�������������еķ������ݻ��� OpenDK �� java 11 �汾�� HotSpot JVM Դ���롣
���Ķ�����֮ǰ������Ҫ��
�����ص�������ݣ�
�Ķ����飺
���ķdz���������д��һ�������ڣ������ִ����еĹ۵�ͷ������DZ��˾�������������ͷ����ó��ģ�ͬʱ����˺ܶ������ϵ����£���Щ����������Ѿ��ŵ���ĩ�IJο������У��ڴ˷dz���л��Щ���ߵ�����������ϣ�������������꣬�Ҹұ�֤��ֻҪ��������꣬�϶��ջ�ܶ࣬���͡�
?
??
���������ʱ���������ɣ�Ҳ�Ǻܶ��ִ�����ϵͳ��Ҫ�ṩ�ıر����ܡ��ڹ�ȥĦ�����ɴ����£����� CPU ���ļ�����ٶ�Խ��Խ�졣�������Ų�ҵ�ķ�չ������CPU���ĵļ��������Ѿ�����ͻ�ƣ���ͳ�ļ�ǿ���˵�˼άģʽ�Ѿ��������������ڹŴ���������Ҫǿ���ս������ս����Ϊ���ܹ�ʹ��ս����Խ��Խǿ������ѱ������Խ��Խǿ����ս�������ǵ�ƥ��������ʼ�������ģ�������Ƿ����˶������ݵ�ս���ṹ���������ֵĶ��ս����������ǿ������֮����ͬ���أ����ִ���������������ڵ��� CPU ����������������£�ʹ�ö�����ĵ� CPU �������м�����������ǿ���������
���ǣ��� CPU �Ͷ�ս����ԶԶ��ͬ�ģ�����ʵ�����еļ�����������Ҫ����Э���������ԭ���������˼ά��ʽ�������Դ��еģ����һ����ȫ���еļ�������ϵ�������൱���Ѷȵġ�
������һ���߲����ij��������ǹ��̽�����⣬�ڼ����ѧ����Ҳ��һ����Ҫ����ͻ�Ƶ��о�����ѧ��������������㷨��ƣ��ٵ�����ʵʩ���ٵ���ҵ��֤���ţ��������̶���Ҫ�Ƚϳ���ʱ�������е�����������������м��㱾�����Ƿdz����ӡ���ȷ���ġ�����Ԥ�����ϵͳ��
?
??
�ų�һ�α�д���������е� Java���䱾��Ҳ�ǹ����ڲ�ͬ��ϵͳ֮�ϵģ���������ʱ JVM ������ϵͳ�ײ�IJ��졣��ˣ��ڽ��� Java ������ϵ֮�䣬�б�Ҫ��Ҫ�����������ϵͳ�����ϵIJ������Լ���Ե����⡣
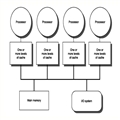
���ǵ�Ŀ����ʵ�ܼ������ü������ͬһʱ�̣��ܹ����и�����������м��㣬�ṩ�˷dz������Ľ����������Ȼ�⿴��������Ȼ����ʵ�����������ڶ�����⣬����һ���ش��������Ǿ�������ļ��㲻������ CPU һ���˵��£�������Ҫ�ܶ�����ϵͳ������ͬ���롣��������֪���������ϵͳ�������ٶ������� CPU�������������磺�ڴ桢���̡�����ȵȶ��Ǽ��仺���ģ�ͬʱ��Щ������Ŀǰ�ļ������ϵ���Ǻ��������ģ���Ϊ���Dz����ܽ������Ĵ�����������еļ���������Ը��� CPU �͵��ٴ洢֮��ĺ蹵�������Ҫʵ�ָ�Ч����ͨѶ��һ�����õĽ����������������֮������һ�� cache �㣬��� cache ����ٶȺ�������ٶȹ�ϵ���£�
1 CPU --> cache --> �洢ͨ�� cache �������ش���ʵ�� CPU �ʹ洢֮��ĸ�Ч���Ի��������Ǽ��������������ͨ�õ�һ�������������������м�㡣û��ʲô������һ���м�������˵ģ�����У��Ǿ����㡣�������ʱ��CPU ����Ҫʹ�õ������ݸ��Ƶ� Cache �У��Ժ�ÿ�λ�ȡ���ݶ��ӽ�Ϊ���ٵ� cache �л�ȡ���ӿ�����ٶȡ�
��ν����ܷ��棬��ʵ�ܹǸС����ּ�����ϵ��һ����Ҫ��������Ҫ������Ǿ��ǣ�����һ���ԣ�cache coherence�����⡣���ִ��ļ����ϵͳ�У���Ҫ���Ƕ��ϵͳΪ��������Щ�����ϵͳ�У�ÿһ�� CPU ��ӵ���Լ������ĸ��ٻ��棬������Ϊ����ֻ��һ�����������֮��ֻ�ܹ���������ϵͳҲ��Ϊ�������ڴ���ϵͳ��Shared-Memory multiprocessors System��������ͼ��ʾ��
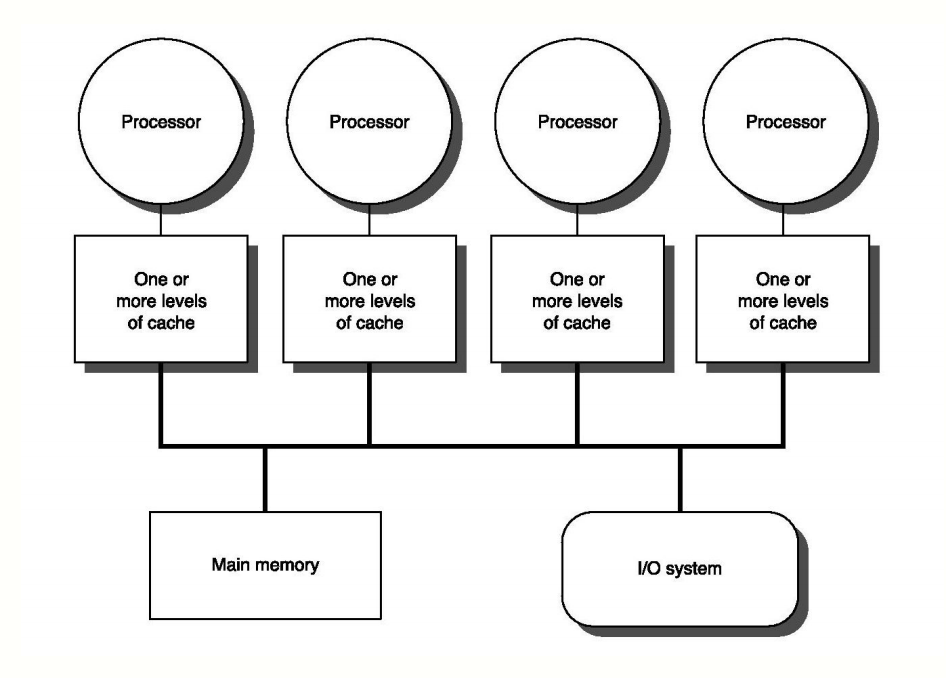
��ˣ������������ͬʱ��Ҫ����ͬһ���ڴ����������ʱ�����Ȼ�ȥ���� CPU �� cache �����е����ݣ����� cache �е�����Ҳ�Ǵӹ����ڴ��л�ȡ�ģ���ʱ������ CPU ���� cache �е����ݣ���ô����������ݲ�һ�µ������ˡ���ˣ�������������֡����ݾ�̬�������⣬�������ĸ�����Ϊ�أ���ʱ��������Ҫһ��һ����Э������֤������ CPU �ڲ�����ʱ����Ҫ���ػ���һ����Э�������в����������͵�Э���кܶ࣬���磺MSI��MESI��MOSI��Synapse��Firefly �Լ� Dragon Protocol �ȵȡ����ԣ�ͨ������£������ڴ���ϵͳ�ļܹ�������ʾ��
����ʹ�ø��� cache ������ CPU �ʹ洢�豸֮����ٶȺ蹵��Ϊ���ܹ�������ö�� CPU �Ĵ������ܣ�������ʵ��ִ�л���ָ��ʱ����һ���ᰴ�ճ����趨��ָ��˳��ִ�У����ܴ��ڴ�������ִ�У�Out-Of-Order Execution���Ż���ע�⣬������Ȼ����ִ���ˣ�����ϵͳ�ᱣִ֤�еĽ�����ϵ���ȷ�ģ��Ӻ���Ͽ��ͺ�����˳��ִ��һ�����ٸ��������������������´��룺
1 2 class="hljs-keyword">int a = value1; int b = value2;�����仰ʵ�ʵ�ִ��˳��������ȸ�ֵ a Ȼ��ֵ b������Ҳ���ܷ����������������仰ִ�����֮�� a �� b ��ֵ������ֵ���˾Ϳ��ԣ�����������Ϊ˳����ִ�У�����ʵ���� as-serial Э�鱣֤�ġ�Ϊʲô��Ҫ������һ���������仰������û��ʲô���ϵ������ԣ���ȫ���Բ���ִ�У���һ���棬�������ɵɵ�ذ���˳��ִ�еĻ�����ִ�е�һ�仰��ʱ�����ǿ�����Ҫ�������ж�ȡ value1 ��ֵ�����ֲ������� CPU �����Ǽ��仺���IJ������������˳��ִ�еĻ�����ô��ֻ�ܵȴ� value1 ֵ��ȡ�ɹ�֮����ܼ���ִ�������ָ������������ CPU �Ŀյȴ����װ��˷�����Դ��
?
??
��������̽���˹����ڴ���ϵͳ���ڴ�ģ�ͣ������ᵽ�˸��ٻ����Լ�����һ�������⣬ͬʱ��������ָ������ִ�е����⡣��ʵ����Щ������ Java ��Ҳ�Ǵ��ڵġ���Ϊ Java ��Ŀ���ǣ�һ�α�д���������С�ÿһ�������ϵͳ���߲���ϵͳ�������Լ�������ڴ�ģ�ͣ���� Java ��Ҫʵ��һ�α�д�������е�Ŀ�꣬�ͱ����� JVM �����Ͻ�ϵͳ֮��IJ������ε��������˶��ϵͳ����õķ�ʽ���Ƕ���һ�� Java �Լ����ڴ����ģ�ͣ�Ȼ���ڲ�ͬ��Ӳ��ƽ̨�Ͳ���ϵͳ�Ϸֱ����ñ����ӿ���ʵ�֡������˼����ʵ������ cache ��һ���ģ�ͨ�������м�������ϵͳ���������Э�����⡣
Java �� 1.5 �汾��������?JSR 133 �������������� Java �еIJ����ڴ�ģ�ͺ��̹߳淶��������ķ�����־�� Java ӵ�ж�����ϵͳƽ̨�IJ����ڴ�ģ�͡��� C/C++��ͬ���ǣ�Java ��û��ֱ�Ӳ���ϵͳƽ̨�е��ڴ�ģ�ͣ������Լ�������һ���ƣ������ư����˲������ʻ��ơ�����һ����Э���Լ�ָ�������������������ݡ��� JSR 133 ���У����������µ� Java �����ڴ�ģ�ͣ�
���Կ�����������ڴ�ģ�ͺ����潲���ļ����ϵͳ�е��ڴ�ģ����ʮ�����Ƶġ��� JVM �У���������С��λ�� Thread���ڲ����� JVM �߳�ʵ��ϸ���ϣ����Լ���Ϊһ�� Thread ��Ӧһ���ں��̣߳������Ϳ��Խ�����Ϊ Thread ��Ӧһ�� CPU ���ġ�������Ҫע����ǣ������ڴ�� Java �ڴ������еĶѡ�ջ���߷�������java �� native���Ȳ�����һ�������ϵĶ���������֮��Ҳû��ֱ�ӵĶ�Ӧ��ϵ��ͬʱ���ܶ��˻�����Ϊ����Ĺ����ڴ���ʵ���� TLAB ��thread local allocation buffers���������Ͽ�����������û���κι�ϵ�ġ�
�������ͼ�У����Կ���ÿ���̵߳Ĺ����ڴ������֮���һ���Ա�֤��ͨ�� save �� load �ȵ�һϵ�еIJ�����ɵġ�JSR 133 ���ڰ汾�ж����� 8 �ֲ��������ڰ汾���������Բο���Thread and Locks�������Ǻ��������������Լ����㲻ͬ JVM ʵ����Ϊ�� 4 �ֲ���������ֻ�������ϵ��ģ��ڴ�ģ�ͻ�����Ʋ�û�иı䣨��־������������������л�Ȿ���ָ�㣩���������Dz������°汾�� 4 �ֲ��������������ַ�ʽ�Ƚ����������� 4 �ֲ����� Java �ڴ�ģ�͵Ķ�Ӧ��ϵ����ͼ��
����ֱ����������ͼ���漰�� 4 �ֲ�����
?
??
