Elasticsearch是一个高度灵活的开源全文检索和分析引擎。它能够迅速(几乎是实时地)地存储、查找和分析大规模数据。通常被用在有复杂的搜索要求的系统中。比如:
在电子商务系统中用户搜索商品,可以使用Elasticsearch存储产品目录后为客户提供搜索接口。
如果要收集日志或交易信息,然后分析这些数据得到有价值信息,可以先使用Logstash收集、聚合、解析这些数据,然后存入Elasticsearch,利用Elasticsearch即可以挖掘有价值信息。
在商业数据分析领域,如果想要对海量数据进行实时的分析,将分析结果可视化,可以先将数据存入Elasticsearch,然后借助Kibana即可导出各种有用数据。
下面介绍Elasticsearch中几个基本概念:
Near Realtime(NRT):Elasticsearch是一个接近实时的查询平台,数据从被索引到可被搜索大概有1秒的延时。
Cluster:集群是共同存储数据且提供索引和查询能力的节点的集合。每个集群由一个唯一的名字标识,默认是elasticsearch。但是多个集群之间注意不要有重复的名字。一个集群中可以只包含一个节点。
Node:节点是集群中的一个服务器,用于存储数据,参与集群的索引和查询。节点有自己的名字,默认是一个随机的名字。指定节点名字在对集群的管理中非常重要,可以方便的根据名字知道是集群中哪一个节点。可以为节点指定一个集群名字,表示节点加入到这个集群中,默认都是加入elasticsearch这个集群。所以,在一个各个节点可以互通的网络中,如果未对节点指定集群名字,则默认所有节点均加入elasticsearch集群中(自动发现)。
Index:索引是有相似特征的数据项(Document)的集合。比如有顾客数据的索引,产品名录的索引,订单的索引等等。索引由全部是小写字母组成的名字标识,在建立索引、查找、更新、删除数据项的时候都会用到这个名字。在一个集群上,可以定义任意多的索引。
Type:在索引中,可以定义多个类型,类型可以看作索引的一个逻辑上的分类,其语义可以自己定义。假如在一个博客系统中所有的信息存储在一个单独的索引中,可以为用户数据定义一个类型,为博客数据定义一个类型,再为评论数据定义一个类型。
Document: document是一个可以被索引的基本的信息集合。例如,可以有某个顾客的document,某个产品的document,某个订单的document。Document以JSON的格式存在,在某一个索引/类型下,可以存储任意多的document。
Shard&Replicas:大数据时代,一个索引下面存储的数据很容易超过一个节点的存储能力,或者即使不超出,可能会对查询的性能造成影响。通过Elasticsearch可以在定义一个索引时指定将索引分为多个shard(碎片),每个碎片都是一个全功能的独立的“索引”,可以分布在集群中任意一个节点上。
使用shard有如下好处:
允许横向分隔、扩展存储空间
允许在shard间分布式、并行运行计算,可以提高ES的吞吐和性能
至于shard在nodes间是如何拼凑处理的,完全由ES负责,用户可以不关注这部分内容。
在企业级系统中,高可靠性至关重要,为了提高故障恢复能力,Elasticsearch允许对shard进行备份,称为replica shard或者简称replica。针对一个shard,可以有多个replica。
副本有如下好处:
一旦某个shard/node挂掉,它提供了高可用性,所以千万不要把replica和它的源shard(称为primary shard)放在一台机器上。
在多个副本上执行操作时也可以提高效率。
索引建立后,replica的数量是可以动态调节的,但是shard的数量是不可以改变的。默认情况下,ES中每个index被分配5个primary shard和1个replica,即集群中至少有2个节点,一个index有5个primary shard和5个replica(即每个index一共有10个shard)。
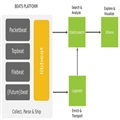
Beats是在被监控服务器上以客户端形式运行的数据收集器的统称,可以直接把数据发送给Elasticsearch或者通过Logstash发送给Elasticsearch,然后进行后续的数据分析活动。
elastic官方的Beats有Packetbeat、Topbeat和Filebeat:Packetbeat可以分析网络报文,抓取各个应用服务器的交换信息;Topbeat是一个服务器监控程序,可以周期性的监控系统及某个进程的信息;Filebeat用来从服务器上收集日志。

