1. short s1 = 1; s1 = s1 + 1;���?short s1 = 1; s1 += 1;���
����short s1 = 1; s1 = s1 + 1;����1��int���ͣ����s1+1������Ҳ��int �ͣ���Ҫǿ��ת������
��short s1 = 1; s1 += 1;������ȷ���룬��Ϊs1+= 1;�൱��s1 = (short)(s1 + 1);������������ǿ��
����ת��
2. &��&&������
&������������÷���(1)��λ�룻(2)���롣&&������Ƕ�·�����㡣
�������·��IJ���Ƿdz���ģ���Ȼ���߶�Ҫ��������������˵IJ���ֵ����true����
����ʽ��ֵ����true��
&&֮���Գ�Ϊ��·��������Ϊ�����&&��ߵı���ʽ��ֵ��false���ұߵı���ʽ�ᱻֱ�Ӷ�·��������������㡣
3. swtich �Ƿ���������byte�ϣ��Ƿ���������long�ϣ��Ƿ���������String�ϣ�
switch(expr)�У�expr֧��byte��short��char��int��enum��string��1.7��
4. ��������ֵ��ͬ(x.equals(y) == true)����ȴ���в�ͬ��
hash code����仰�Բ��ԣ�
�𣺲��ԣ������������x��y����x.equals(y) == true�����ǵĹ�ϣ�루hash code��Ӧ����ͬ��Java����eqauls������hashCode�����������涨�ģ�(1)�������������ͬ��equals��������true������ô���ǵ�hashCodeֵһ��Ҫ��ͬ��(2)������������hashCode��ͬ�����Dz���һ����ͬ��
5. ����equals��hashCode������
equals������������
�Է��ԣ�x.equals(x)���뷵��true����
�Գ��ԣ�x.equals(y)����trueʱ��y.equals(x)Ҳ���뷵��true����
�����ԣ�x.equals(y)��y.equals(z)������trueʱ��x.equals(z)Ҳ���뷵��true��
һ���ԣ���x��y���õĶ�����Ϣû�б���ʱ����ε���x.equals(y)Ӧ�õõ�ͬ���ķ���ֵ��
6.
������Overload������д��Override�����������صķ����ܷ���ݷ������ͽ������֣�
���أ�һ������ͬһ�������������������Ͳ�ͬ���Է���ֵ��Ҫ��
��д��Ҫ�����౻��д��������ͬ�ķ������͡��ȸ�����д�ķ������÷��ʣ����ܱȸ�����д�����и����
�쳣��
7. ���ʵ�ֶ����¡��
1). ʵ��Cloneable
�ӿ�����дObject���е�clone()������
2). ʵ��Serializable�ӿڣ�ͨ�������
���л��ͷ����л�ʵ�ֿ�¡������ʵ����������ȿ�¡
public static <T> T clone(T obj) throws Exception {
ByteArrayOutputStream bout = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bout);
oos.writeObject(obj);
ByteArrayInputStream bin = new ByteArrayInputStream(bout.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bin);
return (T) ois.readObject();
}
�������л��ͷ����л�ʵ�ֵĿ�¡����������ȿ�¡������Ҫ����ͨ��
�����������Լ���Ҫ��¡�Ķ����Ƿ�֧�����л����������DZ�������ɵģ�����������ʱ�׳��쳣�������Ƿ�����������ʹ��Object���clone������¡�����������ڱ����ʱ��¶�����������ڰ�������������ʱ��
8.
