧЙиЯЕаЭЪ§ОнЪ§ОнПтMySqlЁЃМќжЕРрЪ§ОнПтПЩвдВЮПМЃК
https://www.jianshu.com/p/098a870d83e4
ЯШМђЕЅЪсРэЯТMysqlЕФЛљБОИХФюЃЌШЛКѓЗжДДНЈЪБКЭВщбЏЪБетСНИіНзЖЮЕФгХЛЏеЙПЊЁЃ
1 ЛљБОИХФюМђЪі
- ЕквЛВуЃКПЭЛЇЖЫЭЈЙ§СЌНгЗўЮёЃЌНЋвЊжДааЕФsqlжИСюДЋЪфЙ§РД
- ЕкЖўВуЃКЗўЮёЦїНтЮіВЂгХЛЏsqlЃЌЩњГЩзюжеЕФжДааМЦЛЎВЂжДаа
- ЕкШ§ВуЃКДцДЂв§ЧцЃЌИКд№Ъ§ОнЕФДЂДцКЭЬсШЁ
1.2 Ыј
Ъ§ОнПтЭЈЙ§ЫјЛњжЦРДНтОіВЂЗЂГЁОА-ЙВЯэЫјЃЈЖСЫјЃЉКЭХХЫћЫјЃЈаДЫјЃЉЁЃЖСЫјЪЧВЛзшШћЕФЃЌЖрИіПЭЛЇЖЫПЩвддкЭЌвЛЪБПЬЖСШЁЭЌвЛИізЪдДЁЃаДЫјЪЧХХЫћЕФЃЌВЂЧвЛсзшШћЦфЫћЕФЖСЫјКЭаДЫјЁЃМђЕЅЬсЯТРжЙлЫјКЭБЏЙлЫјЁЃ
- РжЙлЫјЃЌЭЈГЃгУгкЪ§ОнОКељВЛМЄСвЕФГЁОАЃЌЖрЖСЩйаДЃЌЭЈЙ§АцБОКХКЭЪБМфДСЪЕЯжЁЃ
- БЏЙлЫјЃЌЭЈГЃгУгкЪ§ОнОКељМЄСвЕФГЁОАЃЌУПДЮВйзїЖМЛсЫјЖЈЪ§ОнЁЃ
вЊЫјЖЈЪ§ОнашвЊвЛЖЈЕФЫјВпТдРДХфКЯЁЃ
- БэЫјЃЌЫјЖЈећеХБэЃЌПЊЯњзюаЁЃЌЕЋЪЧЛсМгОчЫјОКељЁЃ
- ааЫјЃЌЫјЖЈааМЖБ№ЃЌПЊЯњзюДѓЃЌЕЋЪЧПЩвдзюДѓГЬЖШЕФжЇГжВЂЗЂЁЃ
ЕЋЪЧMySqlЕФДцДЂв§ЧцЕФецЪЕЪЕЯжВЛЪЧМђЕЅЕФааМЖЫјЃЌвЛАуЖМЪЧЪЕЯжСЫЖрАцБОВЂЗЂПижЦЃЈMVCCЃЉЁЃMVCCЪЧааМЖЫјЕФБфжжЃЌЖрЪ§ЧщПіЯТБмУтСЫМгЫјВйзїЃЌПЊЯњИќЕЭЁЃMVCCЪЧЭЈЙ§БЃДцЪ§ОнЕФФГИіЪБМфЕуПьееЪЕЯжЕФЁЃ
1.3 ЪТЮё
ЪТЮёБЃжЄвЛзщдзгадЕФВйзїЃЌвЊУДШЋВПГЩЙІЃЌвЊУДШЋВПЪЇАмЁЃвЛЕЉЪЇАмЃЌЛиЙіжЎЧАЕФЫљгаВйзїЁЃMySqlВЩгУздЖЏЬсНЛЃЌШчЙћВЛЪЧЯдЪНЕФПЊЦєвЛИіЪТЮёЃЌдђУПИіВщбЏЖМзїЮЊвЛИіЪТЮёЁЃ
ИєРыМЖБ№ПижЦСЫвЛИіЪТЮёжаЕФаоИФЃЌФФаЉдкЪТЮёФкКЭЪТЮёМфЪЧПЩМћЕФЁЃЫФжжГЃМћЕФИєРыМЖБ№ЃК
- ЮДЬсНЛЖСЃЈRead UnCommittedЃЉЃЌЪТЮёжаЕФаоИФЃЌМДЪЙУЛЬсНЛЖдЦфЫћЪТЮёвВЪЧПЩМћЕФЁЃЪТЮёПЩФмЖСШЁЮДЬсНЛЕФЪ§ОнЃЌдьГЩдрЖСЁЃ