�� Java �У����Ƕ�֪����һ���߳�ֱ�Ӷ�Ӧ��һ�� Thread �������������һ���߳��DZȽ����ģ�����ֻ��Ҫ����һ�� Thread ����Ȼ����ö���� start �������ɡ������ڴ���һ�� Thread ����������߳� JVM �о���������ʲô���������Ǿ������¡�
�������ϸ���� Thread ���Դ���֪�����ڴ���һ�� Thread �����ʱ����һЩ��ʼ������֮���û��ʲôʵ���ԵIJ����������Ĺ�����ʵ���� start ���������в����ġ�Ҳ����˵��ֻ�Ǵ�����һ�� Thread ����ʹ���һ����ͨ�� Java ����ûʲôʵ���ԵIJ��졣���������Ҫ������ HotSpot 11 �е� Thread start ʵ�֣���ô��ô��ʵ�ֵĴ����أ��� Thread ��Ĵ��룬������ʼ�ĵط����ǿ��������µĴ��룺
1 2 3 4 5 /* Make sure registerNatives is the first thing <clinit> does. */ function">private static native void registerNatives(); static { registerNatives(); }�������Ϥ JNI �Ļ�����֪������� registerNatives �������ǽ� Thread ���е� java ������һ�����ص� C/C++ �������ж�Ӧ��ͬʱ�����������������ص�ʱ����õģ���������״μ��ص�ʱ��Bootstrap ����أ��ͻ�ע����Щ native ��������ô Thread �ж�����Щ native �����أ����� Thread ��Ľ�β����JDK Դ����һ�㶼�ǽ� native ������������Ľ�β����������ң���
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public static native Thread currentThread(); public static native void yield(); public static native void sleep(long millis) throws InterruptedException; private native void start0(); private native boolean isInterrupted(boolean ClearInterrupted); public final native boolean isAlive(); public native int countStackFrames(); public static native boolean holdsLock(Object obj); private static native StackTraceElement[][] dumpThreads(Thread[] threads); private static native Thread[] getThreads(); private native void setPriority0(int newPriority); private native void stop0(Object o); private native void suspend0(); private native void resume0(); private native void interrupt0(); private native void setNativeName(String name);��Щ����������˵��϶��dz���Ϥ������Ͳ����ˡ�
�ڽ��������������Ҹ��ӵ� OpenJDK ֮ǰ�м�����˵���£�
�õģ��������Ǵ� OpenJDK 11 �Ĵ��루��������Դ�룬��ο�?OpenJDK wiki��ʹ��ʲô IDE ��ȫ��������飬����ʹ�� eclipse cdt����ȫ�������������ݣ�
1 java_lang_Thread_registerNativesʲô��������Ϊɶ��������������������ʵĻ��������ȿ���?JNI ������?�������˵�£����������� JNI Ĭ�ϵ�java ������ native ������Ӧ�ķ�ʽ��JVM ���е�ʱ���ͨ�����ַ�ʽ���ұ��ط��ű��еķ��ŵķ��ţ�Ȼ��ֱ����ת��ȥ��
��������֮����Կ����� src/java.base/share/native/libjava/Thread.c �ж������������
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 static JNINativeMethod methods[] = { {"start0", "()V", (void *)&JVM_StartThread}, {"stop0", "(" OBJ ")V", (void *)&JVM_StopThread}, {"isAlive", "()Z", (void *)&JVM_IsThreadAlive}, {"suspend0", "()V", (void *)&JVM_SuspendThread}, {"resume0", "()V", (void *)&JVM_ResumeThread}, {"setPriority0", "(I)V", (void *)&JVM_SetThreadPriority}, {"yield", "()V", (void *)&JVM_Yield}, {"sleep", "(J)V", (void *)&JVM_Sleep}, {"currentThread", "()" THD, (void *)&JVM_CurrentThread}, {"countStackFrames", "()I", (void *)&JVM_CountStackFrames}, {"interrupt0", "()V", (void *)&JVM_Interrupt}, {"isInterrupted", "(Z)Z", (void *)&JVM_IsInterrupted}, {"holdsLock", "(" OBJ ")Z", (void *)&JVM_HoldsLock}, {"getThreads", "()[" THD, (void *)&JVM_GetAllThreads}, {"dumpThreads", "([" THD ")[[" STE, (void *)&JVM_DumpThreads}, {"setNativeName", "(" STR ")V", (void *)&JVM_SetNativeThreadName}, }; JNIEXPORT void JNICALL Java_java_lang_Thread_registerNatives(JNIEnv *env, jclass cls) { (*env)->RegisterNatives(env, cls, methods, ARRAY_LENGTH(methods)); }���Կ������� registerNatives �����У��������ע���˺ܶ�ı��ط����������������������ᵽ�� Thread �е����� native ������JNINativeMethod ���Ǹ�����ָ���������� JNI �У��������£�
1 2 3 4 5 6 7 8 9 /* * used in RegisterNatives to describe native method name, signature, * and function pointer. */ typedef struct { char *name; char *signature; void *fnPtr; } JNINativeMethod;���ڣ�����֪���ˣ���һ���� Java �ж���� native �������ƣ��ڶ����� Java ����ǩ�����������DZ��ط�����Ӧ��������ˣ�Java �е� start �������Ƕ�Ӧ native �� JVM_StartThread ������
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 JVM_ENTRY(void, JVM_StartThread(JNIEnv* env, jobject jthread)) JVMWrapper("JVM_StartThread"); JavaThread *native_thread = NULL; ? // We cannot hold the Threads_lock when we throw an exception, // due to rank ordering issues. Example: we might need to grab the // Heap_lock while we construct the exception. bool throw_illegal_thread_state = false; ? // We must release the Threads_lock before we can post a jvmti event // in Thread::start. { // Ensure that the C++ Thread and OSThread structures aren't freed before // we operate. MutexLocker mu(Threads_lock); ? // Since JDK 5 the java.lang.Thread threadStatus is used to prevent // re-starting an already started thread, so we should usually find // that the JavaThread is null. However for a JNI attached thread // there is a small window between the Thread object being created // (with its JavaThread set) and the update to its threadStatus, so we // have to check for this if (java_lang_Thread::thread(JNIHandles::resolve_non_null(jthread)) != NULL) { throw_illegal_thread_state = true; } else { // We could also check the stillborn flag to see if this thread was already stopped, but // for historical reasons we let the thread detect that itself when it starts running ? jlong size = java_lang_Thread::stackSize(JNIHandles::resolve_non_null(jthread)); // Allocate the C++ Thread structure and create the native thread. The // stack size retrieved from java is 64-bit signed, but the constructor takes // size_t (an unsigned type), which may be 32 or 64-bit depending on the platform. // - Avoid truncating on 32-bit platforms if size is greater than UINT_MAX. // - Avoid passing negative values which would result in really large stacks. NOT_LP64(if (size > SIZE_MAX) size = SIZE_MAX;) size_t sz = size > 0 ? (size_t) size : 0; // �ص㿴������� native_thread = new JavaThread(&thread_entry, sz); ? // At this point it may be possible that no osthread was created for the // JavaThread due to lack of memory. Check for this situation and throw // an exception if necessary. Eventually we may want to change this so // that we only grab the lock if the thread was created successfully - // then we can also do this check and throw the exception in the // JavaThread constructor. if (native_thread->osthread() != NULL) { // Note: the current thread is not being used within "prepare". native_thread->prepare(jthread); } } } ? if (throw_illegal_thread_state) { THROW(vmSymbols::java_lang_IllegalThreadStateException()); } ? assert(native_thread != NULL, "Starting null thread?"); ? if (native_thread->osthread() == NULL) { // No one should hold a reference to the 'native_thread'. native_thread->smr_delete(); if (JvmtiExport::should_post_resource_exhausted()) { JvmtiExport::post_resource_exhausted( JVMTI_RESOURCE_EXHAUSTED_OOM_ERROR | JVMTI_RESOURCE_EXHAUSTED_THREADS, os::native_thread_creation_failed_msg()); } THROW_MSG(vmSymbols::java_lang_OutOfMemoryError(), os::native_thread_creation_failed_msg()); } ? Thread::start(native_thread); ? JVM_END������뱾�������࣬�����кܶ��ע�ͣ��������Ǿ��ܺܺõ�������δ����ˡ�����Ҫ��ע���ص�����һ�У�
1 native_thread = new JavaThread(&thread_entry, sz);���ﴴ����һ�� JavaThread �����Ҹ���������������һ�����Ҳ��ܣ��������ǻ��ص�˵�����ڶ����� stack size��Ҳ����ÿһ���̵߳�ջ��С��������������ڴ��� Thread �����ʱ��ָ����Ҳ�������� JVM ����������-XSS����ȥ���£�
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 JavaThread::JavaThread(ThreadFunction entry_point, size_t stack_sz) : Thread() { initialize(); _jni_attach_state = _not_attaching_via_jni; set_entry_point(entry_point); // Create the native thread itself. // %note runtime_23 os::ThreadType thr_type = os::java_thread; thr_type = entry_point == &compiler_thread_entry ? os::compiler_thread : os::java_thread; // ͨ�� os ��� create_thread ����������һ���߳� os::create_thread(this, thr_type, stack_sz); // The _osthread may be NULL here because we ran out of memory (too many threads active). // We need to throw and OutOfMemoryError - however we cannot do this here because the caller // may hold a lock and all locks must be unlocked before throwing the exception (throwing // the exception consists of creating the exception object & initializing it, initialization // will leave the VM via a JavaCall and then all locks must be unlocked). // // The thread is still suspended when we reach here. Thread must be explicit started // by creator! Furthermore, the thread must also explicitly be added to the Threads list // by calling Threads:add. The reason why this is not done here, is because the thread // object must be fully initialized (take a look at JVM_Start) }���Կ������ص���ͨ�� os ��� create_thread ����������һ���̣߳���Ϊ JVM ����ƽ̨�ģ����Ҳ�ͬ����ϵͳ�ϵ��߳�ʵ�ֻ��ƿ����Dz�һ���ģ��������� create_thread �϶����ж����Բ�ͬƽ̨��ʵ�֣����Dz鿴���������ʵ�־�֪���ˣ�?
���Կ�����HotSpot �ṩ����Ҫ�IJ���ϵͳ�ϵ�ʵ�֣���Ϊ�ڷ������ϣ�linux ��ռ���Ǻܸߵģ������������Ϳ��� linux �ϵ�ʵ�ּ��ɣ�
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 bool os::create_thread(Thread* thread, ThreadType thr_type, size_t req_stack_size) { ... // init thread attributes pthread_attr_t attr; pthread_attr_init(&attr); pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_DETACHED); // Calculate stack size if it's not specified by caller. size_t stack_size = os::Posix::get_initial_stack_size(thr_type, req_stack_size); // In the Linux NPTL pthread implementation the guard size mechanism // is not implemented properly. The posix standard requires adding // the size of the guard pages to the stack size, instead Linux // takes the space out of 'stacksize'. Thus we adapt the requested // stack_size by the size of the guard pages to mimick proper // behaviour. However, be careful not to end up with a size // of zero due to overflow. Don't add the guard page in that case. size_t guard_size = os::Linux::default_guard_size(thr_type); if (stack_size <= SIZE_MAX - guard_size) { stack_size += guard_size; } assert(is_aligned(stack_size, os::vm_page_size()), "stack_size not aligned"); ? int status = pthread_attr_setstacksize(&attr, stack_size); assert_status(status == 0, status, "pthread_attr_setstacksize"); ? // Configure glibc guard page. pthread_attr_setguardsize(&attr, os::Linux::default_guard_size(thr_type)); ... pthread_t tid; // �����������߳� int ret = pthread_create(&tid, &attr, (void* (*)(void*)) thread_native_entry, thread); ... }��������Ƚϳ��������ʡ�Բ��֣�ֻ�������̴߳���������صIJ��֡����Կ������� linux ƽ̨�ϣ�JVM ���߳���ͨ������������ pthread �������������̵߳ģ�������Ҫע���µ��ǣ���ָ���߳�ջ��С��ʱ����������Աָ�����پ�ʵ���Ƕ��ٵģ�����Ҫ����ϵͳƽ̨���������ۺϾ����ġ�
��������Ǵ����������ˣ�Java Thread �ڵײ��Ƕ�Ӧ��һ�� pthread �̡߳�������һ�����⣬���ǵײ������ִ������ָ���� run �������أ������ȿ��´������������̵߳���һ�У�
1 2 3 pthread_t tid; // �����������߳� int ret = pthread_create(&tid, &attr, (void* (*)(void*)) thread_native_entry, thread);����ͨ�� pthread_create ���������������̣߳����ǿ�������ӿڵĶ��壺
1 2 int pthread_create(pthread_t *thread, const pthread_attr_t *attr, void *(*start_routine)(void *), void *arg);��һ���� pthread_t �ṹ������ָ�룬����߳���Ϣ�ģ��ڶ������̵߳����ԣ����������߳��壬Ҳ�����߳�ʵ��ִ�еĺ��������ĸ����߳���IJ����б���
�����������ӿڵĵط�������ָ�����߳��庯���� thread_native_entry�������� thread ָ�롣�����ȿ��� thread_native_entry ��������Ķ��壺
1 2 3 4 5 6 7 // Thread start routine for all newly created threads static void *thread_native_entry(Thread *thread) { ... // call one more level start routine thread->run(); ... }ͬ���أ�����ʡ���˺ܶ���룬ֻ�������ص���롣ͨ��ע�����ǿ���֪����thread->run() ��һ���������ִ������ run �����ĵط�������������ص��ǣ�thread ָ��ָ����˭������ run ������ʵ���������ģ�����֪�� thread ָ�������Ǵ��ݽ����ģ����ͨ������Ѱ�Ҵ������������ڴ����̵߳�ʱ������ִ�������µ��ã�����㻹�ǵõĻ�����
1 os::create_thread(this, thr_type, stack_sz);�������ǽ� thread ָ�븳ֵΪ this��this ���� JavaThread �����ǵ�������ǰ�����ͨ������ JavaThread �����������������̵߳ġ����ԣ��������ڿ��� JavaThread ��� run ������
1 2 3 4 5 6 7 // The first routine called by a new Java thread void JavaThread::run() { ... // We call another function to do the rest so we are sure that the stack addresses used // from there will be lower than the stack base just computed thread_main_inner(); }�����ص��ǵ����� thread_main_inner ������
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 void JavaThread::thread_main_inner() { assert(JavaThread::current() == this, "sanity check"); assert(this->threadObj() != NULL, "just checking"); ? // Execute thread entry point unless this thread has a pending exception // or has been stopped before starting. // Note: Due to JVM_StopThread we can have pending exceptions already! if (!this->has_pending_exception() && !java_lang_Thread::is_stillborn(this->threadObj())) { { ResourceMark rm(this); this->set_native_thread_name(this->get_thread_name()); } HandleMark hm(this); // ���↑ʼ���� java thread �� run ������������ this->entry_point()(this, this); } ? DTRACE_THREAD_PROBE(stop, this); ? // java �е� run ����ִ������ˣ�������Ҫ�˳��̲߳�������Դ this->exit(false); // delete cpp �Ķ��� this->smr_delete(); }����������ǵĺ���ִ�����ˣ���Java Thread �е� run �������� this->entry_point()(this, this); ������õġ�������ĵ��÷�ʽ��֪����entry_point() ���ص���һ������ָ�룬Ȼ��ֱ��ִ���˵��á�entry_point ����ʵ�����£�
1 2 ThreadFunction entry_point() const { return _entry_point; }����ֱ�ӷŻ��� _entry_point �� ThreadFunction ����ָ�룬ThreadFunction ������ʵ���Ǻ���ָ�룺
1 2 typedef void (*ThreadFunction)(JavaThread*, TRAPS);��ˣ��ص��������� _entry_point �����︳ֵ�ģ��������Ҫ�ᵽǰ�����µ�һ���ӣ��ڴ��� JavaThread �����ʱ�����Ǵ�����һ������ָ�� thread_entry��
1 2 native_thread = new JavaThread(&thread_entry, sz);�������������� JavaThread �ж� thread_entry �Ĵ�����
1 2 3 4 5 6 7 JavaThread::JavaThread(ThreadFunction entry_point, size_t stack_sz) : Thread() { ... set_entry_point(entry_point); ... }ok�����������������������������ҪѰ�ҵ� _entry_point ��ʵ���� thread_entry ָ�룡
���ڿ��� thread_entry ָ��ָ��ĺ�����
1 2 3 4 5 6 7 8 9 10 11 12 static void thread_entry(JavaThread* thread, TRAPS) { HandleMark hm(THREAD); Handle obj(THREAD, thread->threadObj()); JavaValue result(T_VOID); JavaCalls::call_virtual(&result, obj, SystemDictionary::Thread_klass(), vmSymbols::run_method_name(), vmSymbols::void_method_signature(), THREAD); }������ǵ������� java �� run �����ĵط������Ǻ����ܺ�ֱ�۵Ŀ�������������Ҫ����һ�� call_virtual �������õļ�����������һ���Ǵ�ź���ִ�н���ģ���Ϊjava Thread �е� run �� void �͵ģ����Բ��ع��ģ��ڶ����� java thread object ���������� java Thread class �����ĸ��������� run ���������ƣ���ʵ�����ַ�����run����������Ƿ�����ǩ�������һ���ǵ�ǰִ���̵߳ĺ꣬ͨ���������Ի�õ���ǰִ���̵߳�ָ�룬ָ�� JavaThread ���������������ȿ��� run_method_name ���壺
1 2 3 4 5 6 7 static Symbol* name() { \ return _symbols[VM_SYMBOL_ENUM_NAME(name)]; \ } VM_SYMBOLS_DO(VM_SYMBOL_DECLARE, VM_SYMBOL_DECLARE)������ͨ���궨���ķ�ʽָ���ģ�����ֱ�������������չ�ĵط���
1 2 template(run_method_name, "run") \����ͨ�� cpp ģ�淽ʽ���壬��������֪���� run_method_name ����궨��չ��֮����� ��run�� �� Symbol ָ�롣ͬʱ void_method_signature ���Կ������壺
1 2 template(void_method_signature, "()V") \������� public void run() ������ǩ������
�õģ���������֪���˲�������Ϣ������ call_virtual �������������õ� java �����ģ�������ֻ��˵��ͨ�� JVM call_stub ����ָ��ָ���ָ�뺯����ת�� vtable ʵ�ֵġ����� call_stub ʵ�ֻ��ƣ��� JVM �зdz����ӵ�һ������ģ�飬���ģ���漰�� Java ���ڶ� invoke* ����ֽ���ִ��ϸ��������Щ���ݾ��Բ���һƪ�����ܹ�����ģ����������һ���Ӻ���ר��д�Ľ�������ʵ�֣���һ�£������漰��࣬����ֻ�Ǽļ�����ࣩ������㼱���˽��������ݣ����Բο� HotSpot ����ר�ҵ����¡��ðɣ�������һ���ӡ�
������������������ java �� thread �Ĵ������������̣��Լ� run ����ִ�еĹ��̡������ܽ��£�
Java �̴߳����������������£�
1 2 3 4 5 6 java_lang_Thread->JNI:start0 JNI->JavaThread:new JavaThread->os:create_thread os->os_linux:pthread_create os_linux->JavaThread:thread_entry JavaThread->java_lang_Thread:run?
