引用
使用
Antlr 处理文本
https://www.ibm.com/developerworks/cn/java/j-lo-antlrtext/index.html
该文章写的非常好,无耐是2011年写的,与现有的antlr
版本差别较大,编译不过去,编译过去,也测试不出来正确的结果,以下为用antlr4.2重写的
新项目使用maven和ant构建,需要以下几个文件
- pom.xml
- build.xml
- SqlExtrator.g4语法文件
- SqlExtrator.clj测文件
- Test.java 测试代码
测试方法,
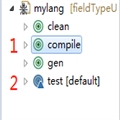
- 先用ant执行compile任务,生成和编译生成的一堆词法解析器和语法解析器代码,
然后执行ant的test任务,解析SqlExtrator.clj测文件里的文本
- 使有Test.java,手动编程调用
使用ant任务的截图,


pom.xml
class="xml" name="code">
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.xxx.lang</groupId>
<artifactId>fieldTypeUpdate</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>fieldTypeUpdate</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.antlr</groupId>
<artifactId>antlr4</artifactId>
<version>4.2</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.codehaus.mojo</groupId>
<artifactId>build-helper-maven-plugin</artifactId>
<version>1.8</version>
<executions>
<execution>
<id>add-source</id>
<phase>generate-sources</phase>
<goals>
<goal>add-source</goal>
</goals>
<configuration>
<sources>
<source>src/generated/java</source>
</sources>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
build.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<project basedir="." default="test" name="mylang">
<property environment="env"/>
<property name="debuglevel" value="source,lines,vars"/>
<property name="target" value="1.8"/>
<property name="source" value="1.8"/>
<property name="language" value="sqlExtrator"/>
<path id="mylang.classpath">
<pathelement location="lib/antlr-2.7.7.jar"/>
<pathelement location="lib/antlr-runtime-3.5.jar"/>
<pathelement location="lib/antlr4-4.2.jar"/>
<pathelement location="lib/antlr4-annotations-4.2.jar"/>
<pathelement location="lib/antlr4-runtime-4.2.jar"/>
<pathelement location="lib/junit-3.8.1.jar"/>
<pathelement location="lib/org.abego.treelayout.core-1.0.1.jar"/>
<pathelement location="lib/ST4-4.0.7.jar"/>
<pathelement location="lib/stringtemplate-3.2.1.jar"/>
</path>
<path id="antlr.classpath">
<pathelement location="antlr-4.7.1-complete.jar"/>
</path>
<path id="compile.path">
<pathelement location="target/classes"/>
</path>
<target name="clean">
<delete dir="target"></delete>
<delete dir="src/main/java/com/xxx/lang/mylang/${language}"></delete>
</target>
<target depends="clean" name="gen">
<echo message="generate java from g4 file"/>
<java classname="org.antlr.v4.Tool" fork="yes" failonerror="true">
<classpath refid="mylang.classpath"/>
<arg value="src/main/resources/SqlExtrator.g4"/>
<arg line="-package "/>
<arg value="com.xxx.lang.mylang.${language}"/>
<arg line="-o "/>
<arg value="src/main/java/com/xxx/lang/mylang/${language}/"/>
<arg value="-visitor"/>
<arg value="-no-listener"/>
<arg value="-encoding"/>
<arg value="UTF-8"/>
</java>
</target>
<target depends="gen" name="compile">
<echo message="compile generate java file"/>
<mkdir dir="target/classes"/>
<javac debug="true" debuglevel="${debuglevel}" destdir="target/classes" includeantruntime="false" source="${source}" target="${target}">
