 class="topic_img" alt=""/>
class="topic_img" alt=""/>
�������߰����˹��������������������еļ�����������ѧϰ��ML����Ŀǰ���Ծ�ķ�֧��������꣬ML ȡ����������Ҫ��չ������һЩ��Ϊ�¼������ڹ�ϵ���ж�������Ŀ�����е���Ȼ�͵��������ش�Statsbot һֱ�ڳ����������ѧϰ�ĸ���ɾ͡�ֵ������֮�ʣ��������ŶӾ����Թ�ȥһ�����ѧϰ��ȡ�õijɾͽ����̵㡣���������ݿ�ѧ�� Ed Tyantov ��࣬36Kr ���룬����������˽Ӱ������δ��������Ҫ��չ��
����1. ����
����1. 1. Google ��Ȼ��������
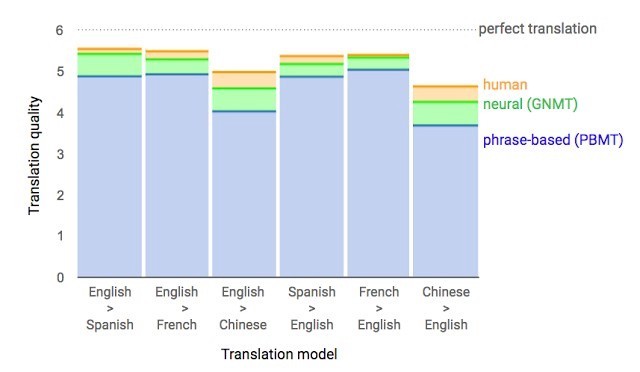
�������� 1 ��ǰ��Google ��������һ���� Google Translate����ҹ�˾���������������ܹ��ݹ������磨RNN����ϸ�������
������ؼ��ɹ��ǣ��������෭��ȷ�ʵIJ����С�� 55%—85%�����˰��� 6 ���ȼ����������������û���� Google �������ô���ģ�����ݼ��Ļ����Ǻ�������һģ���������ý���ġ�
 original="https://pic.36krcnd.com/avatar/201712/28031607/lxdk8szczetqm9nl.jpg!heading" data-image-enhancer="larger than 578" />
original="https://pic.36krcnd.com/avatar/201712/28031607/lxdk8szczetqm9nl.jpg!heading" data-image-enhancer="larger than 578" />
����1. 2. ̸�С��ܷ�ɽ���
���������Ѿ���˵�� Facebook ��������������˹ر��������������ˣ���Ϊ�ǻ�����ʧȥ�˿��Ʋ��ҷ������Լ������ԡ�Facebook �������������˵�Ŀ����Ϊ��Э��̸�У�����һ���������������ϵ�̸�У����ڴ�ɽ��ף�������ô��̯��Ʒ���顢ñ�ȣ���ÿһ��������̸��ʱ�����Լ���Ŀ�꣬���ǶԷ�����֪���Լ���Ŀ�ꡣ���ܴ�ɽ��Ͳ����Ƴ�̸�С�
��������ѵ����Ŀ�ģ������ռ�������̸��Э�̵����ݼ�Ȼ����һ���мල�ĵݹ����������������ѵ�������ţ�������ǿ��ѧϰѵ�������������Լ����Լ��������������������Ը��������ơ�
����������ѧ����һ��������̸�в���——��װ�Խ���ij������չ�ֳ���Ȥ��Ȼ���������ⷽ�������Ӷ����Լ�������Ŀ�����档���Ǵ������ཻ��ʽ�����˵ĵ�һ�γ��ԣ���������൱�ɹ��ġ�
�����������¿ɲμ���ƪ���£����������
������Ȼ��˵��������˷������Լ���������ȫ����ǣǿ�����ˡ���ѵ������ͬһ����������Э��̸�У���ʱ������ȡ���˶����������������Ե����ƣ�Ȼ���㷨�����˽��������ԡ�ûʲô�ر�
������ȥ���꣬�ݹ�����ķ�չһֱ���ܻ�Ծ������Ӧ�õ��˺ܶ�������Ӧ���С�RNN �ļܹ��Ѿ���ø������࣬����һЩ����ǰ������——DSSM Ҳ��ȡ�����ƵĽ�����ȷ�˵����ǰ Google �� LSTM ���ʼ����� Smart Reply ��Ҳ�Ѿ��ﵽ����ͬ�����������⣬Yandex �����ڴ��������Ƴ���һ���µ��������档