��������ʱ
�������ĵ���˳��
Ϊ�������洢�ռ�
��ʼ�������
�ӳ��ൽ�����static��Ա���г�ʼ��
�����Ա������˳���ʼ����
�ݹ����ó���Ĺ��췽��
�����Ա������˳���ʼ��������췽������
9. ArrayList��linkedList
ArrayList���ڶ�̬����ʵ�֣���ѯ�졢����ɾ����
LinkedList��������ʵ�֣�����ɾ���죬��ѯ��
10. hashSet����LinkedHashSet��TreeSet
hashSet������hashMapʵ�ֵģ������ܰ����ظ�Ԫ�أ���
�߳���ȫ��
LinkedHashSet��HashSet�����࣬ʹ������ά��Ԫ�صĴ�������
�̰߳�ȫ
TreeSet��ʹ�ú�����ṹʵ�֣���sortedSet�ӿڵ�Ψһʵ���࣬����ȷ��������Ԫ�ش�������״̬
11. HashMap��LinkedHashMap��TreeMap
HashMap���ڵײ㽫key-value��װ��һ��Entry�������д��������ݼ�ֵ��hashcodeֵ�洢����
LinkedHashMap���̳���HashMap�����ڲ�������һ�����������Դ��Ԫ�ص�˳����Ԫ�صĽ���˳������
TreeMap��ʵ��SortMap�ӿڣ��ܹ���������ļ�¼���ݼ�����
12. concurrentHashMap
ConcurrentHashMap
�����̰�ȫ�Ļ������ṩ�˸��õ�д������������ͬʱ������������volatile��final��CAS��lock-free�����������������������ܵ�Ӱ�죬�����˶Զ�һ���Ե�Ҫ��
Jdk1.7�У�concurrenthashMap�ĺ����Ƿֶ�������������������ͬʱ�����˶�һ���Ե�Ҫ��
Jdk1.8�У�concurrentHashMap�ĺ�����volatile����+CAS���Ƚϲ��������ֹ�����ʵ�ֻ��ơ�
13. volatile���η�
��֤�˲�ͬ�̶߳�����������в���ʱ�Ŀɼ��ԡ�����volatile
�ؼ���ʱ������һ��lockǰָ�
Ӧ�ó������߲�������µ�״̬������һ����ȫ������˫���������⣩
14. ˵һ�¼��ֳ���������
�㷨�ͷֱ�ĸ��Ӷȡ�
���� ���ʱ����� ƽ��ʱ�临�Ӷ� �ȶ��� �ռ临�Ӷ�
ð������ O(n2) O(n2) �ȶ� O(1)
�������� O(n2) O(n*log2n) ���ȶ� O(log2n)~O(n)
ѡ������ O(n2) O(n2) �ȶ� O(1)
���������� O(n2) O(n*log2n) ���ȶ� O(n)
�������� O(n2) O(n2) �ȶ� O(1)
������ O(n*log2n) O(n*log2n) ���ȶ� O(1)
15. ����һ����ʽ�洢�ṹ��
˳��洢ʱ����������Ԫ�صĴ�ŵ�ַҲ���ڣ���������ͳһ����Ҫ��
�ڴ��п��ô洢��Ԫ�ĵ�ַ�����������ġ�
�ŵ㣺�洢�ܶȴ�1�����洢�ռ������ʸߡ�
ȱ�㣺�����ɾ��Ԫ��ʱ�����㡣
��ʽ�洢ʱ����������Ԫ�ؿ������ţ�����ռ�洢�ռ�������֣�һ���ִ�Ž��ֵ����һ���ִ�ű�ʾ�����ϵ��ָ��
�ŵ㣺�����ɾ��Ԫ��ʱ�ܷ��㣬ʹ����
ȱ�㣺�洢�ܶ�С��<1�����洢�ռ������ʵ͡�
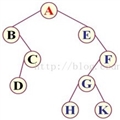
16. ��α���һ�ö�������
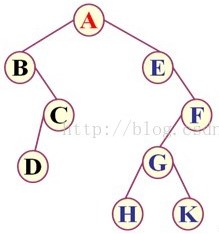
�������������˳�����Ϊ�������ҡ�ABCDEFGHK
�������������˳�����Ϊ������ҡ�BDCAEHGKF
�������������˳�����Ϊ�����Ҹ���DCBHKGFEA
17. ����һ��LinkedList��
Collections.reverse(list);
18. ==��equals������
==��
caozuofu.html" target="_blank">��������equals�Ƿ���
==һ������ԭ�����ͱȽϣ�equalsһ�����ڶ���Ƚ�
���==���ڶ���Ƚϣ��������������õĵ�ַ��ͬʱ����true
19. hashCode����������?