<src path="src/main/java"/>
<compilerarg line="-encoding UTF-8 "/>
<classpath refid="mylang.classpath"/>
</javac>
</target>
<target name="test" description="Run the main class" >
<java classname="org.antlr.v4.gui.TestRig" fork="yes" failonerror="true">
<classpath refid="antlr.classpath"/>
<classpath refid="compile.path"/>
<sysproperty key="file.encoding" value="UTF-8"/>
<arg value="com.xxx.lang.mylang.${language}.SqlExtrator"></arg>
<arg value="sql"></arg>
<arg value="-gui"></arg>
<arg value="src/test/java/SqlExtrator.clj"></arg>
</java>
</target>
</project>
SqlExtrator.g4 语法文件 该语法文件,仅可以识别词法规定的字符,词法外的字符将会报错
grammar SqlExtrator;
WS : (' ' |'\t' |'\r' |'\n' )+ ;
INT: '0'..'9' + ;
ID : ('a'..'z' |'A'..'Z' |'_' ) ('a'..'z' |'A'..'Z' |'_' |'0'..'9' )*;
EOL: ('\n' | '\r' | '\r\n')*;
SUCCESS:'DB20000I The SQL command completed successfully.'EOL ;
SqlFrg :'INSERT INTO SYSA.' ID '(' ID ',' ID ')' WS 'VALUES' '(\'' ID '\',\'' INT '\')'EOL ;
txt:mysql=SqlFrg {System.out.println($mysql.text);} SUCCESS;
sql:(txt)+;
第二个版本的语法,添加了:
FILTER: .? -> skip;
仅这一行,这行代码,使用
正则的非贪婪匹配规则,
引用
Wildcard
Operator and Nongreedy Subrules
正则
表达式贪婪与非贪婪模式
1.什么是
正则表达式的贪婪与非贪婪匹配
如:String str="abcaxc";
Patter p="ab.*c";
贪婪匹配:正则表达式一般趋向于最大长度匹配,也就是所谓的贪婪匹配。如上面使用模式p匹配字符串str,结果就是匹配到:abcaxc(ab.*c)。
非贪婪匹配:就是匹配到结果就好,就少的匹配字符。如上面使用模式p匹配字符串str,结果就是匹配到:abc(ab.*c)。
2.编程中如何区分两种模式
默认是贪婪模式;在量词后面直接加上一个问号?就是非贪婪模式。
量词:{m,n}:m到n个
*:任意多个
+:一个到多个
?:0或一个
grammar SqlExtrator;
SqlFrg :'INSERT INTO SYSA.' ID '(' ID ',' ID ')' WS 'VALUES' '(\'' ID '\',\'' INT '\')' ;
fragment WS : (' ' |'\t' |'\r' |'\n' )+ ;
fragment ID: ('a'..'z' |'A'..'Z' |'_' ) ('a'..'z' |'A'..'Z' |'_' |'0'..'9' )*;
fragment INT: '0'..'9' + ;
fragment EOL: '\n' | '\r' | '\r\n';
SUCCESS:'DB20000I The SQL command completed successfully.' ;
all: (SqlFrg SUCCESS {System.out.println($SqlFrg.text);})+ ;
FILTER: .? -> skip;
SqlExtrator.clj 测试文件
INSERT INTO SYSA.IF_EMPUSRRLA(USRNUM,EMPNUM) VALUES('U037508','275159')
DB20000I The SQL command completed successfully.
document.write(v+' test is '+result+'</br>');//该行代码在第一个版本的语法中会报错
INSERT INTO SYSA.IF_USRSTNRLA(USRNUM,STNNUM) VALUES('U037710','00026')
DB20000I The SQL command completed successfully.
Test.java 测试代码
public class Test {
public static void main(String[] args) {
try {
String filename = "D:\\workplace\\fieldTypeUpdate\\src\\test\\java\\SqlExtrator.clj";
InputStream in = new FileInputStream(filename);
ANTLRInputStream input = new ANTLRInputStream(in);
SqlExtratorLexer lexer = new SqlExtratorLexer(input);
CommonTokenStream tokens = new CommonTokenStream(lexer);
SqlExtratorParser parser = new SqlExtratorParser(tokens);
parser.sql();
System.out.println("done!");
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
测试结果控制台输出:
引用
INSERT INTO SYSA.IF_EMPUSRRLA(USRNUM,EMPNUM) VALUES('U037508','275159')
INSERT INTO SYSA.IF_USRSTNRLA(USRNUM,STNNUM) VALUES('U037710','00026')
done!

- 大小: 49.2 KB

- 大小: 5.1 KB