- ЬсНЛЖСЃЈRead CommittedЃЉЃЌвЛИіЪТЮёПЊЪМЪБЃЌжЛФмПДМћвбЬсНЛЕФЪТЮёЫљзіЕФаоИФЁЃЪТЮёЮДЬсНЛжЎЧАЃЌЫљзіЕФаоИФЖдЦфЫћЪТЮёЪЧВЛПЩМћЕФЁЃвВНаВЛПЩжиИДЖСЃЌЭЌвЛИіЪТЮёЖрДЮЖСШЁЭЌбљМЧТМПЩФмВЛЭЌЁЃ
- ПЩжиИДЖСЃЈRepeatTable ReadЃЉЃЌЭЌвЛИіЪТЮёжаЖрДЮЖСШЁЭЌбљЕФМЧТМНсЙћЪБНсЙћЯрЭЌЁЃ
- ПЩДЎааЛЏЃЈSerializableЃЉЃЌзюИпИєРыМЖБ№ЃЌЧПжЦЪТЮёДЎаажДааЁЃ
1.4 ДцДЂв§Чц
InnoDBв§ЧцЃЌзюживЊЃЌЪЙгУзюЙуЗКЕФДцДЂв§ЧцЁЃБЛгУРДЩшМЦДІРэДѓСПЖЬЦкЪТЮёЃЌОпгаИпадФмКЭздЖЏБРРЃЛжИДЕФЬиадЁЃ MyISAMв§ЧцЃЌВЛжЇГжЪТЮёКЭааМЖЫјЃЌБРРЃКѓЮоЗЈАВШЋЛжИДЁЃ
2 ДДНЈЪБгХЛЏ
2.1 SchemaКЭЪ§ОнРраЭгХЛЏ
ећЪ§
TinyInt,SmallInt,MediumInt,Int,BigInt ЪЙгУЕФДцДЂ8,16,24,32,64ЮЛДцДЂПеМфЁЃЪЙгУUnsignedБэЪОВЛдЪаэИКЪ§ЃЌПЩвдЪЙе§Ъ§ЕФЩЯЯпЬсИпвЛБЖЁЃ
ЪЕЪ§
- Float,Double , жЇГжНќЫЦЕФИЁЕудЫЫуЁЃ
- DecimalЃЌгУгкДцДЂОЋШЗЕФаЁЪ§ЁЃ
зжЗћДЎ
- VarCharЃЌДцДЂБфГЄЕФзжЗћДЎЁЃашвЊ1Лђ2ИіЖюЭтЕФзжНкМЧТМзжЗћДЎЕФГЄЖШЁЃ
- CharЃЌЖЈГЄЃЌЪЪКЯДцДЂЙЬЖЈГЄЖШЕФзжЗћДЎЃЌШчMD5жЕЁЃ
- BlobЃЌText ЮЊСЫДцДЂКмДѓЕФЪ§ОнЖјЩшМЦЕФЁЃЗжБ№ВЩгУЖўНјжЦКЭзжЗћЕФЗНЪНЁЃ
ЪБМфРраЭ
- DateTimeЃЌБЃДцДѓЗЖЮЇЕФжЕЃЌеМ8ИізжНкЁЃ
- TimeStampЃЌЭЦМіЃЌгыUNIXЪБМфДСЯрЭЌЃЌеМ4ИізжНкЁЃ
гХЛЏНЈвщЕу
- ОЁСПЪЙгУЖдгІЕФЪ§ОнРраЭЁЃБШШчЃЌВЛвЊгУзжЗћДЎРраЭБЃДцЪБМфЃЌгУећаЭБЃДцIPЁЃ
- бЁдёИќаЁЕФЪ§ОнРраЭЁЃФмгУTinyIntВЛгУIntЁЃ
- БъЪЖСаЃЈidentifier columnЃЉЃЌНЈвщЪЙгУећаЭЃЌВЛЭЦМізжЗћДЎРраЭЃЌеМгУИќЖрПеМфЃЌЖјЧвМЦЫуЫйЖШБШећаЭТ§ЁЃ
- ВЛЭЦМіORMЯЕЭГздЖЏЩњГЩЕФSchemaЃЌЭЈГЃОпгаВЛзЂжиЪ§ОнРраЭЃЌЪЙгУКмДѓЕФVarCharРраЭЃЌЫїв§РћгУВЛКЯРэЕШЮЪЬтЁЃ
- ецЪЕГЁОАЛьгУЗЖЪНКЭЗДЗЖЪНЁЃШпгрИпВщбЏаЇТЪИпЃЌВхШыИќаТаЇТЪЕЭЃЛШпгрЕЭВхШыИќаТаЇТЪИпЃЌВщбЏаЇТЪЕЭЁЃ