hashCode()������equal()������������ʵһ������java�ﶼ�������Ա����������Ƿ����һ��.��Ϊ��д��equal()��һ��ȽϵıȽ�ȫ��Ƚϸ��ӣ�����Ч�ʾͱȽϵͣ�������hashCode()���жԱȣ���ֻҪ����һ��hashֵ���бȽϾͿ����ˣ�Ч�ʺܸ�.ÿ����Ҫ�Աȵ�ʱ��������hashCode()ȥ�Աȣ����hashCode()��һ�������ʾ����������϶�����ȣ�Ҳ���Dz�������equal()ȥ�ٶԱ��ˣ�,���hashCode()��ͬ����ʱ�ٶԱ�
������equal()�����equal()Ҳ��ͬ�����ʾ�����������������ͬ�ˣ��������ܴ�������Ч��Ҳ��֤�˶Աȵľ�����ȷ�ԣ�
20. ��α�֤HashMap���̰߳�ȫ��
//synchronizedMap ���ʺ�hashTable����
Map<String, String> synchronizedHashMap = Collections.synchronizedMap(new HashMap<String, String>());
//Hashtable ʹ��synchronized����֤�̰߳�ȫ��
Map<String, String> hashtable = new Hashtable<>();
//ConcurrentHashMap
Map<String, String> concurrentHashMap = new ConcurrentHashMap<>();
21. Java��һ���ַ�ռ�����ֽڣ�
���ֽڡ���byte����λ����bit��1 byte = 8 bit��java����unicode����ʾ�ַ�
1�ֽڣ� byte , boolean
2�ֽڣ� short , char
4�ֽڣ� int , float
8�ֽڣ� long , double
22. ����һ������ʵ������Щ������
a) New
b) ���÷����ֶΣ�Java.lang.
class��java.lang.reflect.Constructor���newInstance()
c) ���ö����clone
d) ͨ�������л�ʵ�ֵ���ȿ�¡
23. Session/Cookie������
Session����
����������һ�����ݽṹ�����������û���״̬��������ݿ��Ա����ڼ�Ⱥ�����ݿ⡢�ļ��У�
Cookie�ǿͻ��˱����û���Ϣ��һ�ֻ��ƣ�������¼�û���һЩ��Ϣ��Ҳ��ʵ��Session��һ�ַ�ʽ��
24. String/StringBuffer/StringBuilder������
a) String���ַ�������stringBuffer��StringBuilder���ַ�������
b) ִ���ٶ�Stringbuilder>StringBuffer>String
c) StringBuffer �� StringBuilder �еķ���������ȫ�ǵȼ۵ģ����̳���AbstractStringBuilder�в���һ��char������������Ҫappend���ַ�����char������һ����ʼ��С����append���ַ������ȳ�����ǰchar��������ʱ�����char������ж�̬��չ��ֻ��StringBuffer�еķ���������synchronized�ؼ��ֽ������Σ�������̰߳�ȫ��
�������
1. TCP�������ӵ���������
��һ�����֣��ͻ��˷���syn��(syn=j)����������
�ڶ������֣��������յ�syn��������ȷ�Ͽͻ���SYN��ack=j+1����ͬʱ�Լ�Ҳ����һ��ASK����ask=k����
���������֣��ͻ����յ���������SYN��ACK���������������ȷ�ϰ�ACK(ack=k+1)��
2. TCP�Ͽ����ӵ��Ĵλ���
TCP�ͻ��˷���һ��FIN�������رտͻ��������������ݴ���
�������յ����FIN��������һ��ACK��ȷ�����Ϊ�յ�����ż�1
�������رտͻ��˵����ӣ�����һ��FIN���ͻ���
�ͻ��η���ACK����ȷ�ϣ�����ȷ���������Ϊ�յ���ż�1
3. ���ִ���TIME_WAIT��ԭ��
�������
����TCP
Э�������3�����ֶϿ����ӹ涨,�����ر�
socket��һ��socket������TIME_WAIT״̬,TIME_WAIT״̬������2��MSL(Max Segment Lifetime)�����磬�������������رտͻ��˵�socket���ӣ������·������˴��ڴ�����TIME_WAIT״̬��socket�� TIME_WAIT��TCPЭ�����Ա�֤�����·����socket�����ܵ�֮ǰ�������ӳ��ط�����Ӱ��Ļ���,�DZ�Ҫ������֤��
�������������
�ں�����
vi /etc/sysctl.conf
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_fin_timeout = 30
Ȼ��ִ�� /sbin/sysctl -p �ò�����Ч
net.ipv4.tcp_syncookies = 1 ��ʾ
����SYN Cookies��������SYN�ȴ�
�������ʱ������cookies���������ɷ�������SYN������Ĭ��Ϊ0����ʾ�رգ�
net.ipv4.tcp_tw_reuse = 1 ��ʾ�������á�������TIME-WAIT sockets���������µ�TCP���ӣ�Ĭ��Ϊ0����ʾ�رգ�
net.ipv4.tcp_tw_recycle = 1 ��ʾ����TCP������TIME-WAIT sockets�Ŀ��ٻ��գ�Ĭ��Ϊ0����ʾ�رա�
net.ipv4.tcp_fin_timeout ��ϵ�yĬ�ϵ� TIMEOUT ʱ��
4.
