???对于MongoDB,面临的最大问题就是如何为应用程序设计出良好的数据模型,大家都是摸着石头过河,意见很难达成一致。最近读了O‘REILLY的一本小册子《50 Tips & Tricks for MongoDB Developers》受益匪浅,所以决定将其中的内容翻译出来。并结合自己实际感受给予评注。
?
?
#第一条 为了速度去重复数据,为了完整性去引用数据(Duplicate data for speed,reference data for integrity)
? ?多个文档中的数据能够被“嵌入”(embed)或是“引用”(reference)。很难说“嵌入”的方式就一定比“引用”好,反之亦然。每种方式都有自己用处,而你应该为你的应用程序去选择合适的方式。
?? “嵌入”会引起数据的“不一致”:假设你想把(图1.1)中的苹果变成梨,如果你更改了其中一个文档中的值,但恰巧在就要更改第二个文档的值之前系统崩溃了,那么你的数据库中对于fruit会出现两个不同的值。
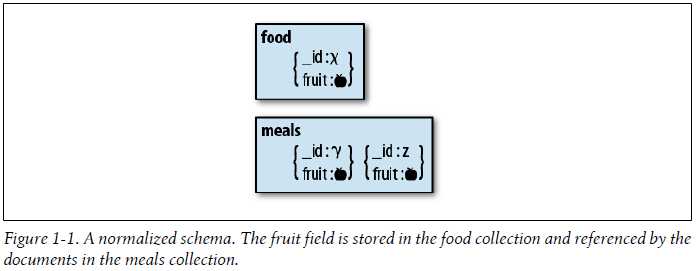
?????????????????????????????????????????????????????????????? 图1.1
?
??? “不一致”并不是件好事,但是“不好”的程度取决于你存储的是什么。在许多应用中,短暂的“不一致”是被允许的:例如某人修改他的用户名,他并不会介意在几个小时内他的旧文章中仍然显示其旧用户名。如果连短期内的不一致都不被允许,这时你需要考虑“引用”了。
???? 然而,如果你“引用”,那么你的应用程序就必须做额外的查询去找出这个水果是什么(图1.2),如果你的应用不能这样的性能打击或是具备稍后将数据一致化的能力,那么你一改使用“嵌入”。

??? 这是一种权衡:你不可能同时具有“最快性能”(fastest performance)和“即刻一致性”(guaranteed immediate
consistency)。你必须去决定哪个对你的应用来说更重要。
?
??? 假设我们在为一个购物车应用设计数据模型。我们的应用将订单存储在MongoDB中,那么一个订单中应该包含什么样的信息呢?
??? “引用”模式:
?
?
A product:
{
"_id" : productId,
"name" : name,
"prise" : price,
"desc" : description
}
An order:
{
"_id" : orderId,
"user" : userInfo,
"items" : [
productId1,
productId2,
productId3
]
}
??? 我们将所定产品的_id存储在[订单]文档的“items”集合中。然后,当我们需要显示订单内容的时候,我们去查询[订单]文档来获取正确的订单,然后通过“items”中的产品_ids去[产品]文档中查询与之相关的每个产品。“引用”模式中,我们没有办法通过单次查询来获取到全部的订单内容。
??? 如果产品信息被更新,所有引用该产品的文档都会跟着“改变”,因为这些文档中存储的仅仅只是产品的引用。
?
??? “嵌入”模式
?
?
A product(和“引用”模式中的相同):
{
"_id" : productId,
"name" : name,
"prise" : price,
"desc" : description
}
An order:
{
"_id" : orderId,
"user" : userInfo,
"items" : [
{
"_id" : productId1,
"name" : name1,
"price" : price1,
"desc" : description1
},
{
"_id" : productId2,
"name" : name2,
"price" : price2,
"desc" : description2
},
{
"_id" : productId3,
"name" : name3,
"price" : price3,
"desc" : description3
}
]
}
?
?? 我们将产品信息当做嵌入到[订单]文档中,然后,当我们要显示订单的时候,只需要做一次查询。
?? 如果一个产品的信息被更新,并且需要将订单中的产品同时更新,我们需要分别去更新每个订过该产品的[订单]文档。“嵌入”使得我们能够更快的读取,但是产品信息不能够在多个文档中被原子性的改变。
?
?? 因此,给出一些选项,帮助你决定使用“引用”还是“嵌入”?
?? 决定因素
?? 有三个主要因素需要考虑:
?? 1.你是否为了很少才会发生一次的数据变化而在每次读取上花费代价。
? ? ? 你也许会去读取一个产品一万次为了它的每一次变化。你是否会愿意每次为了”使一次写入更快或是保证一致性而去做10000次读取”缴纳罚金。大多数的应用程序read-heavy比write-heavy要重要一些:做出你的权衡吧。
?? 2.一致性对你的应用来讲有多重要?
? ? ? 如果你的应用中一致性很重要,你应该采用"引用"模式,例如,我们需要多个文档原子性的看到一次数据变化。?如果我们做的是一个只能在某些时间段内交易某种"有价证券"的交易系统,当"有价证券"不可交易时,我们应该立即对它 ? ?们加"锁"。我们可以将一个加锁的单个文档引用到一组与之相关的[有价证券]文档中。这样做要比在应用程序层面上去加 ? ?锁要好一点。但是无论如何,应用程序需要知道何时去加锁以及何时去解锁。
???3.是否需要快速读取?
如果读取需要尽可能的快,那么应该采用"嵌入"。在实时(Real-time)系统中应该尽可能的使用"嵌入"。