- ДДНЈЭъШЋЕФЖРСЂЕФЛузмБэ\ЛКДцБэЃЌЖЈЪБЩњГЩЪ§ОнЃЌгУгкгУЛЇКФЪБЪБМфГЄЕФВйзїЁЃЖдгкОЋШЗЖШвЊЧѓИпЕФЛузмВйзїЃЌПЩвдВЩгУ РњЪЗНсЙћ+зюаТМЧТМЕФНсЙћ РДДяЕНПьЫйВщбЏЕФФПЕФЁЃ
- Ъ§ОнЧЈвЦЃЌБэЩ§МЖЕФЙ§ГЬжаПЩвдЪЙгУгАзгБэЕФЗНЪНЃЌЭЈЙ§аоИФдБэЕФБэУћЃЌДяЕНБЃДцРњЪЗЪ§ОнЃЌЭЌЪБВЛгАЯьаТБэЪЙгУЕФФПЕФЁЃ
2.2 Ыїв§
Ыїв§АќКЌвЛИіЛђЖрИіСаЕФжЕЁЃMySqlжЛФмИпаЇЕФРћгУЫїв§ЕФзюзѓЧАзКСаЁЃЫїв§ЕФгХЪЦЃК
- МѕЩйВщбЏЩЈУшЕФЪ§ОнСП
- БмУтХХађКЭСуЪББэ
- НЋЫцЛњIOБфЮЊЫГађIO ЃЈЫГађIOЕФаЇТЪИпгкЫцЛњIOЃЉ
B-Tree
ЪЙгУзюЖрЕФЫїв§РраЭЁЃВЩгУB-TreeЪ§ОнНсЙЙРДДцДЂЪ§ОнЃЈУПИівЖзгНкЕуЖМАќКЌжИЯђЯТвЛИівЖзгНкЕуЕФжИеыЃЌДгЖјЗНБувЖзгНкЕуЕФБщРњЃЉЁЃB-TreeЫїв§ЪЪгУгкШЋМќжЕЃЌМќжЕЗЖЮЇЃЌМќЧАзКВщевЃЌжЇГжХХађЁЃ
B-TreeЫїв§ЯожЦЃК
- ШчЙћВЛЪЧАДееЫїв§ЕФзюзѓСаПЊЪМВщбЏЃЌдђЮоЗЈЪЙгУЫїв§ЁЃ
- ВЛФмЬјЙ§Ыїв§жаЕФСаЁЃШчЙћЪЙгУЕквЛСаКЭЕкШ§СаЫїв§ЃЌдђжЛФмЪЙгУЕквЛСаЫїв§ЁЃ
- ШчЙћВщбЏжагаИіЗЖЮЇВщбЏЃЌдђЦфгвБпЕФЫљгаСаЖМЮоЗЈЪЙгУЫїв§гХЛЏВщбЏЁЃ
ЙўЯЃЫїв§
жЛгаОЋШЗЦЅХфЫїв§ЕФЫљгаСаЃЌВщбЏВХгааЇЁЃДцДЂв§ЧцЛсЖдЫљгаЕФЫїв§СаМЦЫувЛИіЙўЯЃТыЃЌЙўЯЃЫїв§НЋЫљгаЕФЙўЯЃТыДцДЂдкЫїв§жаЃЌВЂБЃДцжИЯђУПИіЪ§ОнааЕФжИеыЁЃ
ЙўЯЃЫїв§ЯожЦЃК
- ЮоЗЈгУгкХХађ
- ВЛжЇГжВПЗжЦЅХф
- жЛжЇГжЕШжЕВщбЏШч=ЃЌINЃЈЃЉЃЌВЛжЇГж < >
гХЛЏНЈвщЕу
- зЂвтУПжжЫїв§ЕФЪЪгУЗЖЮЇКЭЪЪгУЯожЦЁЃ
- Ыїв§ЕФСаШчЙћЪЧБэДяЪНЕФвЛВПЗжЛђепЪЧКЏЪ§ЕФВЮЪ§ЃЌдђЪЇаЇЁЃ
- еыЖдЬиБ№ГЄЕФзжЗћДЎЃЌПЩвдЪЙгУЧАзКЫїв§ЃЌИљОнЫїв§ЕФбЁдёадбЁдёКЯЪЪЕФЧАзКГЄЖШЁЃ
- ЪЙгУЖрСаЫїв§ЕФЪБКђЃЌПЩвдЭЈЙ§ AND КЭ OR гяЗЈСЌНгЁЃ
- жиИДЫїв§УЛБивЊЃЌШчЃЈAЃЌBЃЉКЭЃЈAЃЉжиИДЁЃ
- Ыїв§дкwhereЬѕМўВщбЏКЭgroup byгяЗЈВщбЏЕФЪБКђЬиБ№гааЇЁЃ
- НЋЗЖЮЇВщбЏЗХдкЬѕМўВщбЏЕФзюКѓЃЌЗРжЙЗЖЮЇВщбЏЕМжТЕФгвБпЫїв§ЪЇаЇЕФЮЪЬтЁЃ
