��ȥ��д�������ѧϰ�ʼǣ��ߣ�-����spark
�ű���ԭ����֮�����ڹ����Ƚ�æ���Ҵ������ڸ������Ŀ��һʱ�ò��ϣ�����û�м���ѧϰ��
��һƪ��
�µĿ�ʼ����Ҫѧϰʹ��spark�Ľ��п�����
spark��Դ����scalaд�ģ�scala����Java�����һ�����ԣ�Ҳ�ǻ���jvm���еġ�spark�ṩ��scala��java�Ŀ���������˿���ʹ��java��scala������sparkӦ�á�
���½��ܿ����������demo�ı�д��
һ�����������
1����װjdk1.8
2����ScalaIDE�������ؼ��ɺõ�eclipse
http://scala-ide.org/download/sdk.html
3) ��ѹ���غõİ�����ʹ��
���ˣ����ǿ���ʹ�����ص�eclipse���ɻ�������java��scala
�汾��spark����
����java demo
1�� ʹ��maven����java���̣�����������
class="xml" name="code">
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.gov.zjport.demo</groupId>
<artifactId>demo-spark</artifactId>
<version>0.0.1-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-launcher_2.11</artifactId>
<version>2.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.2.0</version>
</dependency>
</dependencies>
</project>
2��java����
package cn.gov.zjport.demo.spark;
import java.util.Arrays;
import java.util.List;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function2;
public class SparkLocalCollection {
public static void main(String[] args) {
//��ʼ��
SparkConf conf=new SparkConf().setAppName("SparkLocalCollection").setMaster("local");
JavaSparkContext sparkContext=new JavaSparkContext(conf);
try{
List<Integer> list=Arrays.asList(1,2,3,4,5,6,7,8,9,10);
//����RDD
JavaRDD<Integer> rdd=sparkContext.parallelize(list);
//ִ��reduce action����
int sum=rdd.reduce(new Function2<Integer, Integer, Integer>(){
private static final long serialVersionUID = 1L;
public Integer call(Integer arg0, Integer arg1) throws Exception {
return arg0+arg1;
}
});
System.out.println("add result:"+sum);
}finally{
sparkContext.close();
}
}
}
3������ run as -> Java Application

����scala demo
1���½�һ��maven���̣�����������
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<encoding>UTF-8</encoding>
<scala.version>2.11.11</scala.version>
<scala.compat.version>2.11</scala.compat.version>
<spec2.version>4.2.0</spec2.version>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-launcher_2.11</artifactId>
<version>2.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.3.0</version>
</dependency>
</dependencies>
2�������̸�Ϊscala����

3����дscala����
package cn.gov.zjport.demo.spark
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
object SparkLocalCollection {
def main(args:Array[String]){
//��ʼ��
var array=Array(1,2,3,4,5,6,7,8,9,10);
var conf=new SparkConf().setAppName("SparkLocalCollection").setMaster("local");
var sc=new SparkContext(conf);
try{
//�Ȳ��л�������RDD,Ȼ��ִ��reduce����
var count=sc.parallelize(array, 1).reduce(_+_);
println("count is:"+count);
}finally{
sc.stop();
}
}
}
4������ Run As -> Scala Application
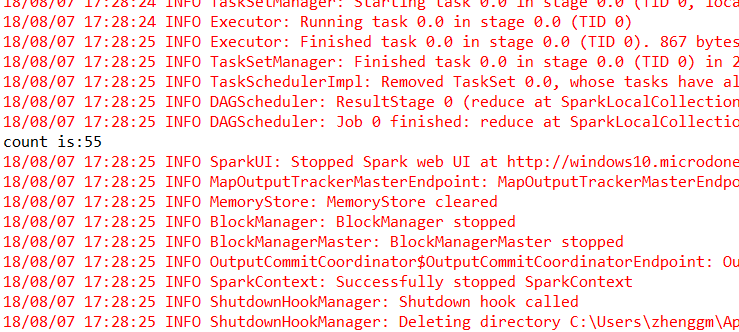
5)��ѧ�߳������⣺
a)Ϊʲô��û��run as->scala application
������û�ж���Ϊobject�����Ƕ����class�� class�������еġ� ͬʱ������main����
b)����ʱ��ʾ�Ҳ������� SparkLocalCollection
��Ҫ��F5 ����ʹ��maven����һ��

- ��С: 16.9 KB

- ��С: 16.8 KB

- ��С: 34.5 KB