HTTPЭ���ͷ��
a) ͨ��ͷ��
i. Cache-Control��ָ���������Ӧ��ѭ�Ļ�����ƣ������ֵ��no-cache��ָʾ�������Ӧ��Ϣ���ܻ��棻
ii. Connection������ָ�������걾������/��Ӧ�ͻ��˺ͷ������Ƿ�Ҫ�����������ӡ�
iii. Transfer-Encoding������ָ��ʵ�����ݵĴ���
������ʽ��
b) ����ͷ��
i. Accept������ָ���ͻ��˳����ܹ�������MIME���ͣ����ʱ�ö��Ÿ�����
ii. Accept-Encoding��ָ���ͻ��˳���֧�ֵ�ѹ����ʽ��
iii. Accept-Language��ָ���ͻ������������ĸ��������Ե��ĵ���
iv. Accept-Charset��ָ���ͻ��˳������ʹ�õ��ַ�����
v. Host��ָ����Դ���ڵ��������Ͷ˿ںţ�
vi. Referer��ָ������uri��Դ��Դ��ַ��Ҳ�����û����ĸ�uri�������������������ɻ���������
vii. User-Agent��������ͻ�����Ϣ����ʹ������������ȣ�
viii. Cookie��������������������µ���Ϣ����������Ҫ������ͷ�ֶ�֮
c) ��Ӧͷ��
i. Server��˵����Ӧ�����������ƣ���BWS/1.0����Apache/1.3.27��
ii. Location����302��תҳ��Ӧ���ʱ����Locationָ����ת��Ŀ�ĵ�ַ��
iii. Set-Cookie���������������������Cookie
d) ʵ��ͷ��
i. Content-Encoding��ָ��ʵ�����ݲ��õ�ѹ����ʽ��
ii. Content-Length��ָ��ʵ�����ݵij��ȣ���λΪ�ֽڣ�
iii. Content-Type��ָ��ʵ�����ݵ�MIME���ͣ�
iv. Expires��ָ��ʵ��������ʲôʱ��֮����ڣ����ٻ��档
5. HTTPӦ��״̬��
1xx����Ϣ�������յ�������������
2xx���ɹ�����Ϊ���ɹ��ؽ��ܡ�
�����Ͳ��ɣ�
3xx���ض���Ϊ������������һ��ִ�еĶ�����
4xx���ͻ���
���������������������������ʵ�֣�
5xx������˴�������������ȷִ��һ����ȷ������
200 ��ȷ���ؽ��
302
ҳ����ת
304 ҳ��δ�Ķ�
400 �������������
404 ҳ��δ�ҵ�
405 ����������
501 δ��ʹ��
503 ������
6. HTTP��TCP��UDP������
TCP/IP�Ǹ�Э���飬�ɷ�Ϊ������Σ�����㡢������Ӧ�ò㡣
���������IPЭ�顢ICMPЭ�顢
ARPЭ�顢RARPЭ���BOOTPЭ��
�ڴ��������TCPЭ����UDPЭ��
��Ӧ�ò���FTP��HTTP��TELNET��SMTP��DNS��Э��
HttpЭ���ǻ���TCPЭ��ʵ�ֵ�
Socket��Ӧ�ò���TCP/IPЭ����ͨ�ŵ��м���������㣬����һ��ӿڡ�

- ��С: 11.6 KB