- Ыїв§зюКУВЛвЊбЁдёЙ§ГЄЕФзжЗћДЎЃЌЖјЧвЫїв§СавВВЛвЫЮЊnullЁЃ
3 ВщбЏЪБгХЛЏ
3.1 ВщбЏжЪСПЕФШ§ИіживЊжИБъ
- ЯьгІЪБМф ЃЈЗўЮёЪБМфЃЌХХЖгЪБМфЃЉ
- ЩЈУшЕФаа
- ЗЕЛиЕФаа
3.2 ВщбЏгХЛЏЕу
- БмУтВщбЏЮоЙиЕФСаЃЌШчЪЙгУSelect * ЗЕЛиЫљгаЕФСаЁЃ
- БмУтВщбЏЮоЙиЕФаа
- ЧаЗжВщбЏЁЃНЋвЛИіЖдЗўЮёЦїбЙСІНЯДѓЕФШЮЮёЃЌЗжНтЕНвЛИіНЯГЄЕФЪБМфжаЃЌВЂЗжЖрДЮжДааЁЃШчвЊЩОГ§вЛЭђЬѕЪ§ОнЃЌПЩвдЗж10ДЮжДааЃЌУПДЮжДааЭъГЩКѓднЭЃвЛЖЮЪБМфЃЌдйМЬајжДааЁЃЙ§ГЬжаПЩвдЪЭЗХЗўЮёЦїзЪдДИјЦфЫћШЮЮёЁЃ
- ЗжНтЙиСЊВщбЏЁЃНЋЖрБэЙиСЊВщбЏЕФвЛДЮВщбЏЃЌЗжНтГЩЖдЕЅБэЕФЖрДЮВщбЏЁЃПЩвдМѕЩйЫјОКељЃЌВщбЏБОЩэЕФВщбЏаЇТЪвВБШНЯИпЁЃвђЮЊMySqlЕФСЌНгКЭЖЯПЊЖМЪЧЧсСПМЖЕФВйзїЃЌВЛЛсгЩгкВщбЏВ№ЗжЮЊЖрДЮЃЌдьГЩаЇТЪЮЪЬтЁЃ
- зЂвтcountЕФВйзїжЛФмЭГМЦВЛЮЊnullЕФСаЃЌЫљвдЭГМЦзмЕФааЪ§ЪЙгУcountЃЈ*ЃЉЁЃ
- group by АДееБъЪЖСаЗжзщаЇТЪИпЃЌЗжзщНсЙћВЛвЫГіааЗжзщСажЎЭтЕФСаЁЃ
- ЙиСЊВщбЏбгГйЙиСЊЃЌПЩвдИљОнВщбЏЬѕМўЯШЫѕаЁИїздвЊВщбЏЕФЗЖЮЇЃЌдйЙиСЊЁЃ
- LimitЗжвГгХЛЏЁЃПЩвдИљОнЫїв§ИВИЧЩЈУшЃЌдйИљОнЫїв§СаЙиСЊздЩэВщбЏЦфЫћСаЁЃШч
SELECT
?id,
?NAME,
?age
WHERE
?student?s1
INNER?JOIN?(
?SELECT
?????id
?FROM
?????student
?ORDER?BY
?????age
?LIMIT?50,5
)?AS?s2?ON?s1.id?=?s2.id
- UnionВщбЏФЌШЯШЅжиЃЌШчЙћВЛЪЧвЕЮёБиаыЃЌНЈвщЪЙгУаЇТЪИќИпЕФUnion All
ВЙГфФкШн
РДздДѓЩё-аЁБІ
1.ЬѕМўжаЕФзжЖЮРраЭКЭБэНсЙЙРраЭВЛвЛжТЃЌmysqlЛсздЖЏМгзЊЛЛКЏЪ§ЃЌЕМжТЫїв§зїЮЊКЏЪ§жаЕФВЮЪ§ЪЇаЇЁЃ
2.likeВщбЏЧАУцВПЗжЮДЪфШыЃЌвд%ПЊЭЗЮоЗЈУќжаЫїв§ЁЃ
3.ВЙГф2Иі5.7АцБОЕФаТЬиадЃК generated columnЃЌОЭЪЧЪ§ОнПтжаетвЛСагЩЦфЫћСаМЦЫуЖјЕУ
CREATE?TABLE?triangle?(sidea?DOUBLE,?sideb?DOUBLE,?area?DOUBLE?AS?(sidea?*?sideb?/?2));
