?
?思路转载自Hollis的知识星球,有兴趣的可以搜一下,很不错。
?
业务介绍:
1.痛点:解决的问题,用户痛点
2.正确性
3.可用性
4.大规模:量级
思考问题:
宏观,不局限于业务
?
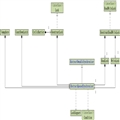
这种问题直接回答高并发分布式场景的数据一致性问题。(参考:链接:[高级]关于分布式一致性的探究)
?
然后面试官问:如何解决的呢。
?
答:在并发方面考虑了乐观锁和分布式锁。在一致性方面不同场景使用了不同策略。
?
问:介绍下乐观锁答:乐观锁巴拉巴拉(参考:链接:[初级]深入理解乐观锁与悲观锁)
?
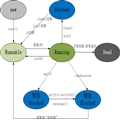
问:分布式锁如何实现答:基于数据库,基于缓存,基于zk三种。然后再把三种方案的优缺点说清楚。(参考:链接:分布式锁的多种实现方式~)
?
问:关于缓存和ZK了解多少答:常用缓存,redis,memcached等。当然还可以说memcached容易被总来做DDOS攻击(参考:链接:GitHub遭受的DDoS攻击到底是个什么鬼?)。ZK就简单介绍下原理,常用场景等。(参考:链接:[高级]Zookeeper介绍(四)――Zookeeper中的基本概念)
?
问:数据一致性怎么保证答:先扯一段CAP和BASE(参考:链接:分布式的CAP理论 和 ),再说说2PC,3PC(参考:链接:深入理解分布式系统的2PC和3PC)以及有啥缺点,过度目前常用的策略。比如最大努力通知,可靠消息最终一致性。TCC分布式事务等(文章规划中,还没写)。在说下业务场景都有哪几个。
?
最终是如何选择的。最后再说一句:当然,数据一致性的最后一道防线还是人工介入。要做好数据对账,实时数据检验以及报警。保证可以及时发现线上问题。。
---------------------?
版权声明:本文为CSDN博主「Franco蜡笔小强」的原创文章,遵循CC 4.0 by-sa版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/w372426096/article/details/80436764