����2. ����
����2. 1. WaveNet������Ƶ������ʽģ��
����DeepMind ��Ա���������н�������Ƶ�����ɡ�����˵���о���Ա��֮ǰͼ�����ɣ�PixelRNN �� PixelCNN���Ļ�����������һ���Իع����ȫ���� WaveNet ģ�͡�
���������羭���˶˵��˵�ѵ�����ı���Ϊ���룬��Ƶ����������о�ȡ���˳�ɫ�Ľ������Ϊ������IJ�������� 50%��
���������������Ҫ�������������ͣ������Իع�Ĺ�ϵ�������Ǵ��������ģ�����һ���ӵ���ƵҪ 1 �� 2 ���Ӳ������ɡ�
��������������……Ŷ�Բ������������������
��������㳷��������������ֵ�������ֻ���¶�֮ǰ�������ص�������������������������������Ե����أ�����������Ƶ��û������ġ�
������������������������ӡ�
����ͬһ��ģ�Ͳ�������Ӧ�õ������ϣ�����Ҳ����Ӧ���ڴ������ֵ������ϡ�����һ�������ģ�ͣ���ij��������Ϸ�����ݼ�ѵ����Ҳ��û�������������ݵģ�������Ƶ��
����DeepMind �о��ɹ�����ȫ�������
����2. 2. ��������
����������������һ�����ѧϰ��Խ����ijɾͺ�ʤ����
����Google Deepmind ��ţ���ѧ�����ڡ�������Ȼ���⡷��ƪ�����н��������ǵ�ģ�ͣ�ͨ���������ݼ�ѵ��������γ�Խְҵ������ʦ�ġ�
����������ݼ��ܹ��а��� 100000 �����ӵ�����Ƶ��ģ�ͣ���Ƶ�� LSTM����Ƶ�� CNN+LSTM��������״̬�����ṩ������ LSTM��Ȼ�������ɽ�����ַ�����
����ѵ���������õ��˲�ͬ���͵��������ݣ���Ƶ����Ƶ�Լ�����Ƶ�����仰˵������һ��“������”ģ�͡�
����2. 3. �ϳɰ°���������Ƶ�кϳ��촽����
������ʢ�ٴ�ѧ����һ������Ĺ��������������˰°�����ͳ�Ĵ��ﶯ����֮����Ҫѡ��������Ϊ��������������Ƶ�ܶࣨ17 Сʱ�ĸ�����Ƶ����
�����⿿����������û�а취ȡ�ý�չ�ģ���Ϊ�˹��Ķ���̫�ࡣ��ˣ��������߹�˼��һЩ֧��������У���Ҫ��ϲ����ô˵�Ļ������Ľ�������ʱ����ơ�
��������Կ���������Ǻܾ��ġ��ܿ죬���û��������λ��ͳ����Ƶ�ˡ�
����3. ������Ӿ�
����3. 1. OCR��Google Maps �� Street View���־���
����Google Brain Team �ڲ��ͺ������б������������������һ���µ� OCR����ѧ�ַ�ʶ������� Maps��Ȼ������ʶ��ֵ����ƺ��̵��־��
�����ڼ��������Ĺ����У��ù�˾������һ���µ� FSNS�������ֵ����ƣ�����������кܶิ�ӵ������
����Ϊ��ʶ��ÿһ�����ƣ����������������ƶ��� 4 �ŵ���Ƭ�������� CNN ����ȡ���ڿռ�ע�⣨�������������꣩�İ����½������䣬Ȼ���ٰѽ���� LSTM��
����ͬ���ķ�����Ӧ�õ�ʶ�������ϵ��̵������棨������д�����“����”���ݣ����籾������“��ע”���ʵ�λ�ã�����һ�㷨Ӧ�õ��� 800 ����ͼƬ�ϡ�
����3. 2. �Ӿ�����
������һ���������ͽ����Ӿ������������类Ҫ�����һ����Ƭ���ش����⡣�ȷ�˵��“ͼ����Ƥ���ϵ���Ʒ����ɫ����Բ����������Dz���һ���ģ�”�������ɲ���С���⣬ֱ������������ȷ��Ҳֻ�� 68.5%��
�������� Deepind �Ŷ��ٴ�ȡ����ͻ�ƣ��� CLEVR ���ݼ������Ǵﵽ�� 95.5% ��ȷ�ʣ��������������ࡣ
�����������ļܹ��dz���Ȥ��
��Ԥѵ���õ� LSTM �õ��ı������ϣ����Ǿ͵õ��������Ƕ�롣
���� CNN��ֻ�� 4 �㣩��ͼƬ�ϣ��͵õ���������ͼ������ͼƬ�ص��������
�����������Ƕ�������ͼ�����Ƭ�ν���������ԣ���ͼ�Ļ�ɫ����ɫ����ɫ������ÿһ�������������ı�Ƕ�롣
����ͨ����һ����������������Щ��Ԫ��Ȼ�����������
��������ٵ�һ��ǰ�������������ܣ�Ȼ���ṩ softmax �𰸡�
����3. 3. Pix2Code Ӧ��
����Uizard ��˾������һ����Ȥ��������Ӧ�ã����ݽ���������Ľ������ɲ��ִ��룺
�������Ǽ������õ�һ��������Ӧ�ã����������������������һЩ��������������ȡ���� 77% ��ȷ�ʡ�Ȼ��������Ȼ���о��У���û�����۹�������ʹ�������
�������ǻ�û�п�Դ����������ݼ������dz�ŵ���ϴ���
����3. 4. SketchRNN���̻�������
���������Ѿ����� Google �� Quick, Draw!�ˣ���Ŀ������ 20 ��֮�ڻ������ֶ���IJ�ͼ����ҹ�˾�ռ���������ݼ��Ա����������续�������� Google �����ǵIJ��ͺ���������˵������
����������ݼ������� 7 �������裬Google �����Ѿ����Ÿ������ˡ����費��ͼƬ�����ǻ�����ϸ��������ʾ���û�����“Ǧ��”����������ʱ�ͷ�����¼�Ķ�������
�����о���Ա�Ѿ��� RNN ��Ϊ����/���������ѵ�������е����еı��Ա�������Sequence-to-Sequence Variational Autoencoder����
�������գ���Ϊ�Ա�����Ӧ��֮�壬��ģ�ͽ��õ�һ������ԭʼͼƬ�ص������������
�������ڸý��������Դ���һ������ȡ��һ��ͼ��������Ըı������ҵõ��µ����衣
��������������������������һֻè����
����3. 5. GAN�����ɶԿ����磩
�������ɶԿ����磨GAN�������ѧϰ�����ŵĻ���֮һ���ܶ�ʱ������뷨��������ͼ���棬�����һ���ͼ����������һ���
�������뷨��������������——��������������������ϡ���һ�����紴��ͼ��Ȼ��Զ���������ͼ�����ͼ������ʵ�Ļ������ɵġ�
������ͼʾ�����ʹ���������ģ�
������ѵ���ڼ䣬������ͨ���������������������һ��ͼ��Ȼ�������������룬�ɺ���˵��������Ļ��Ǽٵġ���������������������ݼ�����ʵͼ��
����ѵ�������Ľṹ�Ǻ��ѵģ���Ϊ�ҵ����������ƽ�����ѡ�ͨ������¼��������ʤ��Ȼ��ѵ����ͣ�Ͳ�ǰ�ˡ�Ȼ������ϵͳ�������������ǿ��Խ����������˵����������ʧ���������⣨�ȷ�˵�Ľ�ͼƬ������——�������⽻������������ʡ�
����GAN ѵ������ĵ�����������������˵�ͼƬ
������ǰ���������۹���ԭʼ���ݱ���Ϊ������ʾ���Ա��루Sketch-RNN����ͬ��������Ҳ�������������ϡ�
����������������ͼ����뷨�����������Ϊ������Ŀ http://carpedm20.github.io/faces/�еõ�������չʾ������Ըı�������������������α仯�ġ�
������ͬ���㷨Ҳ������DZ�ڿռ䣺“һ�����۾�����”��ȥ“һ����”����һ��“Ů��”�൱��“һ�����۾���Ů��”��
����3. 6. �� GAN �ı���������
���������ѵ����������ѿ��Ʋ�������DZ����������ô������DZ������ʱ����Ϳ��Ը������Ӷ�����ͼƬ�й�����Ҫ��ͼ�����ַ�������Ϊ������ GAN��
�����������������ɶԿ���������沿�ϻ�����ƪ���µ����߾�����ô�ɵġ����� IMDB ���ݼ�����֪�������Ա��������й�ѵ��֮���о���Ա���л������ı���˵��沿���䡣
����3. 7. רҵ��Ƭ
����Google �Ѿ�Ϊ GAN �ҵ�����һ����Ȥ��Ӧ��——ѡ�������Ƭ��������רҵ��Ƭ���ݼ���ѵ�� GAN����������ͼ�Ľ�������Ƭ������רҵ����Ȼ��������������ӻ���������������Ҫ����“�Ľ���”����Ƭ��������רҵ��Ƭ��
��������ѵ�����㷨��ɸ�� Google Street View ��ȫ����Ƭ��ѡ��������õ���Ʒ�������յ�һЩרҵ�Ͱ�רҵƷ�ʵ���Ƭ��������Ӱʦ��������
����3. 8. ͨ�����������ϳ�ͼ��
����GAN ��һ������ӡ����̵�����������������ͼ��
���������о��������������������Ƕ�뵽�������������� GAN�������룬ͬʱҲǶ�뵽�����������룬�����Ϳ�����֤������ͼ�������ԡ�Ϊ��ȷ��������ѧ���������ĺ���������ѵ�����⣬���ǻ�����ʵͼ�������˲���ȷ�����֡�
����3. 9. Pix2pix Ӧ��
����2016 ��������Ŀ������֮һ�� Berkeley AI Research ��BAIR���ġ����������Կ��������ͼ��ͼ��ķ��롷���о���Ա�����ͼ��ͼ�����ɵ����⣬�ȷ�˵��Ҫ������һ������ͼ����һ����ͼʱ�����߸������������������ʵ������
�������ﻹ��һ�������� GAN �ɹ����ֵ����ӡ���������£�������������ͼƬ����ͼ��ָ��к����е� UNet �������������ļܹ���һ���µ� PatchGAN �������������������Կ�ģ��ͼ��ͼƬ���ֳ�N�飬ÿһ�鶼�ֱ������α��Ԥ�⣩��
����Christopher Hesse �����˿��µ�è�����������û��������Ȥ��
����������������ҵ�Դ���롣
����3. 10. CycleGAN ͼ��������
����Ҫ��Ӧ�� Pix2Pix������Ҫһ���������Բ�ͬ����ͼƬƥ��Ե����ݼ����ȷ�˵�ڿ�Ƭ������£��ռ��������ݼ����������⡣Ȼ���������ϣ����������ӵĶ���������Զ������“����”���߷��һ����Ծ��Ҳ�������ƥ�䌝�ˡ�
������ˣ�Pix2Pix �����߾��������Լ����뷨����������� CycleGAN����û���ض���Ե�������Բ�ͬ�����ͼ�����ת��——������Ե�ͼ��ͼ���롷