insert?into?triangle(sidea,?sideb)?values(3,?4);
select?*?from?triangle;
+-------+-------+------+
|?sidea?|?sideb?|?area?|
+-------+-------+------+
|???3??????|???4??????|??6?????|
+-------+-------+------+
жЇГжJSONИёЪНЪ§ОнЃЌВЂЬсЙЉЯрЙиФкжУКЏЪ§
CREATE?TABLE?json_test?(name?JSON);
INSERT?INTO?json_test?VALUES('{"name1":?"value1",?"name2":?"value2"}');
SELECT?*?FROM?json_test?WHERE?JSON_CONTAINS(name,?'$.name1');
РДздJVMзЈМв-Дя
ЙизЂexplainдкадФмЗжЮіжаЕФЪЙгУ
EXPLAIN?SELECT?settleId?FROM?Settle?WHERE?settleId?=?"3679"
- select_typeЃЌгаМИжжжЕЃКsimpleЃЈБэЪОМђЕЅЕФselectЃЌУЛгаunionКЭзгВщбЏЃЉЃЌprimaryЃЈгазгВщбЏЃЌзюЭтУцЕФselectВщбЏОЭЪЧprimaryЃЉЃЌunionЃЈunionжаЕФЕкЖўИіЛђЫцКѓЕФselectВщбЏЃЌВЛвРРЕЭтВПВщбЏНсЙћЃЉЃЌdependent unionЃЈunionжаЕФЕкЖўИіЛђЫцКѓЕФselectВщбЏЃЌвРРЕЭтВПВщбЏНсЙћЃЉ
- typeЃЌгаМИжжжЕЃКsystemЃЈБэНігавЛааЃЈ=ЯЕЭГБэЃЉЃЌетЪЧconstСЌНгРраЭЕФвЛИіЬиР§ЃЉЃЌconstЃЈГЃСПВщбЏЃЉ, ref(ЗЧЮЈвЛЫїв§ЗУЮЪЃЌжЛгаЦеЭЈЫїв§)ЃЌeq_refЃЈЪЙгУЮЈвЛЫїв§ЛђзщМўВщбЏЃЉЃЌallЃЈШЋБэВщбЏЃЉЃЌindexЃЈИљОнЫїв§ВщбЏШЋБэЃЉЃЌrangeЃЈЗЖЮЇВщбЏЃЉ
- possible_keys: БэжаПЩФмАяжњВщбЏЕФЫїв§
- keyЃЌбЁдёЪЙгУЕФЫїв§
- key_lenЃЌЪЙгУЕФЫїв§ГЄЖШ
- rowsЃЌЩЈУшЕФааЪ§ЃЌдНДѓдНВЛКУ
- extraЃЌгаМИжжжЕЃКOnly indexЃЈаХЯЂДгЫїв§жаМьЫїГіЃЌБШЩЈУшБэПьЃЉЃЌwhere usedЃЈЪЙгУwhereЯожЦЃЉЃЌUsing filesort ЃЈПЩФмдкФкДцЛђДХХЬХХађЃЉЃЌUsing temporaryЃЈЖдВщбЏНсЙћХХађЪБЪЙгУСйЪББэЃЉ
ФцЗцЦ№БЪЪЧвЛИізЈзЂгкГЬађдБЕФБрГЬШІзгЃЌвдЗжЯэjavaЁЂPythonЁЂбЇЯАзЪдД ЮЊжїЃЌЙизЂМДПЩСьШЁ 23 жжОЋбЁЕФБрГЬЪгЦЕНЬГЬКЭДѓРаУЧЭЦМіЕФЕчзгАцбЇЯАзЪСЯЃЁ