java读取txt文件乱码解决方案
2017年09月19日 14:42:52 sysmedia 阅读数 3682
因为txt默认的选项是ANSI,即GBK
编码。GBK和GB2312都是中文编码,在这里解释一下两者的区别。
总体说来,GBK包括所有的汉字,包括简体和繁体。而gb2312则只包括简体汉字。
GBK: 汉字国标扩展码,基本上采用了原来GB2312-80所有的汉字及码位,并涵盖了原Unicode中所有的汉字20902,总共收录了883个符号, 21003个汉字及提供了1894个造字码位。 Microsoft简体版中文Windows 95就是以GBK为内码,又由于GBK同时也涵盖了Unicode所有CJK汉字,所以也可以和Unicode做一一对应。
GB码,全称是GB2312-80《信息交换用汉字编码字符集 基本集》,1980年发布,是中文信息处理的国家标准,在大陆及海外使用简体中文的地区(如新加坡等)是强制使用的唯一中文编码。P-Windows3.2和苹果OS就是以GB2312为基本汉字编码, Windows 95/98则以GBK为基本汉字编码、但兼容支持GB2312。GB码共收录6763个简体汉字、682个符号,其中汉字部分:一级字3755,以拼音排序,二级字3008,以偏旁排序。该标准的制定和应用为规范、推动中文
信息化进程起了很大作用。
GBK编码是
中国大陆制订的、等同于UCS的新的中文编码扩展国家标准。GBK工作小组于1995年10月,同年12月完成GBK规范。该编码标准兼容GB2312,共收录汉字21003个、符号883个,并提供1894个造字码位,简、繁体字融于一库。
那么如何查看txt的编码呢,教你一个笨笨的办法:打开文件――另存为,然后看到最下面的编码,默认选择的就是当前文档的编码格式)。
txt文本文档有四种编码选项:ANSI、Unicode、Unicode big endian、UTF-8;默认应该是ANSI选项,就是系统的默认编码,一般是GBK。
因此我们读取txt文件可能有时候并不知道其编码格式,所以需要用程序动态判断获取txt文件编码,这里给一点资料,参考参考:
ANSI: 无格式定义
Unicode: 前两个字节为FFFE Unicode文档以0xFFFE开头
Unicode big endian: 前两字节为FEFF
UTF-8: 前两字节为EFBB UTF-8以0xEFBBBF开头
用程序取出前几个字节并进行判断即可。
首先对java中得编码格式进行了
研究。
发现在java中
java编码与
txt编码对应
java txt
unicode unicode big endian
utf-8 utf-8
utf-16 unicode
gb2312 ANSI
java读取txt文件,如果编码格式不匹配,就会出现乱码现象。所以读取txt文件的时候需要设置读取编码。txt文档编码格式都是写在文件头的,在程序中需要先
解析文件的编码格式,获得编码格式后,在按此格式读取文件就不会产生乱码了。
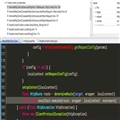
代码示例如下:
Java代码 收藏代码
package com.lfl.attachment;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileInputStream;
import java.io.InputStream;
import java.io.InputStreamReader;
public
class TextMain {
public static void main(String[] args) throws Exception {
String filePath = "D:/article.txt";
// String filePath = "D:/article333.txt";
// String filePath = "D:/article111.txt";
String content = readTxt(filePath);
System.out.println(content);
}
/**
* 解析普通文本文件 流式文件 如txt
* @param path
* @return
*/
@SuppressWarnings("unused")
public static String readTxt(String path){
StringBuilder content = new StringBuilder("");
try {
String code = resolveCode(path);
File file = new File(path);
InputStream is = new FileInputStream(file);
InputStreamReader isr = new InputStreamReader(is, code);
BufferedReader br = new BufferedReader(isr);
// char[] buf = new char[1024];
// int i = br.read(buf);
// String s= new String(buf);
// System.out.println(s);
String str = "";
while (null != (str = br.readLine())) {
content.append(str);
}
br.close();
} catch (Exception e) {
e.printStackTrace();
System.err.println("读取文件:" + path + "失败!");
}
return content.toString();
}
public static String resolveCode(String path) throws Exception {
// String filePath = "D:/article.txt"; //[-76, -85, -71] ANSI
// String filePath = "D:/article111.txt"; //[-2, -1, 79] unicode big endian
// String filePath = "D:/article222.txt"; //[-1, -2, 32] unicode
// String filePath = "D:/article333.txt"; //[-17, -69, -65] UTF-8
InputStream inputStream = new FileInputStream(path);
byte[] head = new byte[3];
inputStream.read(head);
String code = "gb2312"; //或GBK
if (head[0] == -1 && head[1] == -2 )
code = "UTF-16";
else if (head[0] == -2 && head[1] == -1 )
code = "Unicode";
else if(head[0]==-17 && head[1]==-69 && head[2] ==-65)
code = "UTF-8";
inputStream.close();
System.out.println(code);
return code;
}
}
注意:在resolveTxt方法中不能通过readTxt方法传InputStream流 ,这样会使两个方法持有同一个流引用,而在resolveTxt方法中已读过流中的三个字节,流中的pos此时已经是3了,而不是流的起始位置,再在readTxt中读取时就会出现IOException:Read Error。