在被监控的系统使用Beats平台,要配合Elasticsearch、Logstash(如果需要的话)、Kibana共同使用。搭建该平台要求在安装Beat客户端的机器上可以访问到Elasticsearch、Logstash(如果有的话)以及Kibana服务器。随着系统的演进,可能会将Elasticsearch扩展为集群,或者将部署过程自动化。
1.安装Elasticsearch
Elasticsearch是一个实时的、分布式存储、查询和分析引擎。它尤其擅长索引半结构化的数据,比如日志或者网络报文。关于Elasticsearch的更详细的安装过程可以参考Elasticsearch安装过程,确认Elasticsearch安装并运行成功后,进行下一步。
2.安装Logstash(可选)
在最简单的Beats平台中,可以不使用Logstash,使用Logstash的优势在于可以自由调整Beats收集到的数据的格式,并且Logstash有很多output的插件可以与其他系统很好的结合。关于Logstash的更详细的安装过程可以参考这里。
确认Logstash安装并运行成功后,还需要对Logstash进行一些配置才可以配合Beats平台使用。比如,Logstash使用beats input plugin接收来自beat的数据(适配所有遵循beats框架的beat),然后使用Elasticsearch output plugin向Elasticsearch发送数据,比如在/etc/logstash/conf.d目录下添加配置文件beats-input.conf:
input {
beats {
port => 5044
type => "logs"
}
}
再添加如下配置文件output.conf:
output {
elasticsearch {
hosts => "localhost:9200"
index => "%{[@metadata][beat]}-%{+YYYY.MM.dd}"
document_type => "%{[@metadata][type]}"
}
}
当然,需要在Beat的配置文件中指定将收集到的数据发送给Logstash,下面以使用Filebeat收集日志为例讲解Logstash与Filebeat配合的方法。
3.安装Filebeat
在filebeat.yml的配置文件中,配置要监控的日志文件的路径,然后配置Filebeat向Logstash输出,需要在output字段将向Elasticsearch输出的配置注释掉,然后将向Logstash的输出的配置反注释掉。比如:
output:
logstash:
hosts: ["localhost:5044"]
在启动Filebeat之前,需要Elasticsearch加载相应的索引模板,推荐使用的模板在安装Filebeat的时候已经放在其配置路径下面了,名字叫做filebeat.template.json,可以使用如下命令装载模板:
$ curl -XPUT 'http://localhost:9200/_template/filebeat?pretty' -d@/etc/filebeat/filebeat.template.json
然后从下游到上游依次启动各个工具:
$ sudo service elasticsearch restart
$ sudo service logstash restart
$ sudo service filebeat restart
在被监控日志文件中添加内容,查看/var/lib/elasticsearch中是否有新增内容,如果有的话,进行下一步。
4.安装Kibana
Kibana是一个与Elasticsearch配合使用的图形化工具,提供高度可定制化的UI。关于Kibana的更详细的安装过程可以参考这里。确认Kibana安装并运行成功后,在浏览器中访问http://localhost:5601,第一次使用会跳转至Kibana的配置界面,填入配置的索引的pattern(本教程的index pattern是filebeat-*),敲入回车,然后点击Create:
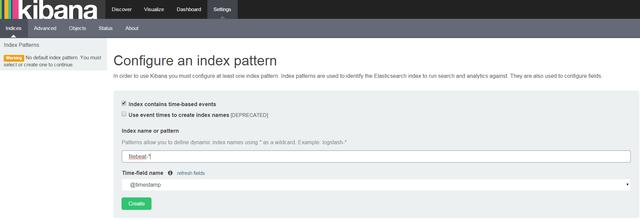
接下来显示将会被显示在Kibana的Field字段:

目前我们先忽略这部分的内容,点击左上角的Discover页签,在被监控的日志中添加新的一行并保存,就会看到日志中的信息:
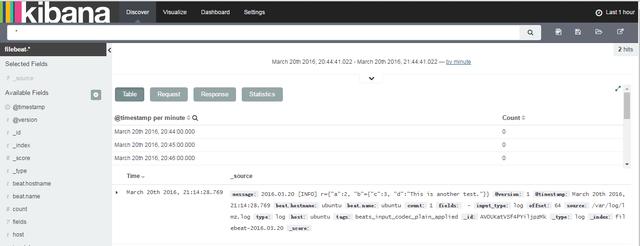
至此,最简单的ELK日志分析平台就搭建完成了。后续如果想根据自己的需求进行定制,需要继续深入研究Filebeat、Logstash、Elasticsearch及Kibana的配置了。
加群:433540541,免费获取一份ELK的学习资料。
关注公众号后台回复架构师资料,可免费领取架构学习资料

?