??
synchronized �� Java ����ͬ�������Ļ����������� java ���Բ����ṩ���̼߳�ͬ���ֶΡ����DZ�д����һ�δ��룺
1 2 3 4 5 6 7 8 9 10 11 12 public class SyncTest { private static final Object lock = new Object(); ? public static void main(String[] args) { int a = 0; synchronized (lock) { a++; } System.out.println("Result: " + a); } }�������ͬ���IJ������ǻῴ�������ֽ��룺
1 2 3 4 5 monitorenter iinc 1 by 1 aload_2 monitorexit����ʵ�� javac ���������һ��С��Ϸ���ڱ���ʱ�� synchronized ͬ�����ǰ����� montor ������˳����ֽ���ָ�������һ������ java ����Ա������ָ�ơ�
����������Ҫ̽�� synchronized ��ʵ�ֻ��ƣ�����Ҫ̽�� monitorenter ��monitorexit ָ���ִ�й����ˡ�
����֪������ HotSpot JVM ���ڵ�ʱ���ֽ����ִ����ͨ����������ִ��ÿһ���ֽ���ָ��ģ��������ַ�ʽЧ�ʵ��¡����������ݣ���֪��Ϊɶ���ַ�ʽЧ�ʵ����أ�JVM Ҳ��ͨ�� C/C++ ����д�ģ�ΪɶЧ�ʾ���ô���أ���ʵ��νЧ�ʵ��£��� CPU ������ʵ����һ�������ܼĹ���ȴ��Ҫ������ CPU ����ָ������ɣ��Ӷ�����Ч�ʵ��¡����ǣ����ǻ�Ҫ�ʣ�Ϊɶһ���Ĺ��ܻ�����ܶ�Ļ���ָ���أ�ԭ����������Java �������֮������ܶ��ֽ���ָ�ÿһ���ֽ���ָ���� JVM �ײ�ִ�е�ʱ���ֻ���һ�� C ���룬��һ�� C �����ڱ���֮���ֻ��ɺܶ�Ļ���ָ�����һ�������ǵ� java �������յ�����ָ��һ�㣬�������Ļ���ָ���ָ�����ģ���˾͵����� Java ִ��Ч�ʷdz����£���˵���ñ��ò�����ڻ��ڡ�
���������ϸ˼���£���ô�Ż���������أ��ֽ����ǿ϶����ܶ��ģ���Ϊ JVM ��һ����д���������е�������ǿ�����ɵġ���ʵ�����ǻᷢ�֣�����ĸ��������� Java �ͻ���ָ��֮�����һ�� C/C++�������� GCC ֮��ı������ֲ����������Ե��������룬�������Ļ�����Ч����Ȼ���Ƿdz��ߡ���ˣ����ǻ��룬�ܲ������� C/C++ �������ܣ�ֱ�ӽ� java �ֽ���ͱ��ػ��������һ����Ӧ�أ��ǵģ����Եģ�HotSpot ����ʦ������뵽�ˣ�������ڵĽ���ִ�����ܿ�ͱ������ˣ�ת������ģ��ִ������ʲô��ģ��ִ����������˼�壬ģ����ǽ�һ�� java �ֽ���ͨ�����˹��ֶ����ķ�ʽ��дΪ�̶�ģʽ�Ļ���ָ��ⲿ�ֲ�����Ҫ GCC �İ����������Ϳ��Դ�����������Ҫִ�еĻ���ָ����Բ������Ч�ʡ� ��νģ�棬���Ƕ������ֽ��뵽������ת����ͳһ��ʽ�����������е�ģ��һ����ִ���ֽ����ʱ������ģ����ܵõ���Ӧ�ġ��˹������ŵĻ����롫˵���������Ҫ��̾��JVM ���ֽ���ִ�е��Ź������ǡ��˹������ܵĽ������
�����������ҽ����ˣ��ִ� HotSpot JVM �в���ģ��ִ����ִ���ֽڵ�ԭ���Լ������ļ����������������Ǿ�Ҫ�� OpenJDK �е�ģ��ִ������̽�� monitorenter �� monitorexit ָ��ִ�е�ϸ�ڹ��̡�
�� OpenJDK 11 ��Դ���У����� JVM �Ľ���������������ϵ�ԭʼ�����������ڣ�src/hotspot/share/interpreter Ŀ¼�£�ͨ�����Ŀ¼�µĴ����ļ��������Ǿͺ������ҵ�ģ��������Ĵ���λ�ã�templateInterpreter.cpp��ͨ�����������ʵ�֣�����֪������ʵ�ֽ����Ӧ���������ģ������ templateTable.cpp �ж���ģ�����ļ��еĴ��������࣬ȫ���ֽ����Ӧ�����ػ������ʵ��������������ֻ�Ƿ��� monitor ��ص����ݣ�
1 2 3 def(Bytecodes::_monitorenter , ____|disp|clvm|____, atos, vtos, monitorenter , _ ); def(Bytecodes::_monitorexit , ____|____|clvm|____, atos, vtos, monitorexit , _ );�����ÿһ�еĺ��壬�ڴ����ж���˵������������ֻҪ֪�� monitorenter ������ monitorexit �������Ƕ�Ӧ�ֽ���Ļ�����ģ���λ�ã��������ǿ��� monitorenter ��ʵ�֣�
��Ϊ��ʵ�ʵĻ������Ǻ� CPU ��صģ���� JVM �ṩ���˼����������� CPU �Ķ�Ӧ�汾������������Ȼ���������� x86 ��ʵ�֣�����Ҫ������ˣ��Dz����е㼤�������Dz�Ҫ�ţ�JVM ��Ի��ĵ����Ѿ����˷dz��걸�ķ�װ������������Ĵ��뿴��������ͨ�� C ����ûɶ���𣩣�
1 2 3 4 5 6 7 8 9 void TemplateTable::monitorenter() { ... // store object __ movptr(Address(rmon, BasicObjectLock::obj_offset_in_bytes()), rax); // ��תִ�� lock_object ���� __ lock_object(rmon); ... }����������Ȼֻ�����ص���벿�֣�����Ƚϳ���ǰ���кܶ�ָ���dz�ʼ��ִ�л����ģ�����ص����תִ�� lock_object ������ͬ���������Ҳ���в�ͬ CPU ƽ̨ʵ�ֵģ����ǻ��ǿ� X86 ƽ̨�ģ�
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 // Lock object // // Args: // rdx, c_rarg1: BasicObjectLock to be used for locking // // Kills: // rax, rbx void InterpreterMacroAssembler::lock_object(Register lock_reg) { if (UseHeavyMonitors) { call_VM(noreg, CAST_FROM_FN_PTR(address, InterpreterRuntime::monitorenter), lock_reg); } else { // ִ�����Ż��������֣����磺���ֻ����������ȵ� // ���һ���Ż���ʩ��ִ���ˣ�������Ҫ���� monitor����ִ�����£���ʵ�������Ǹ� if ��֧��һ���� // Call the runtime routine for slow case call_VM(noreg, CAST_FROM_FN_PTR(address, InterpreterRuntime::monitorenter), lock_reg); } ? }������������������ն���ִ���� InterpreterRuntime::monitorenter ���������������������ģ��ִ��������ã�����ִ����Ҳ��ִ����������Զ����� InterpreterRuntime ���£�
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 // Synchronization // // The interpreter's synchronization code is factored out so that it can // be shared by method invocation and synchronized blocks. //%note synchronization_3 //%note monitor_1 IRT_ENTRY_NO_ASYNC(void, InterpreterRuntime::monitorenter(JavaThread* thread, BasicObjectLock* elem)) Handle h_obj(thread, elem->obj()); if (UseBiasedLocking) { // Retry fast entry if bias is revoked to avoid unnecessary inflation ObjectSynchronizer::fast_enter(h_obj, elem->lock(), true, CHECK); } else { ObjectSynchronizer::slow_enter(h_obj, elem->lock(), CHECK); } IRT_END����Ĵ��룬��ԭʼ�Ĵ����������ɾ���������˺��Ĺؼ�������ʵ��������ܼ����Ǹ��� UseBiasedLocking ��������ֱ�ִ�� fast_enter ���� slow_enter �������� UseBiasedLocking ������������ƾ��ܿ����������� JVM 1.6 ֮��Ĭ��ʹ�ܵ�ƫ�����Ż�������ͨ�� JVM �������� -XX:+/-UseBiasedLocking �����ƿ��ء�ʲô��������ʲô��ƫ������ok����ţ��������Ǿ�Ҫ�����ˡ�
��Ϊ�������� JDK 11 �Ϸ������������Ĵ��룬�϶���ִ�� fast_enter ���������������Ϊɶ�� fast��������������֪���ˡ�
������ fast_enter �����Ķ��壺
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 // Fast Monitor Enter/Exit // This the fast monitor enter. The interpreter and compiler use // some assembly copies of this code. Make sure update those code // if the following function is changed. The implementation is // extremely sensitive to race condition. Be careful. void ObjectSynchronizer::fast_enter(Handle obj, BasicLock* lock, bool attempt_rebias, TRAPS) { if (UseBiasedLocking) { if (!SafepointSynchronize::is_at_safepoint()) { BiasedLocking::Condition cond = BiasedLocking::revoke_and_rebias(obj, attempt_rebias, THREAD); if (cond == BiasedLocking::BIAS_REVOKED_AND_REBIASED) { return; } } else { assert(!attempt_rebias, "can not rebias toward VM thread"); BiasedLocking::revoke_at_safepoint(obj); } assert(!obj->mark()->has_bias_pattern(), "biases should be revoked by now"); } ? slow_enter(obj, lock, THREAD); }���↑ʼ����Ҫ�ж� UseBiasedLocking������� true �Ļ�������Ŀ�ʼִ���Ż����������ǻ� fall back �� slow_enter �ġ��Dz��Ǹо��ж� UseBiasedLocking �еㆪ�£���ʵ���ǵģ���Ϊ��������ںܶ�ط�������õģ�����ж��DZ�Ҫ�ģ�Ϊ�˷���������Ĵ��������������Ҫ�ų�?OpenJDK �ٷ� wiki?��������Ż���ԭ��ͼ��

����ͼզһ�����ܸ��ӣ�����ܿ����������ǣ������ң��������ϸ��������Ĵ�����������Լ���� JVM Դ�볢�����⣬��϶�����ȫ������ͼ��
Ԥ���������������ݻ�Ƚ����ԣ����ݱȽϸ��ӣ���������Ϣһ����������
�ڽ�����������ͼ֮ǰ����Ҫ����һ�� Java ������ڴ沼�֣���Ϊ����ͼ�е�ʵ��ԭ�����dz������ java �����ͷ��ɵġ�Java �������ڴ�Ľṹ�����Ϸ�Ϊ������ͷ�Ͷ����壬���ж���ͷ�洢����������Ϣ���������Ŷ������ݲ��֡���ô���dz����о� JVM Դ�����ȡ java �����ڴ沼��֮�⣬����ʲô�취��֪������ڴ沼���أ��еģ��� OpenJDK �����У���һ���ӹ��̽�����jol��ȫ���ǣ�java object layout���ǵľ��� java ���ֵ���˼������һ�����߿⣬ͨ���������Ի�ȡ JVM �ж�����Ϣ����������չʾһ�������ӣ���Ҳ�ǹٷ��������ӣ���
1 2 3 4 5 6 7 8 9 10 11 public class JOLTest { public static void main(String[] args) { System.out.println(VM.current().details()); System.out.println(ClassLayout.parseClass(A.class).toPrintable()); } ? public static class A { boolean f; } }����ͨ�� JOL �Ľӿ�����ȡ�� A �Ķ����ڴ沼�֣�ִ��֮������������ݣ�
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 # Running 64-bit HotSpot VM. # Using compressed oop with 3-bit shift. # Using compressed klass with 3-bit shift. # WARNING | Compressed references base/shifts are guessed by the experiment! # WARNING | Therefore, computed addresses are just guesses, and ARE NOT RELIABLE. # WARNING | Make sure to attach Serviceability Agent to get the reliable addresses. # Objects are 8 bytes aligned. # Field sizes by type: 4, 1, 1, 2, 2, 4, 4, 8, 8 [bytes] # Array element sizes: 4, 1, 1, 2, 2, 4, 4, 8, 8 [bytes] ? JOLTest$A object internals: OFFSET SIZE TYPE DESCRIPTION VALUE 0 12 (object header) N/A 12 1 boolean A.f N/A 13 3 (loss due to the next object alignment) Instance size: 16 bytes Space losses: 0 bytes internal + 3 bytes external = 3 bytes total�������ǿ�������˺ܶ���Ϣ������������ A �Ķ������£�12 byte �Ķ���ͷ + 1 byte �Ķ����� + 3 byte ����䲿�֡��������Ƿֱ��Ҫ˵���£�
����ͷ���� JVM �Ĵ��������ǿ��Կ���һ�������ͷ�����壺
1 2 3 4 5 6 volatile markOop _mark; union _metadata { Klass* _klass; narrowKlass _compressed_klass; } _metadata;���Կ�����Ϊ�����֣���һ���־��� mark ���֣��ٷ���֮Ϊ mark word���ڶ����� klass ������ָ�룬ָ�������������������� mark word ������һ��ϵͳ�ֿ����� 64 bit ϵͳ�Ͼ��� 8 ���ֽڣ����������־�����ǿ��Կ��������Ĭ��ʹ���� compressed klass����˵ڶ����ֵ� union ��ʵ���� narrowKlass ���͵ģ�������Ǽ������� narrowKlass �Ķ����֪�����Ǹ� 32 bit �� unsigned int ���ͣ���˽�ռ�� 4 ���ֽڣ����Զ����ͷ����������Ϊ 12 �ֽڡ�
�����壺��Ϊ A ��ֻ������һ���ֶΣ��� boolean ���͵ģ��� JVM �ײ�ռ��һ���ֽڵij���
��䲿�֣�����Ķ���ͷ�Ͷ����峤�ȵ��ܺ�Ϊ 13 �ֽڣ���Ϊ JVM ���ڴ����� 8 �ֽڳ��ȶ���ģ����������Ҫ��� 3 ���ֽڵij����ǵ�����ij��ȵ��� 16 �ֽ�
��������˵������һ�� java ������ڴ沼�֣���������չʾ���� JVM ������ oop ѹ�������Ľ���������ͨ�� -XX:-UseCompressedOops ���ر������ر�֮��IJ�������ͼ�����DZ����ڴ沼�֣���
����ص����ǵĻ��⣬�����ص���Ҫ��ע���Ƕ����ͷ�����塣�������ǿ����������ͷ���ܹ����Է�Ϊ�������֣���һ���� mark word ���ڶ����������Ķ���ָ����Ϣ������ Mark word ���ڴ洢������������ʱ�����ݣ��� hash code��GC �ִ�����ȵ���Ϣ������ʵ��ƫ�����Ĺؼ���
����ͷ����Ϣ���������������������صĶ�����Ϣ�����ǵ�������Ŀռ�Ч�ʣ�mark word ����Ƴ�һ���ǹ̶����ݽṹ�Ա��ڼ�С�Ŀռ��ڴ洢���������Ϣ��������ݶ����״̬�����Լ��Ĵ洢�ռ䡣�� JVM �У�mark word �ڴ沼�ֶ����� /src/hotspot/share/oops/markOop.hpp �У�������ļ���ע����������˵������ 32bit �� 64bit ϵͳ�ж���ͬ״̬�µ� mark word ���֣�
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 // 32 bits: // -------- // hash:25 ------------>| age:4 biased_lock:1 lock:2 (normal object) // JavaThread*:23 epoch:2 age:4 biased_lock:1 lock:2 (biased object) // size:32 ------------------------------------------>| (CMS free block) // PromotedObject*:29 ---------->| promo_bits:3 ----->| (CMS promoted object) // // 64 bits: // -------- // unused:25 hash:31 -->| unused:1 age:4 biased_lock:1 lock:2 (normal object) // JavaThread*:54 epoch:2 unused:1 age:4 biased_lock:1 lock:2 (biased object) // PromotedObject*:61 --------------------->| promo_bits:3 ----->| (CMS promoted object) // size:64 ----------------------------------------------------->| (CMS free block) // // unused:25 hash:31 -->| cms_free:1 age:4 biased_lock:1 lock:2 (COOPs && normal object) // JavaThread*:54 epoch:2 cms_free:1 age:4 biased_lock:1 lock:2 (COOPs && biased object) // narrowOop:32 unused:24 cms_free:1 unused:4 promo_bits:3 ----->| (COOPs && CMS promoted object) // unused:21 size:35 -->| cms_free:1 unused:7 ------------------>| (COOPs && CMS free block)������״̬��ǰ����״̬��������Ҫ�ص��ע�ģ�normal object �� biased object����ϸ���������ֵ�ͷ���壬������� bit ��������ƫ��������ͨ���IJ��֣�����ͺ�ǰ�� OpenJDK wiki �е�ͼ�����ˣ��ܽ����£�
biased_lock lock ״̬ 1 01 ��ƫ�á���δ����δƫ�� 0 01 �ѽ���������ƫ�� �C 00 ���������� �C 01 ������������������ݲο� OpenJDK wiki �е�ͼ��Ϊ�˷�����������������һ�Σ�
��������������������ͼ����һ�£����Ƚ���һ��ʲô��ƫ��������νƫ�ã�����ƫ��ijһ���̵߳���˼��Ҳ����˵��������ȼ����Լ���ƫ����̳߳��С��ڵ����߳�������������ʱ��ƫ�������������ˡ����һ���߳�������ͣ�λ�ȡ������ô��ȡ�Ĺ��������û�з�����̬����ô�����������ص�ͬ�����̣�ֱ�Ӿͻ����ִ�У��������Դ��������ܡ�ƫ������ JDK 1.6 �������һ�����Ż��ֶΣ�����Ŀ�ľ������������������õ�����µ�ͬ����������һ������������ܡ����ﻹ�漰����������������������Ҳ�� JDK 1.6 �����һ�����Ż����ƣ���ν�������������ʹ�ò���ϵͳ���������ʵ�ִ�ͳ�����Եģ�������Ƕ��ϣ���ͳ�ķ�ʽ����������������ν��������ԭ����ͬ���ķ�ʽ��һ�ֱ��������ᵼ���̵߳�״̬�л������߳�״̬���л���һ���൱�������IJ������� JVM 6 ���ϰ汾�У�Ĭ��ʹ��ƫ���Ż���������������ͼ�У�ֻҪ�������µĶ�����ָ����ͼ�е���������һ���µĶ�����δ������δƫ�õ��ǿ���ƫ�õ�״̬��Ҳ�����������ĵ�һ�У����ʱ������и��߳�����ȡ�������������ô��ֱ�ӽ�����ƫ��״̬�����״̬��δƫ��״̬�IJ�����ԭ����ͷ�� 25 bit �� hash code ����� 23 bit �� thread ָ��� 2 bit �ķִ���Ϣ����ôԭʼ����Ϣȥ�������أ���ʵ�ʹ洢����ȡ�������߳�ջ���ˣ��������ǻ��ڴ����п�����һ�㡣������һ���IJ��������Ǿ��ڶ���ͷ���洢�����߳�ָ����Ϣ����������������Ѿ�������̳߳����ˣ��൱�ڱ������˻����������´ε�����߳��ڴ˻�ȡ�������ʱ��ֻҪ״̬û�з����仯������Ҫ�Ŀ�������һ��ָ��ıȽ����㣬����������Ƿdz������ġ�������ij���̳߳��������������ʱ�����������һ���߳��������ˣ�����ƫ��״̬�������ᴥ������ƫ�õ��������ʱ����Է�Ϊ����������������������̳߳�Ϊ �߳� A�������ij�Ϊ�߳� B����
������������IJ����Dz�ͬ�ģ�����ֱ�����
��һ����������ڶ����״̬��ƫ�ö�����δ������������Ƚ�����״̬��Ϊ����ƫ�ö�����δ������Ȼ�������̵�ջ�ռ��½�һ�� lock record �Ŀռ䣬���ڴ洢����Ŀǰ�� mark word �Ŀ�����Ȼ���������ʹ�� CAS �������Խ������ mark word ����ָ�� lock record �ռ䡣���������³ɹ��ˣ���ô����߳̾�ӵ���˸ö������������ mark word ������־λ��� 00����ʾ��ǰ��������������������״̬�������������ͼ��ʾ����ͼ������ǰ����ͼ��������
�ڶ�����������ǵ�ǰ�������ڴ�������״̬�����ʱ����Ȼ������Ϊ���������������Ǵ�ʱ�߳� B ��ȡ����ʧ�ܣ�����������������С����͡����������׳�Ϊһ��������������
���⣬��Ҫ˵�����ǣ���һ���߳�����������ij�������ʱ������һ���̹߳�������Ҳ�ᵼ���������ͣ����뵽�������������ܽ������Ļ�������û�о�������ƫ��������������������������������������������������
��Ҫ˵�����ǣ�ƫ���������������Ĺ�ϵ�����ǻ���ȡ�����߾�����ϵ�����������ڲ�ͬ����µIJ�ͬ�����Ż��ֶΡ��������Ҫ�ᵽ�ڸ����ϵ������࣬ͨ�����Է�Ϊ�����������ֹ�������ν��������������Ϊ����Ҳ�����ֵ�ͬ�����ֶΣ�����ִ���������IJ������Ϳ϶���������⣻��ν�ֹ��������ǻ��ֹ۵�Ԥ��ϵͳ��ǰ��״̬����Ϊ״̬�Ƿ���Ԥ�ڵģ���˲�����������ͬ��Ҳ�������ͬ����������ɷ����˾�̬�����˱ܣ�Ȼ���ٰ���һ���IJ������ԡ��� java �У��ܶഫͳ��ͬ����ʽ������ synchronized�������������DZ��������� java 9 ���� Thread �����¼�����һ���ӿ� onSpinWait ����һ���ֹ����������� JUC �кܶ��ԭ�ӹ����ʹ�õ��� CAS��Compare And Swap�����������ֲ��������������� CPU �ṩ���ض�ԭ�Ӳ���ָ����ڳ�ͻ���ķ�ʽ��ʵ�ֵ�һ���ֹ�������ͬ��������
����������ϸ������ JVM �еĸ������Ż��ļ���ϸ�ڣ��������ǿ����� JVM �Ĵ���ʵ��������β����ġ��ڿ��� fast_enter ������ʱ�����˴��������ж� safepoint �ĵط����������Ȳ��ù��ģ�����Ǻ� JVM �� GC �йص����ݣ���������������ĵ����ݡ�һ����ԣ�����ִ�е�?revoke_and_rebias?��������У���������Ƚϳ�����Ҫ����ִ�� OpenJDK wiki ��ͼ�� revoke �� rebias ����������Ͳ����������ϸ�ڷ����ˡ�
�� fas_enter �����п��Կ�����������£����ǻ�ִ�е� slow_enter �����У�
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 // Interpreter/Compiler Slow Case // This routine is used to handle interpreter/compiler slow case // We don't need to use fast path here, because it must have been // failed in the interpreter/compiler code. void ObjectSynchronizer::slow_enter(Handle obj, BasicLock* lock, TRAPS) { markOop mark = obj->mark(); assert(!mark->has_bias_pattern(), "should not see bias pattern here"); ? if (mark->is_neutral()) { // Anticipate successful CAS -- the ST of the displaced mark must // be visible <= the ST performed by the CAS. lock->set_displaced_header(mark); if (mark == obj()->cas_set_mark((markOop) lock, mark)) { TEVENT(slow_enter: release stacklock); return; } // Fall through to inflate() ... } else if (mark->has_locker() && THREAD->is_lock_owned((address)mark->locker())) { assert(lock != mark->locker(), "must not re-lock the same lock"); assert(lock != (BasicLock*)obj->mark(), "don't relock with same BasicLock"); lock->set_displaced_header(NULL); return; } ? // The object header will never be displaced to this lock, // so it does not matter what the value is, except that it // must be non-zero to avoid looking like a re-entrant lock, // and must not look locked either. lock->set_displaced_header(markOopDesc::unused_mark()); ObjectSynchronizer::inflate(THREAD, obj(), inflate_cause_monitor_enter)->enter(THREAD); }�����ִ�����Ƚϼ�࣬��Ҫִ������ OpenJDK wiki �е����Ż��������Ȼ��ж϶������Ƿ�Ϊ�����ģ�neutral����
1 2 3 4 5 6 bool is_neutral() const { // ����� biased_lock_mask_in_place �� 7 // unlocked_value ֵ�� 1 return (mask_bits(value(), biased_lock_mask_in_place) == unlocked_value); }������ж�Ҳ�DZȽϼģ����ǽ� mark word �е���� 7 �� bit �����������㣬���õ���ֵ�� 1 ���бȽϣ�������� 1 �ͱ�ʾ�����������ģ�Ҳ����û�б��κ��߳������������ʧ�ܡ�������Ҫ��һ�����⣬�Ǿ���Ϊʲô����Ҫ�� mark word ������ 7 �� bit �����������㣿�������Ǿ���Ҫ�ٴο����� biase ģʽ�µĶ��� mark word �IJ��֣������� 32 bit Ϊ������Ȼ������� oopDesc ע����������
1 2 3 4 5 hash:25 ------------>| age:4 biased_lock:1 lock:2 (normal object) JavaThread*:23 epoch:2 age:4 biased_lock:1 lock:2 (biased object) size:32 ------------------------------------------>| (CMS free block) PromotedObject*:29 ---------->| promo_bits:3 ----->| (CMS promoted object)���Կ�������������ͨ��������ǿ�ƫ�õĶ������ 7 �� bit �ĸ�ʽ�ǹ̶��ģ���������ģʽ�£����Dz�ȷ���ģ����������Ҫͨ���������㽫��� 7 �� bit �������������ΪʲôҪ�� 1 �Ƚ��أ����������ٴο������� OpenJDK wiki �е����Ż�ͼ���ᷢ������ͨ�����ʱ��Ҳ���� biase revoke ʱ unlock ״̬�µ� header ������� bit ���� 001��Ҳ����ʮ���Ƶ� 1����������ͨ����Ч������������ͻ���˶��������״̬��
�ٴλص������ slow_enter ����������ж�Ϊ�����ģ�Ҳ����û�������Ļ�����ִ�У�
1 2 3 4 5 6 7 8 9 10 11 if (mark->is_neutral()) { // Anticipate successful CAS -- the ST of the displaced mark must // be visible <= the ST performed by the CAS. lock->set_displaced_header(mark); if (mark == obj()->cas_set_mark((markOop) lock, mark)) { TEVENT(slow_enter: release stacklock); return; } // Fall through to inflate() ... }���Ƚ���ǰ�� mark word���洢�� lock ָ��ָ��Ķ����У������ lock ָ��ָ��ľ��������ᵽ�� lock record��Ȼ�����һ���dz���Ҫ�IJ���������ͨ��ԭ�� cas ��������� lock ָ�밲װ������ mark word �У������װ�ɹ��ͱ�ʾ��ǰ�̻߳�������������������ֱ�ӷ���ִ��ͬ��������ˣ�����ͻ� fall back ���������У�����ע��˵��������
�������ж϶����Ƿ�Ϊ����������������߳̽����ķ��ֵ�ǰ�Ķ������Ѿ�������һ���߳������ˡ����ʱ��ͻ�ִ�е� else ���У�
1 2 3 4 5 6 7 8 if (mark->has_locker() && THREAD->is_lock_owned((address)mark->locker())) { assert(lock != mark->locker(), "must not re-lock the same lock"); assert(lock != (BasicLock*)obj->mark(), "don't relock with same BasicLock"); lock->set_displaced_header(NULL); return; }������ֵ�ǰ�����Ѿ���������Ҫ�ж����Dz��ǵ�ǰ�߳��Լ������ˣ���Ϊ�� synchronized �п�����һ�� synchronized����������¾�ֱ�ӷ��ؼ��ɡ�
�������������ж϶�ʧ���ˣ�Ҳ���Ƕ������������������̲߳��ǵ�ǰ�̣߳����ʱ����Ҫִ������ OpenJDK wiki �е� inflate ����������ν���ͣ����Ǹ��ݵ�ǰ����������һ�� ObjectMonitor ������������б����� sychronized �������������Լ�ʵ���˲�ͬ�Ķ��е��Ȳ��ԣ����������ص㿴�� ObjectMonitor �е� enter ����inflate ������ʮ�ָ��ӣ����Ǵ������ϴ���Ҫ�����ж�һ�� obj ��״̬�ͼ�飬����Ͳ��ٷ����ˣ���
�� enter �����У��кܶ��жϺ��Ż�ִ�е��������Ǻ��ĺ�ͨ��?EnterI?����ʵ�ʽ�����н���ǰ�߳�������
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 void ObjectMonitor::EnterI(TRAPS) { ... // Try the lock - TATAS if (TryLock (Self) > 0) { assert(_succ != Self, "invariant"); assert(_owner == Self, "invariant"); assert(_Responsible != Self, "invariant"); return; } ... // We try one round of spinning *before* enqueueing Self. // // If the _owner is ready but OFFPROC we could use a YieldTo() // operation to donate the remainder of this thread's quantum // to the owner. This has subtle but beneficial affinity // effects. ? if (TrySpin (Self) > 0) { assert(_owner == Self, "invariant"); assert(_succ != Self, "invariant"); assert(_Responsible != Self, "invariant"); return; } ... ObjectWaiter node(Self); // Push "Self" onto the front of the _cxq. // Once on cxq/EntryList, Self stays on-queue until it acquires the lock. // Note that spinning tends to reduce the rate at which threads // enqueue and dequeue on EntryList|cxq. ObjectWaiter * nxt; for (;;) { node._next = nxt = _cxq; if (Atomic::cmpxchg(&node, &_cxq, nxt) == nxt) break; ? // Interference - the CAS failed because _cxq changed. Just retry. // As an optional optimization we retry the lock. if (TryLock (Self) > 0) { assert(_succ != Self, "invariant"); assert(_owner == Self, "invariant"); assert(_Responsible != Self, "invariant"); return; } } ... for (;;) { if (TryLock(Self) > 0) break; ... if ((SyncFlags & 2) && _Responsible == NULL) { Atomic::replace_if_null(Self, &_Responsible); } // park self if (_Responsible == Self || (SyncFlags & 1)) { TEVENT(Inflated enter - park TIMED); Self->_ParkEvent->park((jlong) recheckInterval); // Increase the recheckInterval, but clamp the value. recheckInterval *= 8; if (recheckInterval > MAX_RECHECK_INTERVAL) { recheckInterval = MAX_RECHECK_INTERVAL; } } else { TEVENT(Inflated enter - park UNTIMED); Self->_ParkEvent->park(); } ? if (TryLock(Self) > 0) break; ... } ... if (_Responsible == Self) { _Responsible = NULL; } // �ƺ��������罫��ǰ�̴߳ӵȴ����� CXQ ���Ƴ� ... }��������Ƚϸ��ӣ�����ܳ������潫�ص�������г����ˡ��������������ִ���� TryLock��
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 int ObjectMonitor::TryLock(Thread * Self) { void * own = _owner; if (own != NULL) return 0; if (Atomic::replace_if_null(Self, &_owner)) { // Either guarantee _recursions == 0 or set _recursions = 0. assert(_recursions == 0, "invariant"); assert(_owner == Self, "invariant"); return 1; } // The lock had been free momentarily, but we lost the race to the lock. // Interference -- the CAS failed. // We can either return -1 or retry. // Retry doesn't make as much sense because the lock was just acquired. return -1; }��������ܼ���Ҫ�dz���ͨ�� cas ������ _owner �ֶ�����Ϊ Self������ _owner ��ʾ��ǰ ObjectMonitor ���������е��߳�ָ�룬Self ָ��ǰִ�е��̡߳�����������ˣ���ʾ��ǰ�̻߳������������û�л�á�
�ٻص������ EnterI �����У����ǿ��� TryLock ǰ������ִ�������Σ����Ҵ����ж���һ����ΪʲôҪ����������ʵ��Ϊ������������߳�֮ǰ������飬��ֹ�߳���ν�ؽ���״̬�л�������Ϊʲôִ�����Σ���ʵ�ڶ���ִ�е�ע���Ѿ�˵���ˣ���ô����һЩ�������Ӱ�죿ʲô�����������Ǻܶ����ϵͳ�ж��е�һ�� CPU ִ�е�������˵���ǣ�����ڹ�ȥһ��ʱ���ڣ�ij���̳߳��Ի�ȡij����Դһֱʧ�ܣ���ôϵͳ�ں���������ڽ�����Դ���������̡߳���������ǰ������ִ�У����Ǹ���ϵͳ��ǰ�̡߳����С���Ҫ������ cas ��Դ����������õĻ����������������Ȼ������������һ�ֵõ���֤��Э�飬������ֲ���ֻ����һ�ֻ����ġ������������IJ�����
���������������Ρ���� try lock ֮����Ȼʧ�ܣ���ô��ֻ�ܹԹ���������ˡ������֮ǰ��Ҫ����һ�� ObjectWaiter �����������ǰ�̵߳Ķ���ע���� JavaThread ���������������ǿ��� ObjectWaiter �Ķ��壺
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 class ObjectWaiter : public StackObj { public: enum TStates { TS_UNDEF, TS_READY, TS_RUN, TS_WAIT, TS_ENTER, TS_CXQ }; enum Sorted { PREPEND, APPEND, SORTED }; ObjectWaiter * volatile _next; ObjectWaiter * volatile _prev; Thread* _thread; jlong _notifier_tid; ParkEvent * _event; volatile int _notified; volatile TStates TState; Sorted _Sorted; // List placement disposition bool _active; // Contention monitoring is enabled public: ObjectWaiter(Thread* thread); ? void wait_reenter_begin(ObjectMonitor *mon); void wait_reenter_end(ObjectMonitor *mon); };����㿴�� _next �� _prev ��ͻ��������ף�������Ҫʹ��˫�����ʵ�ֵȴ����еĽ��ࣨ����ʵ���ϣ�������Ӳ�����û���γ�˫�������������γ�˫������ʱ�� exit ��ʱ��������� exit ��ʱ��ῴ�����������node �ڵ㴴�����֮���ִ��������Ӳ�����Ϊ�˷������Ķ����Ұ����������� copy �����ˣ���
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 // Push "Self" onto the front of the _cxq. // Once on cxq/EntryList, Self stays on-queue until it acquires the lock. // Note that spinning tends to reduce the rate at which threads // enqueue and dequeue on EntryList|cxq. ObjectWaiter * nxt; for (;;) { node._next = nxt = _cxq; if (Atomic::cmpxchg(&node, &_cxq, nxt) == nxt) break; ? // Interference - the CAS failed because _cxq changed. Just retry. // As an optional optimization we retry the lock. if (TryLock (Self) > 0) { assert(_succ != Self, "invariant"); assert(_owner == Self, "invariant"); assert(_Responsible != Self, "invariant"); return; } }����ע����˵��������������Ҫ����ǰ�ڵ�ŵ� CXQ ���е�ͷ�������ڵ�� next ָ��ͨ�� cas ����ָ�� _cxq ָ����������Ӳ����������ӳɹ������˳���ǰѭ���������ٴγ��� lock����Ϊ�������ʱ���ɹ�������ʹ��ѭ������ cas ���������Ǵ����ڸ߲�����״̬�� cas ����ʧ�����⣬��һ��� JUC �е� atomic ��ĺܶ� update ������һ�µġ�
��������ѭ���˳��ˣ��ͱ�ʾ��ǰ�̵߳� node �ڵ��Ѿ�˳������ CXQ �����ˣ���ô��������Ҫ��������һ��ѭ����
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 for (;;) { if (TryLock(Self) > 0) break; ... if ((SyncFlags & 2) && _Responsible == NULL) { Atomic::replace_if_null(Self, &_Responsible); } // park self if (_Responsible == Self || (SyncFlags & 1)) { TEVENT(Inflated enter - park TIMED); Self->_ParkEvent->park((jlong) recheckInterval); // Increase the recheckInterval, but clamp the value. recheckInterval *= 8; if (recheckInterval > MAX_RECHECK_INTERVAL) { recheckInterval = MAX_RECHECK_INTERVAL; } } else { TEVENT(Inflated enter - park UNTIMED); Self->_ParkEvent->park(); } ? if (TryLock(Self) > 0) break; ... }���ѭ���е����Ƚϼ�һ�۾��ܿ����ס���Ҫִ�������£�
�ص����ڵ� 2 ��������֪�� synchronzed �����ȡ������ʧ�ܵĻ����ᵼ�µ�ǰ�̱߳���������ô�����������������������ɵġ�������Ҫע����ǣ�������Ҫ�ж�һ�� _Responsible ָ�룬������ָ��Ϊ NULL����ʾ֮ǰ��������û�еȴ��̣߳�Ҳ����˵��ǰ�߳��ǵ�һ���ȴ��̣߳����ʱ��ͨ�� cas ������ _Responsible ָ�� Self����ʾ��ǰ�߳�������������ĵȴ��̡߳���������������ֵ�ǰ�߳̾��ǵȴ��̻߳��߲��ǵȴ��̣߳���ôִ�еĵ����Dz�һ���ġ�����ǵ�ǰ�߳��ǵȴ��̣߳���ô��ִ��һ���ġ��˱��㷨��������һ����ʱ��������ȴ�������㷨�ܼ���һ�εȴ� 1 ms���ڶ��εȴ� 8 ms�������εȴ� 64 ms���Դ����ƣ�ֱ���ﵽ�ȴ�ʱ����������MAX_RECHECK_INTERVAL����� MAX_RECHECK_INTERVAL ��ֵĬ���� 1000 ms��Ҳ����˵�� synchronize ��һ���������ϵ��̣߳�������ǵ�һ���ȴ��̵߳Ļ�����ô���ͣ�����ߡ�����������ߵ�ʱ���ɸղŵ��˱��㷨ָ���������ǰ�̲߳��ǵ�һ���ȴ��̣߳���ôֻ��ִ�������ڵ����ߣ�һֱ�ȴ��������� exit ����ִ�л��Ѳ��У���һ����������� exit ������ʱ���˵����
������һ�����⣬���� park ��������ôʵ���̵߳������ģ����ǿ��� park ��ʵ�֣�?
һ��������ʵ�֣������ֿ��Կ�����ʵ�ֵķ�ʽ��ͨ������£����ǹ����� linux �ϵ� posix ʵ�ַ�ʽ��
1 2 3 4 5 6 7 8 9 void os::PlatformEvent::park() { ... int status = pthread_mutex_lock(_mutex); ... status = pthread_cond_wait(_cond, _mutex); ... status = pthread_mutex_unlock(_mutex); }���������һ���Ӿ����������ʵ�ַ�������ʵ����ͨ�� pthread �� condition wait ���������� pthread �̵߳ĵȴ���
���̻߳���������Խ���ʱ��Ҳ���������ѭ���˳�����ʱ�����ʱ����Ҫִ��һ����Ҫ�IJ��������ǽ� _Responsible ��Ϊ NULL��
1 2 3 4 if (_Responsible == Self) { _Responsible = NULL; }�������������¸��̻߳��ѵ�ʱ���� _Responsible Ϊ NULL �ͻ᳢������� cas ��ʽ���Լ���עΪ��һ���ȴ��̣߳������Ϳ����ظ�����IJ�������� monitor ���Ľ��ӡ�
�������������� ObjectMonitor enter ����������֪�������¼������飺
��һ���̻߳�ö������ɹ�֮�Ϳ���ִ���Զ�����ͬ��������ˡ�ִ�����֮���ִ�е� ObjectMonitor �� exit �����У��ͷŵ�ǰ��������������һ���߳�����ȡ��������������������� exit ��ʵ�ֹ�����
exit ������ʵ�ֱȽϳ������������ϵĽṹ�Ƚ�������
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 void ObjectMonitor::exit(bool not_suspended, TRAPS) { for (;;) { ... ObjectWaiter * w = NULL; int QMode = Knob_QMode; ? if (QMode == 2 && _cxq != NULL) { ... } ? if (QMode == 3 && _cxq != NULL) { ... } ? if (QMode == 4 && _cxq != NULL) { ... } ... ExitEpilog(Self, w); return; } }����� exit ���������Ϸ�Ϊ���¼������֣�
�������Ƿ������ַ��� exit ����
�� exit �����������Ǹ��� Knob_QMode ֵ�IJ�ִͬ�в�ͬ�����������ǿ������ֵ��Ĭ��ֵ��
1 2 3 // EntryList-cxq policy - queue discipline static int Knob_QMode = 0;���ֵĬ���� 0���������ֵ������ʾʲô�����أ������ֵ��ע���п��Կ��������ֵ������ָ�����˳�ʱ�� EntryList �� CXQ ���г��Ӳ��Եģ�CXQ ����֪���� enter ��ʱ����Ϊ���Ѿ�������߳����������������̣߳����� EntryList ��ʲô�أ�������˽� Java Object �� wait �� notify����ͻ�֪������ notify ���� wait �߳���ִ��ʱ���������̼߳���Ķ��о��� EntryList������û��ϵ���������ǻᵥ����ϸ���� Object �� wait �� notify ��ʵ�֡���ô�ص����ǵ����⣬Knob_QMode ���������Ҫ����ָ���� exit ��ʱ�� EntryList �� CXQ ����֮��Ļ��ѹ�ϵ��Ҳ����˵���� EntryList �� CXQ �ж��еȴ����߳�ʱ����Ϊ exit ֮��ֻ����һ���̵߳õ��������ʱ��ѡ�����ĸ������е��߳���һ��ֵ�ÿ��ǵ����顣���������кܶ��в��Կ���ִ�У������Ĭ�ϲ��Ծ��� 0���������Ƿֱ����һ�²�ͬ�����µIJ�ͬ��Ϊ��
�������ǿ��� JVM Ĭ�ϵIJ��ԣ�Ҳ���Dz��� 0����Ҳ�Ǵ������ JVM ����Ϊ���֡���ʵ�ʷ��� JVM ��ʵ��֮ǰ�������ȿ���һ�� java ���룺
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 Thread t3 = new Thread(new Runnable() { ? public void run() { System.out.println("Thread 3 start!!!!!!"); synchronized (lock) { try { System.in.read(); } catch (Exception e) { } System.out.println("Thread 3 end!!!!!!"); } } }); ? Thread t4 = new Thread(new Runnable() { ? public void run() { System.out.println("Thread 4 start!!!!!!"); synchronized (lock) { System.out.println("Thread 4 end!!!!!!"); } } }); ? Thread t5 = new Thread(new Runnable() { ? public void run() { int a = 0; System.out.println("Thread 5 start!!!!!!"); synchronized (lock) { a++; System.out.println("Thread 5 end!!!!!!"); } } }); ? Thread t6 = new Thread(new Runnable() { ? public void run() { int a = 0; System.out.println("Thread 6 start!!!!!!"); synchronized (lock) { a++; System.out.println("Thread 6 end!!!!!!"); } } }); ? t3.start(); try { TimeUnit.SECONDS.sleep(1); } catch (Exception e) { ? } t4.start(); try { TimeUnit.SECONDS.sleep(1); } catch (Exception e) { ? } t5.start(); try { TimeUnit.SECONDS.sleep(1); } catch (Exception e) { ? } t6.start();����Ĵ���ܼ�t3 �߳�����������������ռ lock ����Ȼ����ͬ�����е��� system.in �� read ��������������Ӽ��̻�ȡһ�����룬��û�еõ�����֮ǰ��һֱ�ȴ���ע���ʱû�з��� monitor ������һ��� wait ��ͬ�����Ұ��¼��̻س���ʱ�ỽ�� t3 �̲߳�����ִ���ͷ� lock ����t3 ����֮��t4��t5��t6�����������ô���Ұ��¼��̻�����������ݣ�
1 2 3 4 5 6 7 8 9 10 Thread 3 start!!!!!! Thread 4 start!!!!!! Thread 5 start!!!!!! Thread 6 start!!!!!! ? Thread 3 end!!!!!! Thread 6 end!!!!!! Thread 5 end!!!!!! Thread 4 end!!!!!!��������ϸ������˽� synchronized �Ļ��ƶ�����İ���������������������߳����Ȼ�� lock��������һ�֡������߾��ϡ���Ч��������ʵ��Ϊʲô�������أ��������Ǵ� JVM �ײ������Ѱ�Ҵ𰸡�����ǰ���ڷ��� enter ������ʱ��˵���ˣ������ǰ������������һ���߳��������ˣ���ô����Ҫ����ǰ�̰߳�װ�� ObjectWaiter �����У�Ȼ����뵽 CXQ ���е�ͷ����ϣ����û���ε������ǵ���Щ���ݡ���������Ĵ����У����Ұ��»س���֮ǰ�� CXQ �������£�
�� t6 �߳�����֮����� cxq ���У���ʱ cxq ���л�ָ�� t6 �� wait �ڵ㣬���ڴ�Ҽ�ס����ͼ���������ǿ�ʼ���� exit �����Ĭ��״̬�£�Ҳ���� mode ���� 0 ��ʱ�������
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 void ObjectMonitor::exit(bool not_suspended, TRAPS) { for (;;) { ... ObjectWaiter * w = NULL; int QMode = Knob_QMode; ... w = _cxq; ... _EntryList = w; ObjectWaiter * q = NULL; ObjectWaiter * p; for (p = w; p != NULL; p = p->_next) { guarantee(p->TState == ObjectWaiter::TS_CXQ, "Invariant"); p->TState = ObjectWaiter::TS_ENTER; p->_prev = q; q = p; } ... w = _EntryList; if (w != NULL) { guarantee(w->TState == ObjectWaiter::TS_ENTER, "invariant"); ExitEpilog(Self, w); return; } } }��Ϊ����ֻ��ע mode == 0 ���������� exit ��������Ϊ�ͱ�÷dz������Ƚ� cxq ָ�븳ֵ�� _EntryList��Ȼ��ͨ��һ��ѭ����ԭ������������ cxq �������˫����������ô����Ŀ�ľ���Ϊ�˷��������� cxq �������в�ѯ�����ǵ�ǰ�����Ƿ��� enter ��ʱ��˵������Ȼ ObjectWaiter ʱһ��˫�������Ľڵ㣬���������� enter ��ʱ��û���γ�˫����������ʱ�����ᵽ��˵˫���������γɻ��� exit ʱ�γɣ���ʵ˵�ľ������
������������������֮�Ὣ _EntryList �У�ע�� _EntryList ��ʵ���� cxq����Ϊǰ�渳ֵ�ˣ���ͷ�Ľڵ㴫�ݸ� ExitEpilog ������
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 void ObjectMonitor::ExitEpilog(Thread * Self, ObjectWaiter * Wakee) { assert(_owner == Self, "invariant"); ? // Exit protocol: // 1. ST _succ = wakee // 2. membar #loadstore|#storestore; // 2. ST _owner = NULL // 3. unpark(wakee) ? _succ = Knob_SuccEnabled ? Wakee->_thread : NULL; ParkEvent * Trigger = Wakee->_event; ? // Hygiene -- once we've set _owner = NULL we can't safely dereference Wakee again. // The thread associated with Wakee may have grabbed the lock and "Wakee" may be // out-of-scope (non-extant). Wakee = NULL; ? // Drop the lock OrderAccess::release_store(&_owner, (void*)NULL); OrderAccess::fence(); // ST _owner vs LD in unpark() ? if (SafepointMechanism::poll(Self)) { TEVENT(unpark before SAFEPOINT); } ? DTRACE_MONITOR_PROBE(contended__exit, this, object(), Self); Trigger->unpark(); ? // Maintain stats and report events to JVMTI OM_PERFDATA_OP(Parks, inc()); }�����ʵ�ַdz�����ʵ����ͨ�� park event ���ȴ����Ǹ��̻߳��ѣ�ͨ��ִ�� unpark ������ǰ�����֮������߲����� park����ͬ����������кܶ�ƽ̨��ʵ�֣�
������Ȼ�ǹ��� posix ƽ̨�ϵ�ʵ�֣�
1 2 3 4 5 6 7 8 9 10 11 12 13 void os::PlatformEvent::unpark() { if (Atomic::xchg(1, &_event) >= 0) return; ? int status = pthread_mutex_lock(_mutex); int anyWaiters = _nParked; status = pthread_mutex_unlock(_mutex); ? if (anyWaiters != 0) { status = pthread_cond_signal(_cond); assert_status(status == 0, status, "cond_signal"); } }������Ȼ��ͨ�� pthread �� condition signal �����̣߳�ǰ���߳�������ͨ�� condition wait ʵ�ֵġ�
���Ǽ����ص� exit �������������ڿ��Խ������� JVM ƽ̨Ĭ��ִ�С������߾��ϡ������ˣ�����ԭ������� enter ��ʱ����� cxq �����ǽ��߳̽ڵ���뵽��ͷ���������Ǻ����ִӶ�ͷ��ȡ�ڵ㻽�ѣ�������ǻ��Ѻ���ӽ����Ľڵ��̡߳�
�������ǿ��£�������ǽ� Knob_QMode ��Ĭ��ֵ��Ϊ 1��Ȼ�����±��� JVM���ٴ����л�������½����
1 2 3 4 5 6 7 8 9 10 Thread 3 start!!!!!! Thread 4 start!!!!!! Thread 5 start!!!!!! Thread 6 start!!!!!! ? Thread 3 end!!!!!! Thread 4 end!!!!!! Thread 5 end!!!!!! Thread 6 end!!!!!!Wow�����ڽ����ˡ������߾��ϡ���ģʽ�ˣ�����ģʽ�¿������������ִ�У�������Ϊ���� FIFO ���������Ĭ�ϵ���ʽ��ʵ�� LIFO ջʵ�֡�
��ô mode == 1�� mode == 0 �IJ�����������С�����������£�
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 if (QMode == 1) { // QMode == 1 : drain cxq to EntryList, reversing order // We also reverse the order of the list. ObjectWaiter * s = NULL; ObjectWaiter * t = w; ObjectWaiter * u = NULL; while (t != NULL) { guarantee(t->TState == ObjectWaiter::TS_CXQ, "invariant"); t->TState = ObjectWaiter::TS_ENTER; u = t->_next; t->_prev = u; t->_next = s; s = t; t = u; } _EntryList = s; assert(s != NULL, "invariant"); } else { // QMode == 0 or QMode == 2 _EntryList = w; ObjectWaiter * q = NULL; ObjectWaiter * p; for (p = w; p != NULL; p = p->_next) { guarantee(p->TState == ObjectWaiter::TS_CXQ, "Invariant"); p->TState = ObjectWaiter::TS_ENTER; p->_prev = q; q = p; } }���Կ����������Ƿ���Ĭ����Ϊ�� else ��֧�еģ���� mode == 1 �Ļ�����������ķ�֧������ע����˵�ģ������ͨ��һ��ѭ���� cxq ���� reverse һ�£�Ȼ���µĶ�ͷҲ����ԭ���Ķ�β��ֵ�� _EntryList���������Ļ��ѻ���ͨ�� ExitEpilog ����ʵ�֡�
�������Ƿ�����Ĭ���µ� mode == 0 �� mode ==1 ����Ϊ���� JVM �л�֧�� 2��3��4��������ģʽ���������Ƿֱ��¡�mode == 2 ���� cxq ���в����� NULL �Ļ��������������
1 2 3 4 5 6 7 8 9 10 11 if (QMode == 2 && _cxq != NULL) { // QMode == 2 : cxq has precedence over EntryList. // Try to directly wake a successor from the cxq. // If successful, the successor will need to unlink itself from cxq. w = _cxq; assert(w != NULL, "invariant"); assert(w->TState == ObjectWaiter::TS_CXQ, "Invariant"); ExitEpilog(Self, w); return; }���ォ w ָ��ָ���� cxq ��ͷ��Ȼ��ֱ��ִ�н���ͷ���ѵ�������Ҳ����˵����� mode == 2 �Ļ���cxq �����ȼ��DZ� EntryList �ߵġ���� cxq == NULL����ô��ִ�к��������Ҳ�����ȿ� EntryList ���Ƿ�Ϊ�գ���� EntryList ��Ϊ�գ��ͻ��� EntryList �е��̣߳�������� exit �е��Ǹ���ѭ������ÿһ��ѭ���Ŀ�ͷ���ж�һ�� EntryList �� cxq �����Ƿ�ͬʱΪ�գ�����ǵĻ�������Ϊ���ʱû���߳�ͬ����������ϣ�����Ҳû�� notify �����ѵ��̣߳���˾�ֱ���˳��� exit ���������� wait �� notify �����������ǻ������������ֻҪ֪����notify ��ʱ��Ὣ wait ���̷߳ŵ� EntryList �����С�
�������ǿ��Կ�������� mode == 2������ cxq ��Ϊ�յĻ�����ô���� cxq ����ִ�е�����ʵ�� mode == 2 ��һ���ġ�Ψһ������ǣ��� EntryList ���б� notify ���ѵ��߳�ʱ��mode == 0 ������ִ�� EntryList �е��̻߳��ѣ��� mode == 2 ������ִ�� cxq �У��ȵ� cxq �е��߳�ȫ�����ѵ�֮��Żỽ�� EntryList �е��̣߳�ֻ��һ������IJ����������ͨ�����´�����֤���ǵĽ��ۣ�
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 Thread t0 = new Thread(new Runnable() { ? public void run() { System.out.println("Thread 0 start!!!!!!"); synchronized (lock) { try { lock.wait(); } catch (Exception e) { } System.out.println("Thread 0 end!!!!!!"); } } }); Thread t3 = new Thread(new Runnable() { ? public void run() { System.out.println("Thread 3 start!!!!!!"); synchronized (lock) { try { System.in.read(); } catch (Exception e) { } lock.notify(); System.out.println("Thread 3 end!!!!!!"); } } }); ? Thread t4 = new Thread(new Runnable() { ? public void run() { System.out.println("Thread 4 start!!!!!!"); synchronized (lock) { System.out.println("Thread 4 end!!!!!!"); } } }); ? Thread t5 = new Thread(new Runnable() { ? public void run() { int a = 0; System.out.println("Thread 5 start!!!!!!"); synchronized (lock) { a++; System.out.println("Thread 5 end!!!!!!"); } } }); ? Thread t6 = new Thread(new Runnable() { ? public void run() { int a = 0; System.out.println("Thread 6 start!!!!!!"); synchronized (lock) { a++; System.out.println("Thread 6 end!!!!!!"); } } }); ? t0.start(); try { TimeUnit.SECONDS.sleep(1); } catch (Exception e) { ? } t3.start(); try { TimeUnit.SECONDS.sleep(1); } catch (Exception e) { ? } t4.start(); try { TimeUnit.SECONDS.sleep(1); } catch (Exception e) { ? } t5.start(); try { TimeUnit.SECONDS.sleep(1); } catch (Exception e) { ? } t6.start();��δ���ִ��֮�����Ұ��»س�֮����û�� exit �� monitor ʱ�� EntryList ���к� cxq ����״̬���£�
�� mode == 0 Ҳ����Ĭ��״̬�£�ִ�н�����£�
1 2 3 4 5 6 7 8 9 10 11 12 Thread 0 start!!!!!! Thread 3 start!!!!!! Thread 4 start!!!!!! Thread 5 start!!!!!! Thread 6 start!!!!!! ? Thread 3 end!!!!!! Thread 0 end!!!!!! Thread 6 end!!!!!! Thread 5 end!!!!!! Thread 4 end!!!!!!�� mode == 2 ��ʱ��ִ�н�����£�
1 2 3 4 5 6 7 8 9 10 11 12 Thread 0 start!!!!!! Thread 3 start!!!!!! Thread 4 start!!!!!! Thread 5 start!!!!!! Thread 6 start!!!!!! ? Thread 3 end!!!!!! Thread 6 end!!!!!! Thread 5 end!!!!!! Thread 4 end!!!!!! Thread 0 end!!!!!!���Ǵ� t0 �Ļ���ʱ��ִ����ϵ�ʱ���Ϳ�����֤��������Ľ����ˡ�
���� 3 �Ͳ��� 4 �����Ƚ����ƣ�
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 if (QMode == 3 && _cxq != NULL) { // Aggressively drain cxq into EntryList at the first opportunity. // This policy ensure that recently-run threads live at the head of EntryList. // Drain _cxq into EntryList - bulk transfer. // First, detach _cxq. // The following loop is tantamount to: w = swap(&cxq, NULL) w = _cxq; for (;;) { assert(w != NULL, "Invariant"); ObjectWaiter * u = Atomic::cmpxchg((ObjectWaiter*)NULL, &_cxq, w); if (u == w) break; w = u; } assert(w != NULL, "invariant"); ? ObjectWaiter * q = NULL; ObjectWaiter * p; for (p = w; p != NULL; p = p->_next) { guarantee(p->TState == ObjectWaiter::TS_CXQ, "Invariant"); p->TState = ObjectWaiter::TS_ENTER; p->_prev = q; q = p; } ? // Append the RATs to the EntryList // TODO: organize EntryList as a CDLL so we can locate the tail in constant-time. ObjectWaiter * Tail; for (Tail = _EntryList; Tail != NULL && Tail->_next != NULL; Tail = Tail->_next) /* empty */; if (Tail == NULL) { _EntryList = w; } else { Tail->_next = w; w->_prev = Tail; } ? // Fall thru into code that tries to wake a successor from EntryList } ? if (QMode == 4 && _cxq != NULL) { // Aggressively drain cxq into EntryList at the first opportunity. // This policy ensure that recently-run threads live at the head of EntryList. ? // Drain _cxq into EntryList - bulk transfer. // First, detach _cxq. // The following loop is tantamount to: w = swap(&cxq, NULL) w = _cxq; for (;;) { assert(w != NULL, "Invariant"); ObjectWaiter * u = Atomic::cmpxchg((ObjectWaiter*)NULL, &_cxq, w); if (u == w) break; w = u; } assert(w != NULL, "invariant"); ? ObjectWaiter * q = NULL; ObjectWaiter * p; for (p = w; p != NULL; p = p->_next) { guarantee(p->TState == ObjectWaiter::TS_CXQ, "Invariant"); p->TState = ObjectWaiter::TS_ENTER; p->_prev = q; q = p; } ? // Prepend the RATs to the EntryList if (_EntryList != NULL) { q->_next = _EntryList; _EntryList->_prev = q; } _EntryList = w; ? // Fall thru into code that tries to wake a successor from EntryList }�������������Ե�ע���п��Կ��������������Ե���ҪĿ���ǽ� EntryList �� cxq ���н���һ�����Ӳ�������Ȼ���������е����ӣ��ͻ��漰��˭���ӵ�˭ǰ������⡣������������� 2 ��������˵������ҵĵ�ǰ EntryList �� cxq ����״̬���£�
��ô���� 3 ������֮��������������
�������� 4 ������֮���������������
�����ԣ����� 3 �ǽ� cxq ���� EntryList ֮������ 3 �Ƿ��� EntryList ֮ǰ��
�������ǻ����Բ��� 2 �д���ֱ���ԣ���֤���ǵĽ��ۡ�
�ڲ��� 3 �µ����н����
1 2 3 4 5 6 7 8 9 10 11 12 Thread 0 start!!!!!! Thread 3 start!!!!!! Thread 4 start!!!!!! Thread 5 start!!!!!! Thread 6 start!!!!!! ? Thread 3 end!!!!!! Thread 0 end!!!!!! Thread 6 end!!!!!! Thread 5 end!!!!!! Thread 4 end!!!!!!�ڲ��� 4 �µ����н����
1 2 3 4 5 6 7 8 9 10 11 12 Thread 0 start!!!!!! Thread 3 start!!!!!! Thread 4 start!!!!!! Thread 5 start!!!!!! Thread 6 start!!!!!! ? Thread 3 end!!!!!! Thread 6 end!!!!!! Thread 5 end!!!!!! Thread 4 end!!!!!! Thread 0 end!!!!!!������н��ֱ�Ӿ���ӡ֤������ķ������߳̽������е�ʱ����������ͼ�еĺϲ�֮���������˳��
���������ȫ���������� exit ��ִ������exit �е��ص���� EntryList �� cxq ���еij��Ӳ��ԡ����������ܽ��£����Ӳ��������Ͽ��Է�Ϊ���飺
����ģʽ��Ӧģʽ 0 ��ģʽ 1��ģʽ 3������ģʽ 0��������ģʽ�������ģʽ 0 �� cxq ���лᱣ�֡������߾��ϡ��Ķ���˳��ģʽ 1 �� reverse ���˳��ģʽ 3 �������κ�˳��ֻ�Ǽؽ� cxq �������� EntryList �ĺ���
����ģʽ��Ӧģʽ 4������ģʽֻ�ǽ� EntryList ���� cxq �ĺ��棬Ȼ�����µ� EntryList ���п�ʼ�����߳�
?
??
Java Object ���ṩ��һ������ native ʵ�ֵ� wait �� notify �̼߳�ͨѶ�ķ�ʽ�����dz��� synchronized ֮�������һ������IJ����������֣��й� wait �� notify �IJ������ݣ�������������� monitor �� exit ��ʱ���Ѿ���һЩ�漰�����Dz�û�й�������룬���������˲��ٵ����ʣ����汾С�ڻ���ϸ����һ���� HotSpot JVM �е� wait �� notify ��ʵ������
������ JDK �е� Object ��Ĵ��룬��ῴ�� wait �� notify/notifyAll ��ʵ��ȫ���Dz��ò��� native ʵ�ֵģ������� Object �Ŀ�ͷ�����´��룺
1 2 3 4 5 private static native void registerNatives(); static { registerNatives(); }�����Dz��Ǻ�ǰ��� Thread �����һ�ޣ���˲��� JVM �еı���ʵ�ֺ���Ҳ��һ�����ֶΡ����������ʡ��������ҵIJ��֣����Ŵ��������Ѿ�֪����ô�� JVM ��������ʵ�ֵĺ����ˡ����һ·���ҵĻ�����ᷢ�� wait �� notify/notifyAll ������ src/hotspot/share/runtime/objectMonitor.cpp ��ʵ�ֵġ�������ǻ��ǻ�������ļ��н��з�����
ObjectMonitor ���е� wait ����ʵ�����£�
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 void ObjectMonitor::wait(jlong millis, bool interruptible, TRAPS) { ... if (interruptible && Thread::is_interrupted(Self, true) && !HAS_PENDING_EXCEPTION) { ... // �׳��쳣������ֱ�ӽ���ȴ� THROW(vmSymbols::java_lang_InterruptedException()); ... } ... ObjectWaiter node(Self); node.TState = ObjectWaiter::TS_WAIT; Self->_ParkEvent->reset(); OrderAccess::fence(); ? Thread::SpinAcquire(&_WaitSetLock, "WaitSet - add"); AddWaiter(&node); Thread::SpinRelease(&_WaitSetLock); ? if ((SyncFlags & 4) == 0) { _Responsible = NULL; } ? ... // exit the monitor exit(true, Self); ... if (interruptible && (Thread::is_interrupted(THREAD, false) || HAS_PENDING_EXCEPTION)) { // Intentionally empty } else if (node._notified == 0) { if (millis <= 0) { Self->_ParkEvent->park(); } else { ret = Self->_ParkEvent->park(millis); } } // �� notify ����֮����ƺ��� ... }wait ������ʵ��Ҳ�Ƚϳ����������ǹ��ĵĺ��Ĺ��ܲ��־��������г��ġ����Ȼ��ж�һ�µ�ǰ�߳��Ƿ�Ϊ���жϲ����Ƿ��Ѿ����жϣ�����ǵĻ���ֱ���׳� InterruptedException �쳣����������� wait �ȴ�������Ļ�������Ҫִ������ĵȴ��Ĺ��̡����Ȼ���� Self ��ǰ�߳��½�һ�� ObjectWaiter ����ڵ㣬�������������ǰ����� monitor �� enter ��ʱ����Ѿ��������ˡ�����һ���µĽڵ�֮�������Ҫ������ڵ�ŵ��ȴ������У�ͨ������ AddWaiter ����ʵ�� node ����Ӳ�������������Ӳ���֮ǰ��Ҫ����������Ա�֤������ȫ��
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 void Thread::SpinAcquire(volatile int * adr, const char * LockName) { if (Atomic::cmpxchg (1, adr, 0) == 0) { return; // normal fast-path return } ? // Slow-path : We've encountered contention -- Spin/Yield/Block strategy. TEVENT(SpinAcquire - ctx); int ctr = 0; int Yields = 0; for (;;) { while (*adr != 0) { ++ctr; if ((ctr & 0xFFF) == 0 || !os::is_MP()) { if (Yields > 5) { os::naked_short_sleep(1); } else { os::naked_yield(); ++Yields; } } else { SpinPause(); } } if (Atomic::cmpxchg(1, adr, 0) == 0) return; } }�Ӻ��������ƾ��ܿ�������һ����������ʵ�֣������ᡸ������ʹ���߳�����ȴ�״̬����ʵ���Ͽ���������ͨ��һ����ѭ������ͨ�� cas ����ж��Ƿ����������↑ʼ��ͨ��һ�� cas ��鿴���Ƿ��ܹ��ɹ�������ɹ��Ļ��Ͳ��ý�������Ƚ��������� spin ���̡������ȡʧ�ܣ�����Ҫ��������� spin ���̣������ spin ����һ���Ƚ�����˼���㷨�����ﶨ����һ�� ctr ��������ʵ���� counter ����������˼��(ctr & 0xFFF) == 0 || !os::is_MP() ��������Ƚ�����˼����˼��˵����ҳ��ԵĴ������� 0xfff�����ߵ�ǰϵͳ��һ�����˴�����ϵͳ����ô��ִ��������������Կ�������� spin ����һ�����ȵġ����ȿ�ʼ��ʱ������Ƕ��ϵͳ����ֱ��ִ�� SpinPause �����ǿ��� SpinPause ������ʵ�֣����������ʵ�� CPU ��æ�ȴ�����˻��в�ͬϵͳ�� CPU �ܹ��Ķ�Ӧʵ�֣�
����������Ȼֻ���� linux ƽ̨�ϵ� 64 bit �ܹ���ʵ�֣�
1 2 3 4 int SpinPause() { return 0; }�ǵģ���û�п����������ʵ�־���û��ʵ�֣�ֻ�Ƿ���һ�� 0 �����£���ʵ�����룬ͨ������һ���������صĿպ�������ʵ���� CPU ��æ�ȴ���ô��ֻ��������ʵ�ַ�ʽ�Ƚϲ�̫���Ű��ˡ�����������?SpinAcquire?������ʵ�֣�������dz��ԵĴ����Ѿ����� 0xFFF �εĻ����Ǿͱ�ʾ������Ҫʹ������һ�ֻ�����ʵ��æ���ˣ���Ϊ���ﳢ�Ի�ȡ������Ԥ���ÿ��Ի�ã���˲����������ڵ�ִ��������ÿպ��������Ƕ���Դ��һ�ּ�����˷ѡ���������� 0xFFF �λ�û�гɹ��Ļ�����ͨ�����·�ʽʵ�ֵȴ���
1 2 3 4 5 6 7 if (Yields > 5) { os::naked_short_sleep(1); } else { os::naked_yield(); ++Yields; }���Ȼ᳢��ͨ�� yield ����������ǰ�̵߳� CPU ִ��ʱ���ó������������ 5 �λ���û�л�������Ǿ�ֻ��ͨ�� naked_short_sleep ��ʵ�ֵȴ��ˣ������ naked_short_sleep ���������־��ܿ������Ƕ������ߵȴ���ͨ��ÿ�����ߵȴ� 1ms ʵ�֡��������ڿ��� naked_yield ��ʵ�ַ�ʽ��ͬ���������Ҳ�кܶ�ϵͳƽ̨��ʵ�֣������Ϲ��ֻ�� linux��
1 2 3 4 void os::naked_yield() { sched_yield(); }���Կ��������ʵ���DZȽϼģ�ֱ��ͨ�� pthread �� sched_yield ����ʵ���̵߳�ʱ��Ƭ�ó��������ڿ��� naked_short_sleep ��ʵ�֣������� linux ƽ̨����
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 void os::naked_short_sleep(jlong ms) { struct timespec req; ? assert(ms < 1000, "Un-interruptable sleep, short time use only"); req.tv_sec = 0; if (ms > 0) { req.tv_nsec = (ms % 1000) * 1000000; } else { req.tv_nsec = 1; } ? nanosleep(&req, NULL); ? return; }��������ͨ�� nanosleep ϵͳ����ʵ���̵߳� timed waiting��
���������Ǵ��·�����?SpinAcquire?������ʵ�֣�����������Ҫ˵�������������Ϊɶ��Ҫ�ж� os::is_MP()�����������ģ�����ǵ��˴�������ͨ�� yield ���� sleep ʵ�ֵȴ�������Ƕ�˴������Ļ���ͨ�����ÿ�ʵ�ֺ�����æ�ȴ���Ϊɶ��Ҫ�����أ���Ϊ����ǵ��� CPU �Ļ�����ͨ�����ÿ�ʵ�ֺ���ʵ��æ�ȴ��Dz���ѧ�ģ���Ϊֻ��һ���ˣ���ȴͨ���������ʵ��æ�ȴ�����ôԭ����Ҫ�ͷ������̵߳ò���ִ�У��ǾͿ�����ɼ����ȴ������ǵ� CPU һֱ��ת��������û�н���κ����⡣��������ǵ��� CPU ϵͳ�Ļ������Dz���ͨ�����ÿպ�����ʵ�ֵȴ����෴������Ƕ�˵Ļ����ǾͿ���������һ�����е� CPU ��ʵ��æ�ȴ�һ����ϵͳ�����������Կ����� jVM ��Ϊ������ϵͳ��ϵͳ�ͱ�֤ϵͳ�ļ����ԣ����˶��ٵ�Ŭ����ʵ�ְ���
����� SpinAcquire ��������֮�ͱ�ʾ���ǻ�����������ڿ��Խ����ǵ� node �ŵ��ȴ��������ˣ�
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 inline void ObjectMonitor::AddWaiter(ObjectWaiter* node) { assert(node != NULL, "should not add NULL node"); assert(node->_prev == NULL, "node already in list"); assert(node->_next == NULL, "node already in list"); // put node at end of queue (circular doubly linked list) if (_WaitSet == NULL) { _WaitSet = node; node->_prev = node; node->_next = node; } else { ObjectWaiter* head = _WaitSet; ObjectWaiter* tail = head->_prev; assert(tail->_next == head, "invariant check"); tail->_next = node; head->_prev = node; node->_next = head; node->_prev = tail; } }�����ʵ����ʵ�dz������ǽ� node ����˫������ _WaitSet ��β���������������֮����Ҫͨ��?SpinRelease?�����ͷš�
���������Ѿ����½��� node �ڵ���뵽 WaitSet �������ˣ����Ǽ����� wait �����������������������Ǿ�Ҫִ���������ݣ�
1 2 3 // exit the monitor exit(true, Self);�ǵģ���϶�֪�� Java Object �� wait �������ͷ� monitor �����ͷŲ�����������ʵ�ֵģ�
�ͷ��� monitor ��֮�����Ǿ���Ҫ����ǰ�߳̽��� park �ȴ��ˣ�
1 2 3 4 5 6 7 8 9 10 if (interruptible && (Thread::is_interrupted(THREAD, false) || HAS_PENDING_EXCEPTION)) { // Intentionally empty } else if (node._notified == 0) { if (millis <= 0) { Self->_ParkEvent->park(); } else { ret = Self->_ParkEvent->park(millis); } }����ʽ park ֮ǰ��������һ�ο����Ƿ��� interrupted������еĻ��ͻ����� park ����������ͻ���� park ��������Ϊ wait �������Դ�ʱ�䣬��ʾ������ʱ�䣬����������Ҫ������ʱ��� park ������ͬ�IJ�����park ��������ǰ���ڷ��� monitor �� enter ��ʱ���Ѿ��������ˣ��������Ͳ������ˡ�
�� wait �������ĺ��������� park ��������֮����ƺ������������ǵķ�������ʮ����Ҫ��������������������������ص����һ�� notify ���ѵ�����
notify ������ʵ�����£�
1 2 3 4 5 6 7 8 9 10 11 void ObjectMonitor::notify(TRAPS) { CHECK_OWNER(); if (_WaitSet == NULL) { TEVENT(Empty-Notify); return; } DTRACE_MONITOR_PROBE(notify, this, object(), THREAD); INotify(THREAD); OM_PERFDATA_OP(Notifications, inc(1)); }���Կ��������Ȼ��� WaitSet ���У��������Ϊ�յĻ�����ʾû���߳�ִ���� wait��Ҳ��û�б�Ҫִ�н������IJ����ˣ�ֱ�ӷ��ؼ��ɡ�
��� WaitSet ���в�Ϊ�գ���ʾ���߳������ monitor �� wait �ˣ���˾���Ҫ����ij���̣߳�������ͨ������ INotify ����ʵ�֣�
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 void ObjectMonitor::INotify(Thread * Self) { const int policy = Knob_MoveNotifyee; ? Thread::SpinAcquire(&_WaitSetLock, "WaitSet - notify"); ObjectWaiter * iterator = DequeueWaiter(); if (iterator != NULL) { ObjectWaiter * list = _EntryList; if (policy == 0) { // prepend to EntryList if (list == NULL) { ... } else { ... } } else if (policy == 1) { // append to EntryList if (list == NULL) { ... } else { ... } } else if (policy == 2) { // prepend to cxq if (list == NULL) { ... } else { ... } } else if (policy == 3) { // append to cxq ... } else { ... } ... } Thread::SpinRelease(&_WaitSetLock); }�����Ȳ�������������ϸ�ڣ���������һ�� INotify �����Ŀ�ܡ����Կ�������IJ��������� _WaitSetLock �����µģ����Ȼ�� WaitSet �����г���һ���ڵ㣬Ȼ���������ڵ���� Knob_MoveNotifyee ������ִ�в�ͬ�����������Ҳ����е�����ܾ���һ���ģ����� _EntryList �Ƿ�Ϊ��ִ�в�ͬ���������� 3 ���⣬����ᵥ����������
��ô��Knob_MoveNotifyee ��ʲô�أ���ʵ�Ӷ���ĵط����Կ�����
1 2 3 // notify() - disposition of notifyee static int Knob_MoveNotifyee = 2;��ע���п��Կ������������ notify ���ѵIJ��Զ��塣������� INotify ������ע���п��Կ����ܹ������¼���ģʽ��
�ڷ�����ͬ���Ե���֮ǰ�������ȿ��� WaitSet �ij�������ʵ�֣����� INotify ������ʼ��ִ�е����飺
1 2 3 4 5 6 7 8 9 inline ObjectWaiter* ObjectMonitor::DequeueWaiter() { // dequeue the very first waiter ObjectWaiter* waiter = _WaitSet; if (waiter) { DequeueSpecificWaiter(waiter); } return waiter; }��ע���п��Կ��������ォ WaitSet �����еĵ�һ�� node ���ӣ�����ֱ�ӷ��� WaitSet ���е�ָ��Ҳ���Ƕ�ͷ��Ȼ��ɾ�����ӽڵ㣺
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 inline void ObjectMonitor::DequeueSpecificWaiter(ObjectWaiter* node) { assert(node != NULL, "should not dequeue NULL node"); assert(node->_prev != NULL, "node already removed from list"); assert(node->_next != NULL, "node already removed from list"); // when the waiter has woken up because of interrupt, // timeout or other spurious wake-up, dequeue the // waiter from waiting list ObjectWaiter* next = node->_next; if (next == node) { assert(node->_prev == node, "invariant check"); _WaitSet = NULL; } else { ObjectWaiter* prev = node->_prev; assert(prev->_next == node, "invariant check"); assert(next->_prev == node, "invariant check"); next->_prev = prev; prev->_next = next; if (_WaitSet == node) { _WaitSet = next; } } node->_next = NULL; node->_prev = NULL; }�������Ǿ�����˴� WaitSet ˫�����������еĶ�ͷ��������
��������Լ�����?INotify?������ʵ�֣���ᷢ������ȫ�Ƕ��еIJ�������û�л����̡߳��ǵģ������̲߳����������ֻ�ǽ���Ҫ���ѵ��̷߳ŵ� EntryList �����У�Ȼ���� exit �����л��ѡ��� exit ���������Ѿ�����ϸ�ط������ˣ�������ʱ�����Ѿ���һ������������˰ɡ���Ϊɶ notify ��ֱ�ӻ����أ���Ϊ wait �ȴ����߳��� synchronized ͬ�����е�ѽ������Ҫ�õ� monitor ���ܼ���ִ�а���ʲôʱ������õ� monitor �أ�Ҳ���DZ��� exit ��ʱ������ܰ�����ͽ�����Ϊë notify ��ֱ�ӻ��Ѷ����� exit ��ʱ���ѡ�
���棬���ǿ����� JVM ��Ĭ�ϲ����� 2���������Ƿֱ����һ�²�ͬ�IJ�������
���� 0 ��ִ�������£�
1 2 3 4 5 6 7 8 9 10 if (list == NULL) { iterator->_next = iterator->_prev = NULL; _EntryList = iterator; } else { list->_prev = iterator; iterator->_next = list; iterator->_prev = NULL; _EntryList = iterator; }��� EntryList Ϊ�յĻ�����ʾ֮ǰû���̱߳� notify ���ѣ��Ѿ�ֱ�ӽ���ǰ�ڵ�ŵ� EntryList �м��ɡ�����Ļ����ͽ���ǰ�ڵ�ŵ� EntryList ��ͷ����
��������ͨ��һ��ʵ������֤���ǵĽ��ۡ�
ʵ��� java ���룺
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 Thread t0 = new Thread(new Runnable() { ? public void run() { System.out.println("Thread 0 start!!!!!!"); synchronized (lock) { try { lock.wait(); } catch (Exception e) { } System.out.println("Thread 0 end!!!!!!"); } } }); ? Thread t1 = new Thread(new Runnable() { ? public void run() { System.out.println("Thread 1 start!!!!!!"); synchronized (lock) { try { lock.wait(); } catch (Exception e) { } System.out.println("Thread 1 end!!!!!!"); } } }); ? Thread t2 = new Thread(new Runnable() { ? public void run() { System.out.println("Thread 2 start!!!!!!"); synchronized (lock) { try { lock.wait(); } catch (Exception e) { } System.out.println("Thread 2 end!!!!!!"); } } }); ? Thread t3 = new Thread(new Runnable() { ? public void run() { System.out.println("Thread 3 start!!!!!!"); synchronized (lock) { for (int i = 0; i < 3; i++) { try { System.in.read(); } catch (Exception e) { } lock.notify(); } System.out.println("Thread 3 end!!!!!!"); } } }); ? t0.start(); try { TimeUnit.SECONDS.sleep(1); } catch (Exception e) { ? } t1.start(); try { TimeUnit.SECONDS.sleep(1); } catch (Exception e) { ? } t2.start(); try { TimeUnit.SECONDS.sleep(1); } catch (Exception e) { ? } t3.start(); try { TimeUnit.SECONDS.sleep(1); } catch (Exception e) { ? }���Ұ������λس���֮ǰ�� WaitSet ״̬���£�
�������ΰ������λس�����֮��WaitSet ������Ϊ�գ���ʱ EntryList ���£�
���ǽ� Knob_MoveNotifyee ��Ĭ��ֵ�� 0��Ȼ�����±��� JVM��ִ������� java ���������£�
1 2 3 4 5 6 7 8 9 10 11 12 Thread 0 start!!!!!! Thread 1 start!!!!!! Thread 2 start!!!!!! Thread 3 start!!!!!! ? ? ? Thread 3 end!!!!!! Thread 2 end!!!!!! Thread 1 end!!!!!! Thread 0 end!!!!!!���Կ����߳̽������е�˳������Ƿ�����һ�������� 2 -> 1 -> 0��
���� 1 �Ͳ��� 0 �������ƣ�ֻ�����ォ�ڵ�ŵ�β����
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 if (list == NULL) { iterator->_next = iterator->_prev = NULL; _EntryList = iterator; } else { // CONSIDER: finding the tail currently requires a linear-time walk of // the EntryList. We can make tail access constant-time by converting to // a CDLL instead of using our current DLL. ObjectWaiter * tail; for (tail = list; tail->_next != NULL; tail = tail->_next) {} assert(tail != NULL && tail->_next == NULL, "invariant"); tail->_next = iterator; iterator->_prev = tail; iterator->_next = NULL; }�����ע�ͺ�����˼��˵�ǿ��Խ� EntryList ����ѭ��˫����У�CDLL�������Ż���������Ϊ CDLL ���� tail �ڵ��ʱ���dz���ʱ��ģ��������Ȥ�������������ʵ�֣���������Ը� JVM �ύһ�� patch��Ȼ����Ҳ�� JVM Դ�빱����֮һ�ء�����
�������ǿ���������� 0 �Ĵ���ִ�еĽ����
1 2 3 4 5 6 7 8 9 10 11 12 Thread 0 start!!!!!! Thread 1 start!!!!!! Thread 2 start!!!!!! Thread 3 start!!!!!! ? ? ? Thread 3 end!!!!!! Thread 0 end!!!!!! Thread 1 end!!!!!! Thread 2 end!!!!!!���Կ���������Ľ�����˳��Ͳ��� 0 ���෴�ġ�
���� 0 �Ͳ��� 1 �ǽ���Ҫ���ѵĽڵ�ŵ� EntryLIst �У������� 2 �Ͳ��� 3 �ǽ��ڵ�ŵ� cxq �����У�ֻ�������� 2 �ŵ� cxq ��ͷ�������� 3 �ŵ� cxq ��β����
���� 2 ��Ĭ�ϲ��ԣ�Ҳ����˵������ϵ� JVM ��Ϊ�ǽ����ѵĽڵ�ŵ� cxq ���е�ͷ�����㻹�ǵ� cxq ���аɣ����� synchronized �ĵȴ����а���ϣ���㻹û�����ǡ�
Ϊ����֤���ǵĽ��ۣ�������Ҫʹ��һ����һ���� java ���룬������Ҫ��� synchronized �������в��ܿ���Ч����
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 Thread t0 = new Thread(new Runnable() { ? public void run() { System.out.println("Thread 0 start!!!!!!"); synchronized (lock) { try { lock.wait(); } catch (Exception e) { } System.out.println("Thread 0 end!!!!!!"); } } }); ? Thread t1 = new Thread(new Runnable() { ? public void run() { System.out.println("Thread 1 start!!!!!!"); synchronized (lock) { try { lock.wait(); } catch (Exception e) { } System.out.println("Thread 1 end!!!!!!"); } } }); ? Thread t2 = new Thread(new Runnable() { ? public void run() { System.out.println("Thread 2 start!!!!!!"); synchronized (lock) { try { lock.wait(); } catch (Exception e) { } System.out.println("Thread 2 end!!!!!!"); } } }); ? Thread t3 = new Thread(new Runnable() { ? public void run() { System.out.println("Thread 3 start!!!!!!"); synchronized (lock) { try { System.in.read(); } catch (Exception e) { } lock.notify(); lock.notify(); lock.notify(); System.out.println("Thread 3 end!!!!!!"); } } }); ? Thread t4 = new Thread(new Runnable() { ? public void run() { System.out.println("Thread 4 start!!!!!!"); synchronized (lock) { System.out.println("Thread 4 end!!!!!!"); } } }); ? Thread t5 = new Thread(new Runnable() { ? public void run() { System.out.println("Thread 5 start!!!!!!"); synchronized (lock) { System.out.println("Thread 5 end!!!!!!"); } } }); ? Thread t6 = new Thread(new Runnable() { ? public void run() { System.out.println("Thread 6 start!!!!!!"); synchronized (lock) { System.out.println("Thread 6 end!!!!!!"); } } }); ? t0.start(); try { TimeUnit.SECONDS.sleep(1); } catch (Exception e) { ? } t1.start(); try { TimeUnit.SECONDS.sleep(1); } catch (Exception e) { ? } t2.start(); try { TimeUnit.SECONDS.sleep(1); } catch (Exception e) { ? } t3.start(); try { TimeUnit.SECONDS.sleep(1); } catch (Exception e) { ? } t4.start(); try { TimeUnit.SECONDS.sleep(1); } catch (Exception e) { ? } t5.start(); try { TimeUnit.SECONDS.sleep(1); } catch (Exception e) { ? } t6.start();���������� 6 ���̣߳����� 0 �� 2 �ǻ� wait �� WaitSet �еģ�4 �� 6 �ǵȴ��� cxq �еġ�
�õģ��������ǿ��²��� 2��Ҳ����Ĭ�ϲ��Ե�ִ������
1 2 3 4 5 6 7 8 9 10 11 12 13 14 if (list == NULL) { iterator->_next = iterator->_prev = NULL; _EntryList = iterator; } else { iterator->TState = ObjectWaiter::TS_CXQ; for (;;) { ObjectWaiter * front = _cxq; iterator->_next = front; if (Atomic::cmpxchg(iterator, &_cxq, front) == front) { break; } } }����������� EntryList Ϊ�յĻ���Ҳ���ǵ�һ���� notify ���ѵ��̻߳���뵽 EntryList���� WaitSet ��ʣ�µĽڵ�����β��뵽 cxq ��ͷ����Ȼ����� cxq ָ��ָ���µ�ͷ�ڵ㡣
������� java ����Ϊ�������Ұ��»س���֮ǰ��״̬���£�
���Ұ��»س�֮��״̬���£�
��ˣ��� exit ��ʱ����Ĭ��״̬�»�ʵ�ֻ��� EntryList ���̣߳�Ȼ���ڻ��� cxq �еģ����Ի��ѵ�˳���ǣ�0 -> 2 -> 1 -> 6 -> 5 -> 4��
��������ִ�д��룬��֤���ǵIJ��룺
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 Thread 0 start!!!!!! Thread 1 start!!!!!! Thread 2 start!!!!!! Thread 3 start!!!!!! Thread 4 start!!!!!! Thread 5 start!!!!!! Thread 6 start!!!!!! ? Thread 3 end!!!!!! Thread 0 end!!!!!! Thread 2 end!!!!!! Thread 1 end!!!!!! Thread 6 end!!!!!! Thread 5 end!!!!!! Thread 4 end!!!!!!���Կ����������ǵIJ�����ȫһ����
���� 3 �����Ͳ��� 2 �Ƚ����ƣ�ֻ�Dz��� 3 �Ὣ�ڵ�ŵ� cxq β��:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 iterator->TState = ObjectWaiter::TS_CXQ; for (;;) { ObjectWaiter * tail = _cxq; if (tail == NULL) { iterator->_next = NULL; if (Atomic::replace_if_null(iterator, &_cxq)) { break; } } else { while (tail->_next != NULL) tail = tail->_next; tail->_next = iterator; iterator->_prev = tail; iterator->_next = NULL; break; } }���ﲻ���ж� EntryList �Ƿ�Ϊ�գ�����ֱ�ӽ��ڵ�ŵ� cxq ��β������һ���ǰ�漸�����Բ�һ������Ҫע���¡�
�������ǿ���Ԥ�⣬������� 3 ��֤�����еĻ���˳���ǣ�6 -> 5 -> 4 -> 0 ->1 -> 2������ִ���´��뿴�������
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 Thread 0 start!!!!!! Thread 1 start!!!!!! Thread 2 start!!!!!! Thread 3 start!!!!!! Thread 4 start!!!!!! Thread 5 start!!!!!! Thread 6 start!!!!!! ? Thread 3 end!!!!!! Thread 6 end!!!!!! Thread 5 end!!!!!! Thread 4 end!!!!!! Thread 0 end!!!!!! Thread 1 end!!!!!! Thread 2 end!!!!!!���Կ����������ǵ�Ԥ������Ȼ��һ���ġ�
���������Ǿ�������������� notify ��ʵ�����������ϵ�ʵ�ֻ��DZȽϼģ�ֻ�Ǹ��ݲ�ͬ�IJ���ִ�в�ͬ�Ļ��ѳ�������ͬʱ���������� exit �еij�����Э�����������������Ѿ�ͨ��ʵ�ʵ�������֤����һ�㡣
notifyAll ��ʵ����ʵ�� notify ʵ�ִ�ͬС�죺
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 void ObjectMonitor::notifyAll(TRAPS) { CHECK_OWNER(); if (_WaitSet == NULL) { TEVENT(Empty-NotifyAll); return; } ? DTRACE_MONITOR_PROBE(notifyAll, this, object(), THREAD); int tally = 0; while (_WaitSet != NULL) { tally++; INotify(THREAD); } ? OM_PERFDATA_OP(Notifications, inc(tally)); }���Կ�������ʵ���Ǹ��� WaitSet ���ȣ��������� INotify �������൱�ڶ�ε��� notify���������Ͳ������ˡ�
?
??
Volatile ��������Dz�����������һ���dz�����˼�Ļ��⣬�漰���dz����ϸ�ڡ��� C/C++ �� Java �ж��� volatile ����ؼ��֣���ʵ��̽������ؼ��ֵ�����֮ǰ�������ȿ�������ʵ����溬�壬�����ǿ���˹�߽״ʵ��еĺ��壺
A situation that is volatile is likely to change suddenly and unexpectedly.
����Ľ�����������Ҫ�ĺ��壺
��ˣ������������ʹ������ؼ����������ǵı���������ζ�ţ�����������ܻ����κ�ʱ��ı�Ϊ�κ�ֵ���κ�ʹ�÷�����ʵʱ��ע���ֵ�ı仯�����Ҳ��������κμ��衣
��ʵ��̽�� Java �е� volatile �ؼ��ֵ�����֮ǰ���������ȿ��� C/C++ �еĹؼ��ֵ����壬������ C/C++ �� volatile ����������� volatile �dz��а�����
�鿴 C volatile ��������ķ�ʽ���ǿ�?CPP Reference?�еĽ��ܣ�
Every access (both read and write) made through an lvalue expression of volatile-qualified type is considered an observable side effect for the purpose of optimization and is evaluated strictly according to the rules of the abstract machine (that is, all writes are completed at some time before the next sequence point). This means that within a single thread of execution, a volatile access cannot be optimized out or reordered relative to another visible side effect that is separated by a?sequence point?from the volatile access.
��������������ǿ��Կ����� C �ж� volatile �ķ��ʹ������£�
��������ͨ��һ�����������˽��� C �е� volatile �ؼ��֡�
������һ�μ� c ����
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 static int a = 12345; static int t = 9090; ? int main(void) { ? int b = a; ? int c = a; ? int e = t; ? return b + c + e; }����ͨ�������������� c �������� .s �����룺
1 2 gcc -S -O3 main.c -o main.s�õ����»����룺
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 .section __TEXT,__text,regular,pure_instructions .macosx_version_min 10, 13 .globl _main ## -- Begin function main .p2align 4, 0x90 _main: ## @main .cfi_startproc ## %bb.0: pushq %rbp .cfi_def_cfa_offset 16 .cfi_offset %rbp, -16 movq %rsp, %rbp .cfi_def_cfa_register %rbp movl $33780, %eax ## imm = 0x83F4 popq %rbp retq .cfi_endproc ## -- End function ? .subsections_via_symbols���Կ���������������Ѿ������ǽ���Ҫ return �Ľ����������ˣ������ٽ���ȡֵȻ������ˡ�Ҳ����˵��gcc �������Ѿ�������ǵı��������ڴ��ϵļ��衣�������ǽ����� a �� t ʹ�� volatile �����Σ�
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 static volatile int a = 12345; static volatile int t = 9090; ? int main(void) { ? int b = a; ? int c = a; ? int e = t; ? return b + c + e; }���Եõ����»�ࣺ
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 .section __TEXT,__text,regular,pure_instructions .macosx_version_min 10, 13 .globl _main ## -- Begin function main .p2align 4, 0x90 _main: ## @main .cfi_startproc ## %bb.0: pushq %rbp .cfi_def_cfa_offset 16 .cfi_offset %rbp, -16 movq %rsp, %rbp .cfi_def_cfa_register %rbp movl _a(%rip), %eax addl _a(%rip), %eax addl _t(%rip), %eax popq %rbp retq .cfi_endproc ## -- End function .section __DATA,__data .p2align 2 ## @a _a: .long 12345 ## 0x3039 ? .p2align 2 ## @t _t: .long 9090 ## 0x2382 ? ? .subsections_via_symbols���Ժ������ؿ������������ volatile ֮�� gcc �Ͳ���Ա�����ֵ�����κμ��裬ֻ������ʵʵ�ذ����Ͱ��ȡȻ����㡣
���ϵ�һ��С���Ӿ���֤���������ǽ����� c �е� volatile ��һ�����ԣ���ֹ���Ż���ʧ�����ڵڶ����ص㣺�����������Ż��������DZ�֤�˱� volatile ���εı����ڱ���֮�����ɵĻ�����˳��϶���ԭʼ�����е�˳����һ���ġ�
������������DZ�֤�˱���֮��Ļ���ָ����������ģ��������Ƕ�֪���ִ��� CPU ������ִ��ָ�ֻҪ��֤���յĽ����ȷ���ɡ���ˣ������ volatile ֻ�ܱ�֤����β��������Ż������ܱ�ִ֤�нε������Ż��������Ҫ��ִ֤�нε������Ż�����ʹ��ϵͳ�ṩ���ڴ����ϼ�����ʵ�֡�
������� C++ ����ķ��������Բο���ƪ���ģ���ĩ�ο��������У���C/C++ �е� volatile ����
�������Ǽ��˽����� c �е� volatile �����壬���Ƕ� volatile ����һ�������ϵ���ʶ����ô�� java �е� volatile ����������ʲô�أ����������£�
����ĵ�һ���������Ŵ�Ҷ��˽⣬Ҳ������ͨ����������֤�����������ص㿴�µڶ�����������ô��֤�ġ�����֪�� JVM Ϊ�˼ӿ�ִ�е�Ч�ʣ�ͨ������� JIT ���Ż�����ִ�е��ٶȣ�Ҳ����˵������ JIT compile ֮��Ĵ��룬�Ͳ�����ִ���ֽ����ˣ�����ֱ��ִ�ж�Ӧ�ĵײ�����롣��������ܹ��а취�õ� JIT ִ�еĶ�Ӧ�����룬���Dz����ܿ�̽�� JVM �ײ���ִ�� volatile �����Ĵ�ȡʱ��ִ���������ǵģ�������Ŀ��Ի�ȡ�� JVM �ײ�� JIT �������룬�� OpenJDK ��Դ�����ṩ��һ���dz�ǿ��Ĺ��ߣ�hsdis������������ߵĽ��ܿ��Բο�Դ���е� README��/src/utils/hsdis/README��������Ҫ������������ߣ������ʱ����Ҫ binutils ��� GNU �����ϵ�Դ�룬����ֻҪ�����غõ� binutils ����ŵ�ͬһ��Ŀ¼�£�Ȼ��ִ����������ɱ��� hsdis��
1 2 make BINUTILS=binutils-2.17 ARCH=amd64 CFLAGS="-Wno-error"��Ϊ�ҵĻ����� 64 bit �ģ���������ִ�� ARCH Ϊ amd64������Ϊ������ mac ƽ̨�ϱ���ģ�Ĭ��ʹ�� clang��apple xcode ����������������߱� gcc ���Ҫ�ϸ�ض࣬�����Ҫ���� CFLAGS=��-Wno-error������Ȼ�ܶ� binutils �е� warning ȫ���������������롣����Ҫ˵�����ǣ��������ʹ�� 2.17 �汾�� binutils����İ汾�Ҷ�����ʧ���ˣ���Ϊ�ӿڲ������ˣ���һ����ʵ�� README ��Ҳ��˵����
�������˳�����룬�����ڵ�ǰĿ¼�µ� build/macosx-amd64 Ŀ¼�¿����������ݣ�
1 2 3 4 5 6 7 8 9 10 11 -rw-r--r-- 1 gaochao staff 289K 7 23 13:39 Makefile drwxr-xr-x 90 gaochao staff 2.8K 7 23 15:50 bfd -rw-r--r-- 1 gaochao staff 2.6K 7 23 13:39 config.cache -rw-r--r-- 1 gaochao staff 5.1K 7 23 13:39 config.log -rwxr-xr-x 1 gaochao staff 9.5K 7 23 15:50 config.status -rwxr-xr-x 1 gaochao staff 587K 7 23 13:40 hsdis-amd64.dylib drwxr-xr-x 10 gaochao staff 320B 7 23 15:50 intl drwxr-xr-x 64 gaochao staff 2.0K 7 23 15:50 libiberty drwxr-xr-x 26 gaochao staff 832B 7 23 15:50 opcodes -rw-r--r-- 1 gaochao staff 13B 7 23 13:39 serdep.tmp����� hsdis-amd64.dylib ��������Ҫ�Ľ�������ǽ������̬�⿽��������Ŀ¼��
build/macosx-x86_64-normal-server-fastdebug/jdk/lib
���� JVM Դ����������Ŀ¼����Ϊ�ұ������ fastdebug �汾�� JVM����˷ŵ�������������ǾͿ���ͨ�� java ����ʹ���������ˡ�
�������Ƕ���һ�����µIJ��� java ���룺
1 2 3 4 5 6 7 8 9 10 public class Count { private volatile int count = 0; private volatile int test = 0; ? public void testMethod() { count++; test++; } }����� Counter�����м���ͨ�� volatile ʵ�֡�Ȼ�������ڲ��Դ����е������ Counter��
1 2 3 4 5 6 7 8 9 public class Hello { public static void main(String[] args) { Count count = new Count(); for (int i = 0; i < 100000; i++) { count.testMethod(); } } }ע�⣬Ϊ���ܹ����� JIT �Ż�������ǿ�ƽ� testMethod ����ִ�� 100000���������ܽ� JVM �еĴ������������� JIT ���롣
Ȼ��������ϴ��룬Ȼ����������ִ������������ִ�д��룺
1 2 java -XX:+PrintAssembly -XX:CompileCommand=dontinline,Count.testMethod -XX:CompileCommand=compileonly,Count.testMethod Hello > out�������һ������������������ʹ�� -XX:+PrintAssembly ����ʹ�� hsdis �����ȡ JIT �����룬Ȼ��ͨ�� XX:CompileCommand ����ָ����Ҫ�����ǵĴ��������Ż�������ֻ���� Count.testMethod �����������������Dz����ġ�
������������˳��ִ�У����ǻ�õ� out ����ļ�������ļ��dz�������������ֻ�� testMethod ����ִ�еĻ����룺
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 0x00000001116b1234: mov 0xc(%rsi),%edi ;*getfield count {reexecute=0 rethrow=0 return_oop=0} ; - Count::testMethod@2 (line 6) ? 0x00000001116b1237: inc %edi 0x00000001116b1239: mov %edi,0xc(%rsi) 0x00000001116b123c: lock addl $0x0,0xffffffffffffffc0(%rsp) ;*putfield count {reexecute=0 rethrow=0 return_oop=0} ; - Count::testMethod@7 (line 6) ? 0x00000001116b1242: mov 0x10(%rsi),%edi ;*getfield test {reexecute=0 rethrow=0 return_oop=0} ; - Count::testMethod@12 (line 7) ? 0x00000001116b1245: inc %edi 0x00000001116b1247: mov %edi,0x10(%rsi) 0x00000001116b124a: lock addl $0x0,0xffffffffffffffc0(%rsp) ;*putfield test {reexecute=0 rethrow=0 return_oop=0} ; - Count::testMethod@17 (line 7) ? 0x00000001116b1250: add $0x30,%rsp 0x00000001116b1254: pop %rbp 0x00000001116b1255: mov 0x120(%r15),%r10 0x00000001116b125c: test %eax,(%r10) ; {poll_return}�����ڴ�������Ա������� ++ ������������˿��Կ�������ͨ�� mov ��ȡԭʼֵ��Ȼ��ͨ�� inc ָ�ֵ���� 1��Ȼ����ͨ�� mov ָ��µ�ֵ���͵�ջ�У�Ȼ��ͨ��һ�� lock addl ָ� rsp ջ�е����ݼ� 0��Ȼ�� ++ ��������������ˡ�ǰ��������������Ƕ������ף�ֻ�����һ�� lock addl �� rsp �� 0 ��̫�����⣬���ォһ��ֵ�� 0 ���൱��ʲô��û������仰�Ƿϻ�����ʵ���ǵģ�������Ҫ�˽��� lock ���ָ��ǰ������ʲô��������Ҫ������ intel �� IA32 ָ������ֲῴ�����ָ��ǰ�Ķ��壨LOCK��Assert LOCK# Signal Prefix С�ڣ���
���Կ���������������˵ͨ�� lock �����ڹ����ڴ��ϵͳ��ʹ�ñ����ε�ָ���Ϊһ��������ָ�Ҳ����˵ֻҪ���ָ����ִ���˿��Ա�֤�����������飺
����ʵ���� java �е� volatile �����尡��
����һ�����ʣ��Ǿ���Ϊɶʹ�� lock ���� addl�������� nop ָ���أ���ʵ����Ŀ������ֲ�˵�ĺ������lock ���治�ܸ� nop �ģ�ֻ�ܸ� add ֮���ָ���ˣ�JVM �Ͳ����� lock addl ��һ��ջ�е�ֵ�� 0 �����������IJ���ʵ�� volatile �����塣
ͨ������ķ���������Ҳ��֪���ˣ���java �е� volatile �ؼ������εı����ķ����� intel x86 CPU ����ͨ�� lock ���ε� addl ָ��ʵ�ֵġ�
?
from?https://createchance.github.io/post/java-%E5%B9%B6%E5%8F%91%E4%B9%8B%E5%9F%BA%E7%9F%B3%E7%AF%87/
?
?