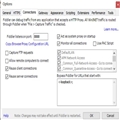
经过运行抓取程序,抓到的数据网站数量为4305个,接下来,需要进行分词处理,分词后,再统计词出现的次数,词出现的次数一部分
提现了本类网站中该次的竞争情况。分词使用的hanlp
开源项目,关于该开源项目的引用与使用,此处不
详细介绍,读者可以访问 https://github.com/hankcs/HanLP了解详情。本篇博客涵盖的内容包括:分词、统计词频、结果保存数据库。表结构和相关代码如下:
表名:relative_hotwords表中文名:相关热词信息表字段名称字段类型字段解释keywordsvarchar(100)关键词rh_timesint出现次数rh_title_timesint在title中出现的次数rh_keyword_tiemsint在keywords中出现的次数rh_description_timesint在description中出现的次数rh_other_timesint在网页其他地方出现的次数rh_hot_scoreint词热度(百度指数)rh_pc_scoreint词在PC端的热度(百度指数)rh_wise_scoreint词在移动端的热度(百度指数)
建表语句:
class="sql" name="code">
Create table relative_hotwords(keywords varchar(100),rh_times int,rh_title_times int,
rh_keyword_tiems int,rh_description_times int, rh_other_times int,rh_hot_score int, rh_pc_score int, rh_wise_score int) character set utf8mb4 collate utf8mb4_bin;
java代码:
/**
* 分词
*/
public void segWordsAndSave(){
Sort sort = new Sort();
Sqlca sqlca = null;
try {
sqlca = sort.getSqlca();
sqlca.execute("select web_html from web_detail limit 1220,5000");
FileTool ft=new FileTool();
int k=0;
while (sqlca.next()){
ft.saveRowToFile(sqlca.getString("web_html"),"C:\\temp\\hotwords\\t.txt");
System.out.println(k++);
}
ComputeHis ch=new ComputeHis();
ch.segFileWord("C:\\temp\\hotwords\\t.txt","C:\\temp\\hotwords\\t2.txt",0,0);
}catch (Exception e){
e.printStackTrace();
} finally {
if (sqlca != null) sqlca.closeAll();
}
}
/**
* 统计词频
*/
public void wordCoutn(){
List<String> ls=new ArrayList<>();
NlpTool nt= new NlpTool();
List<String> res=new ArrayList<>();
FileTool ft=new FileTool();
ComputeHis ch=new ComputeHis();
try {
BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream("C:\\temp\\hotwords\\t2.txt"),"utf-8"));
int x=0;
String line=null;
String content="";
Map<String ,Integer> mp=new HashMap <String ,Integer> ();
while ((line = reader.readLine()) != null) {
x++;
if(x%100000==0) {
System.out.println(x+" "+new Date());
}
String[] words=line.split(" ");
for(String word:words){
if(mp.containsKey(word)){
mp.put(word,mp.get(word) +1);
}else{
mp.put(word, 1);
}
}
}
reader.close();
Set<String> set=mp.keySet();
java.util.SortedMap<String, String> topN = new java.util.TreeMap<String, String>();
for(String key:set){
topN.put((10000000 - mp.get(key))+"-"+key,"");
}
set=topN.keySet();
System.out.println(set.size());
int i=0;
for(String key:set){
String[] words=key.split("-");
if(words==null){
continue;
}
if(words.length<2){
continue;
}
words[1]=words[1].replace("\r","").replace("\t","").replace("\n","");
if(words[1]!=null&&!words[1].isEmpty()&&!ch.isStop(words[1])&&words[1].length()>1){
res.add(key);
i++;
}
// if(i>=20) break;
}
ft.saveListToFile("C:\\temp\\hotwords\\wdcount.txt",res);
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
/**
* 多线程解析html,抽取关键词信息
* @param fileName
*/
public void getKeyWordsFromHtml(String fileName){
FileTool ft=new FileTool();
Sort sort = new Sort();
NlpTool nlpTool=new NlpTool();
Sqlca sqlca = null;
Sqlca sqlcah = null;
try {
sqlca = sort.getSqlca();
sqlcah=sort.getSqlcaH();
int webNums=0;
//获得网页数量
sqlca.execute("select count(*) ct from web_detail");
if(sqlca.next()){
webNums=sqlca.getInt("ct");
}
if(webNums==0){ //没有网页数据
sqlca.closeAll();
return;
}
System.out.println(webNums);
for(int i=0;i<8;i++){
String parm=fileName;
int step=webNums/8;
int begin=i*step;
int end=(i+1)*step;
if(end<webNums && end >(webNums - step)) end=webNums;
parm+=","+begin+","+end;
// System.out.println(parm);
final ActorRef ta = system.actorOf(Props.create(AnalyseHtmlActor.class));
ta.tell(parm, ActorRef.noSender());
if(end>=webNums) break;
}
}catch (Exception e){
e.printStackTrace();
}finally {
if(sqlca!=null) sqlca.closeAll();
if(sqlcah!=null) sqlcah.closeAll();
}
}