�������뷨�ǽ�����������—��������ͼ���һ������ת��Ϊ��һ������Ȼ���ٷ�����������������Ҫһ��ѭ����һ����——����һϵ�е�������Ӧ��֮������Ӧ�õõ�����ԭ�� L1 ����ʧ��ͼ��Ϊ��ȷ�����������Ὣһ�������ͼ��ת������һ����ԭ��ͼ�����ϵ�������ͼ����Ҫ��һ��ѭ����ʧ��
�������ְ취�������ѧϰ��—>������ӳ�䡣
��������ת����̫�ȶ��������ᴴ������ɹ���ѡ�
����Դ����Ե������ҡ�
����3. 11. ��������ѧ�Ľ�չ
��������ѧϰ�����Ѿ��߽���ҽ��ҵ������ʶ��������MRI �Լ�����������⣬�����������������Կ���֢��ҩ�
���������Ѿ���������һ�о���ϸ�ڡ�����˵���ڶԿ��Ա�������AAE���İ����£������ѧϰ���ӵ�DZ�ڱ���Ȼ��������Ѱ���µķ��ӡ�ͨ�����ַ�ʽ�Ѿ��ҵ��� 69 �ַ��ӣ�����һ�������ڶԿ���֢�ģ�������Ҳ�����ش�DZ�ܡ�
����3. 12. �Կ�����
�����Կ���������Ļ���̽�ֵú����ҡ�ʲô�ǶԿ��������ȷ�˵������ ImageNet ѵ���ı����磬�����������������ѷ����ͼƬ֮����ȫ�Dz��ȶ��ġ���������������У����ǿ����������۾�����������ͼƬ�������Dz���ģ�����ģ����ȫ�����ˣ�Ԥ�������ȫ��ͬ�����
����Fast Gradient Sign Method��FGSM�������ݶȷ��ŷ�������ʵ�����ȶ��ԣ��������˸�ģ�͵IJ���֮������Գ�����Ҫ�����ǰ��һ�������ݶȲ�Ȼ��ı�ԭʼͼƬ��
����Kaggle ������֮һ����йأ������߱�����ȥ����ͨ�õĹ�����ϵ�����ջ���Կ���ȷ����õġ�
����Ϊʲô����Ҫ�о���Щ���������ȣ��������ϣ�������Լ��IJ�Ʒ�Ļ������ǿ������������� captcha ����ֹ spammer������Ⱥ���ߣ����Զ�ʶ����Σ��㷨�������������ǵ������——�����沿ʶ��ϵͳ���Զ���ʻ�����������ӡ���������£�������������Щ�㷨��ȱ�ݡ�
�����������һ�����ӣ�ͨ�����ⲣ���������ƭ�沿ʶ��ϵͳ��Ȼ��“���Լ������һ���˶����ͨ��”����ˣ���ѵ��ģ�͵�ʱ��������Ҫ���ǿ��ܵĹ�����
��������Ա�ʶ�IJ���Ҳ�����˶������ȷʶ��
�������������Ծ�����֯�ߵ�һ�����¡�
�����Ѿ�д�õ����ڹ����Ŀ⣺cleverhans �� foolbox��
����4. ǿ��ѧϰ
����ǿ��ѧϰ��RL��Ҳ�ǻ���ѧϰ����Ȥ��չ���Ծ�ķ�֧֮һ��
�������ְ취�ľ�������һ��ͨ��������轱���Ļ�����ѧϰ�����ijɹ���Ϊ——������һ����ѧϰһ����
����RL ����Ϸ���������Լ�ϵͳ���������罻ͨ����ʹ�û�Ծ��
������Ȼ��ÿ���˶���˵�� Alphago �����������Χ��ѡ�ֵı�����ȡ�õ�ʤ�����о���Ա��ѵ����ʹ���� RL�������˸����Լ��������Ľ����ԡ�
����4. 1. ���ܿظ��������ǿ��ѵ��
����ǰ���� DeepMind �Ѿ�ѧ������ DQN ������͵��棬�����Ѿ����������ࡣĿǰ���������ڽ��㷨������ Doom ���������ӵ���Ϸ��
����������ע���ŵ���ѧϰ�������棬��Ϊ�����������Ľ���������Ҫ�ִ� GPU �ܶ�Сʱ��ѵ����
����DeepMind �ڲ��� https://deepmind.com/blog/reinforcement-learning-unsupervised-auxiliary-tasks/�б���˵������ʧ�������������룬����Ԥ��ijһ֡�ı仯�����ؿ��ƣ�һ�ߴ������õ������ж��ĺ�������������ӿ�ѧϰ���ٶȡ�
����4. 2. ѧϰ������
������ OpenAi������һֱ�ڻ����о�������������¶Դ�����ѵ������Ҫ������ʵ�����н���ʵ�����ȫ��
�������ǵ��Ŷ�������һ���о�����ʾ��һ���Ե�ѧϰ���п��ܵģ�һ������ VR ����ʾ���ִ���ض������������һ����ʾ�����Թ��㷨ѧ��Ȼ������ʵ���������֡�
��������̻���Ҳ��ô�ͺ��ˡ�
����4. 3. ��������ƫ�õ�ѧϰ
���������� OpenAi �� DeepMind ���϶Ը�����չ���Ĺ����������Ͼ��Ǵ����и������㷨�ṩ�����ֿ��ܵĽ����������Ȼ��ָ����һ�����á�������̻�Ϸ�����Ȼ���ȡ���� 900 ����λ��������������ǣ����㷨��ѧ������ν��������⡣
����������һ�����������С�ģ�Ҫ����������̸���������ʲô���ȷ�˵��������ȷ���㷨�����Ҫ���Ǹ�����������ʵ��ֻ��ģ�������������
����4. 4. ���ӻ����µ��˶�
����������һ������ DeepMind ���о���Ϊ�˽̻����˸��ӵ���Ϊ����·����Ծ�ȣ��������������˵Ķ�������ô������뵽��ʧ������ѡ���ϣ���������Ҫ����Ϊ��Ȼ�����㷨ѧϰͨ������ѧϰ������Ϊ�����һЩ��
�����о���Ա�跨ʵ������һ�㣺����ͨ���һ�����ϰ��ĸ��ӻ��������ṩһ���Ļر����������˶��еĴ������̴���������ģ������ִ�и��Ӷ�����
��������Թۿ������Ƶ���������ӡ����̡�Ȼ�����õ��������ۿ�����Ȥ�ö࣡
������������ṩһ������������㷨���ӣ����� OpenAI ��������ѧϰ RL �ġ����������ʹ�ñȱ��� DQN ���Ƚ��Ľ�������ˡ�
����5. ����
����5. 1. ��ȴ��������
����2017 �� 7 �£�Google ������������� DeepMind �ڻ���ѧϰ����ijɹ��������������ĵ��ܺġ�
������������������ǧ������������Ϣ��Google ������ѵ����һ�������磬һ����Ԥ���������ĵ� PUE����Դʹ��Ч�ʣ���ͬʱ���и���Ч���������Ĺ��������� ML ʵ��Ӧ����һ������ӡ����̵���Ҫ���ӡ�
����5. 2. �������������ģ��
����������֪����������ѵ������ģ���Ƿdz�ר�Ż��ģ�ÿһ���������������ģ��ѵ�������Ѵ�һ������ת����ִ����һ�������� Google Brain ��ģ�͵������Է���������һС������ѧϰһ�еĵ�һģ�͡�
�����о���Ա�Ѿ�ѵ����һ��ģ����ִ�� 8 �ֲ�ͬ�����ı���������ͼ�����ȷ�˵�����벻ͬ�����ԣ��ı��������Լ�ͼ��������ʶ��
����Ϊ��ʵ����һ�㣬���ǿ�����һ�����ӵ�����ܹ��������в�ͬ�Ŀ鴦����ͬ����������Ȼ���������������ڱ���/�������Щ��ֳ��� 3 �����ͣ�������ע�����Լ��ſ�ר�һ�ϣ�MoE����
����ѧϰ����Ҫ�����
�õ��˼���������ģ�ͣ����߲�δ�Գ�����������������
��ͬ������֪ʶ������ת����Ҳ����˵��������Ҫ�������ݵ������ּ�����һ���ġ�������С�����ϱ��ָ��ã��ȷ�˵��������
��ͬ������Ҫ�Ŀ鲢���������������ʱ���������������磬MoE——�� Imagenet ������а�����
����˳��˵һ�£����ģ�ͷŵ��� tensor2tensor ���档
����5. 3. һСʱŪ�� Imagenet
����Facebook ��Ա����һƪ�����и������ǣ����ǵĹ���ʦ������ڽ���һ��Сʱ֮�ڽ̻� Resnet-50 ģ��Ū�� Imagenet �ġ�Ҫ˵������ǣ��������� 256 �� GPU��Tesla P100����
�������������� Gloo �� Caffe2 ���зֲ�ʽѧϰ��Ϊ����������̸�Ч�����ô�������8192 ��Ҫ�أ���ѧϰ�����DZ�Ҫ�ģ��ݶ�ƽ���������Ρ�����ѧϰ�ʵȡ�
������ˣ��� 8 �� GPU ��չ�� 256 �� GPU ʱ��ʵ�� 90% ��Ч�����п��ܵġ�����û�����ּ�Ⱥ����ͨ�ˣ����� Facebook ���о���Աʵ���������Ը��졣
����6. ����
����6. 1. ���˳�
�������˳����з����Ȼ��죬���ֳ����ڻ����ؽ��в��ԡ�������꣬���������Ӣ�ض��չ��� Mobileye��Uber �� Google ֮�䷢����ǰԱ����ȡ�����ij��ţ��Լ������Զ��������µĵ�һ�������¼��ȵȡ�
��������ǿ��һ�����飺Google Waymo �����Ƴ�һ�� beta �ƻ���Google �Ǹ����������������Ϊ�Լ��ļ����Ƿdz��õģ���Ϊ���ij��Ѿ���ʻ�� 300 ����Ӣ�
����������˳���������������ȫ����ʻ�ˡ�
����6. 2. ҽ�Ʊ���
����������˵���������ִ� ML ����ʼ���뵽ҽ����ҵ���С��ȷ�˵��Google ��һ��ҽ�����ĺ������������߽�����ϡ�
����Deepmind ������������һ�������IJ��š�
�������� Kaggle �Ƴ��� Data Science Bowl �ƻ�������һ��Ԥ��һ��ΰ�����ľ�����ѡ���ǵ�������һ����ϸ��ͼƬ������ظߴ� 100 ����Ԫ��
����6. 3 Ͷ��
����Ŀǰ��ML �����Ͷ�ʷdz�����֮ǰ�ڴ����ݷ����Ͷ��һ����
�����й��� AI �����Ͷ��ߴ� 1500 ����Ԫ�����ڳ�Ϊ�����ҵ�����䡣
������˾���棬�ٶ��о�Ժ������ 1300 �ˣ����֮�� FAIR ���� 80 �ˡ�������� KDD �ϣ������Ա�����������ǵIJ���������������KunPeng���������ܵ������� 1000 �ڣ��� 1 ���ڸ���������Щ����“��ͨ����”��
��������Եó��Լ��Ľ��ۣ�ѧϰ����ѧϰ��Զ����١���·��Σ�����ʱ��ת�ƣ����п����߶���ʹ�û���ѧϰ��ʹ�ú��߱����ͨ����֮һ�������������ݿ��ʹ������һ����
����ԭ�����ӣ�https://blog.statsbot.co/deep-learning-achievements-4c563e034257
�����������Ʒ���༭�������̡�








