ǰ�ڹ���
- ͳ��Ӧ�����ݣ���ֵTPS��ƽ��TPS��ÿ��ƽ�������ڴ���С��ÿ�������ƽ�������ڴ��С��
- ͳ��GC���䡢�����ڴ�����ݣ�MinorGC��FullGCͣ��ʱ����ƽ���ʱ�䴥��һ��GC��ÿ��Eden->Old��ƽ��������С�ȣ�
- �ѹ�����Ի���
- ģ��������ʵ�û���Ϊ����Ӧѹ������¼�û����ʵ�accesslog��Ϊѹ������Դ��ʹ�õ�ѹ����������Ϊhttp_load��httperf��
��һ������
- ����ʹ��JDK7��G1���գ��ڰ�װGDK7ʱʧ�ܣ�ԭ���Dz���ϵͳ�汾������RedHat 5.5+/CentOS 5.5+(http://www.oracle.com/technetwork/java/javase/config-417990.html#os) ��ʱ������������ϵͳ�����Է���JDK7 G1��
- ��Ϊʹ��JDK6 Update26�汾��G1���ա�����������ʱ��Ϊ40ms��ͨ��12Сʱ�Ĺ۲죬�����д�����ʱ���о�G1��JDK6�ϻ��������죬���Ծ�����ʱ����G1����ΪParallelGC��
- ʹ��ParallelGC��ѹ�����Է���ÿ��MinorGC�ĺ�ʱ���͵�40ms���ң���ǰ��200ms���ϣ�����ÿ��3Сʱ�ͻ���һ��FullGC������ÿ��FullGC��ʱ3~4�롣
- ����FullGC��ɵ�Ӧ����ͣ�����Ӧ�����Dz��ܽ��ܵġ����Է���ParallelGC����Ϊʹ��CMSGC��
�ڶ��ֵ���
- �۲�gcutil����PermSpace�ӽ�100%�����Ե���PermSize��MaxPermSize��
- ����-Xms��-Xmx��ȣ����XmsС��Xmx����Ӧ������������������Խ�С���ᵼ��CMS GC����Ƶ����
- �����Ż�ÿ��ParNew��ʱ�����Ż�ǰÿ����200ms���ϣ������ӡ�-XX:+PrintTenuringDistribution�������۲�gc.log�����ֶ�����SurvivorSpace�е�age���࣬�ᵼ�´����϶�����������������������������JVM��ParNewGCʱ������Щ�϶�������ù�ϵ�Ƿdz���ʱ�ġ��۲�MaxTenuringThreshold��TargetSurvivorRatio���õĹ������Խ�MaxTenuringThresholdֵ��СΪ15���ﵽ�Ż�Ŀ�ģ��Ż���ÿ��ParNew��20~40ms֮�䣩������Ϊ�����SurvivorSpace�������ʣ���TargetSurvivorRatio����Ϊ100������ǿ��GC�رն�̬����MaxTenuringThreshold�����ο���http://blog.bluedavy.com/?p=70
- �����Ż�ParNew֮��ļ��ʱ�䣨�Ż�ǰ3~4��һ�Σ����۲�gc.log����ÿ��ParNew���Լ�в���780MB�Ĵ�������ϣ����Щ����������SurvivorSpace�����ͬʱ��Ҫ��֤ParNew��ʱ������������Xmx��SurvivorRatio���������£���Xmn����7800MB������ΪSurvivorRatio=8����������EdenSpace��Ҫ780*10=7800MB��
- �ٴι۲��Ż����GC�����gcutil�����������ڴ���������EdenSpace����������OldGen�Ľ������ʼ��ͣ�0.01%~0.02%�������Կ��Կ�������CMSInitiatingOccupancyFraction�����OldGen�������ʣ�����CMS GC�Ĵ���Ƶ�ʣ�����80%����
- ȥ��CMSFullGCsBeforeCompaction��ȥ����Ĭ��Ϊ0����ʾÿ��FullGC�����ѹ����Ƭ����������ΪCMS GC���µ��ڴ���Ƭ�������������OldGen�������ʻή�͡�
�����ֵ���
��Ӫһ��ʱ�����CMSGC����һ�������dz��ࣨͼ�м�ͷָ��

����gc��־��
����446600.708: [CMS-concurrent-preclean-start]
446600.788: [CMS-concurrent-preclean: 0.072/0.080 secs] [Times: user=0.60 sys=0.03, real=0.08 secs]
446600.788: [CMS-concurrent-abortable-preclean-start]
446603.594: [GC 446603.594: [ParNew: 6447479K->65869K(7188480K), 0.0634720 secs] 10708889K->4328064K(12513280K), 0.0638340 secs] [Times: user=0.42 sys=0.01, real=0.06 secs]
446605.980: [CMS-concurrent-abortable-preclean: 5.107/5.192 secs] [Times: user=34.46 sys=2.73, real=5.19 secs]
446605.982: [GC[YG occupancy: 4313641 K (7188480 K)]446605.982: [Res
can (parallel) , 1.5739870 secs]446607.556: [weak refs processing, 0.0172470 secs] [1 CMS-remark: 4262195K(5324800K)] 8575836K(12513280K), 1.5920360 secs] [Times: user=12.46 sys=0.05, real=1.59 secs]
���Կ�������remark�е�Rescan�κķ���1.57�룬������������ǻᵼ��Ӧ����ͣ�ġ����ⶨλ����Rescan�Ρ�
������Rescanʱ����������4313641 K (7188480 K)�����ǵ���Rescan���Ĺؼ�ԭ������ܾ���������������С��ʱ�����ֹpreclean�Σ��Ϳ��Կ���ס��Rescanʱ�������Ĵ�С���鿴JVM��������-XX:CMSScheduleRemarkEdenPenetration����˼�ǵ�������������ռEdenSpace�ı�����������ʱ����ֹpreclean�β�����remark�Ρ����������Ĭ��ֵ��50%���������ڵ����ã�����7800m*50%=3900m���ң����Ը��Ĵ˲�������Ϊ��
����-XX:CMSScheduleRemarkEdenPenetration=1
����ѹ�����ԣ�����remark�εĺ�ʱȷʵ�����˲��٣�˵���Ż���Ч��
�����ֵ���
���м����۲�gc��־��2011-09-05��������ÿ��100000���CMSGC�ķ�ֵ���ȷʵ����ˣ����ǻ���ż���г���1~2���CMSGC�����
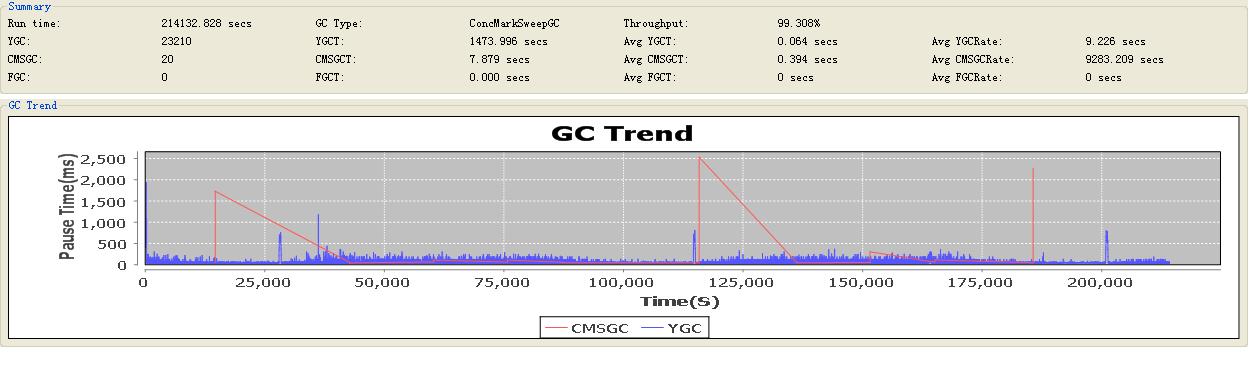
����GC��־:
����
115810.496: [GC 115810.496: [ParNew: 6429866K->40505K(7188480K), 0.0417220 secs] 10689519K->4301475K(12513280K), 0.0419300 secs] [Times: user=0.28 sys=0.00, real=0.04 secs]
115810.539: [GC [1 CMS-initial-mark: 4260969K(5324800K)] 4301537K(12513280K), 0.0501400 secs] [Times: user=0.05 sys=0.00, real=0.05 secs]
115810.589: [CMS-concurrent-mark-start]
115811.859: [CMS-concurrent-mark: 1.270/1.270 secs] [Times: user=7.67 sys=0.32, real=1.27 secs]
115811.859: [CMS-concurrent-preclean-start]
115811.888: [CMS-concurrent-preclean: 0.028/0.029 secs] [Times: user=0.09 sys=0.00, real=0.03 secs]
115811.889: [CMS-concurrent-abortable-preclean-start]
CMS: abort preclean due to time 115821.992: [CMS-concurrent-abortable-preclean: 10.082/10.104 secs] [Times: user=19.25 sys=1.66, real=10.10 secs]
115821.994: [GC[YG occupancy: 4298926 K (7188480 K)]115821.994: [Rescan (parallel) , 2.5039100 secs]115824.498: [weak refs processing, 0.0283980 secs] [1 CMS-remark: 4260969K(5324800K)] 8559896K(12513280K), 2.5327520 secs] [Times: user=19.77 sys=0.13, real=2.53 secs]
115824.527: [CMS-concurrent-sweep-start]
115827.733: [GC 115827.733: [ParNew: 6430265K->61593K(7188480K), 0.0522130 secs] 9504296K->3136946K(12513280K), 0.0525360 secs] [Times: user=0.34 sys=0.00, real=0.05 secs]
����concurrent-abortable-preclean�γ�����-XX:CMSMaxAbortablePrecleanTime���õ����ֵ10�룬����ǿ����ֹ��preclean�ζ�����remark�Ρ������ʱ�������ParNew֮��ļ����17��֮�ࡣϣ��������preclean�β���һ��MinorGC�����Խ�preclean�����ʱ������Ϊ30�룺
����-XX:CMSMaxAbortablePrecleanTime=30000
�����ֵ���
����һ��ʱ����־�Ȼ������FullGC�������3~5�����ҳ���һ�Σ�������FullGCʱ����־��
����443299.787: [GC 443299.787: [ParNew: 6438755K->59103K(7188480K), 0.0645650 secs] 10305335K->3927053K(12513280K), 0.0648090 secs] [Times: user=0.42 sys=0.01, real=0.07 secs]
43305.129: [GC 443305.129: [ParNew: 6448863K->50788K(7188480K), 0.0652490 secs] 10316813K->3919611K(12513280K), 0.0654960 secs] [Times: user=0.43 sys=0.00, real=0.07 secs]
443310.292: [GC 443310.292: [ParNew (promotion
failed): 6440548K->6451166K(7188480K), 2.0562820 secs]443312.348: [CMS: 3871691K->1352176K(5324800K), 17.0114770 secs] 10309371K->1352176K(12513280K), [CMS Perm : 86559K->53644K(131072K)], 19.0681060 secs] [Times: user=17.52 sys=0.04, real=19.07 secs]
443357.642: [GC 443357.642: [ParNew: 6389760K->49312K(7188480K), 0.1196360 secs] 7741936K->1401489K(12513280K), 0.1198690 secs] [Times: user=0.80 sys=0.01, real=0.12 secs]
443362.586: [GC 443362.586: [ParNew: 6439072K->52114K(7188480K), 0.0622160 secs] 7791249K->1404290K(12513280K), 0.0624640 secs] [Times: user=0.43 sys=0.01, real=0.06 secs]
������443310����promotion failed���֣��������������������ռ䲻�㵼�µ�FullGC�������Ǵ�ʱ��OldGen���������ʣ1.45G�Ŀռ䣨5324800K-3871691K=1453109K����������gcLogViewer��ͳ�ƣ�ÿ��MinorGC��ƽ�����������������������ڴ��С��Ϊ58K�����Բ�����OldGen�ռ䲻��������OldGen�������ռ䲻����ɵ�promotion failed��
���仰˵��������OldGen�ھ����ϴ�CMSGC���ֲ����˴����ڴ���Ƭ����ij��ʱ�����OldGen�е������ռ�û��һ���㹻58K�Ļ����ͻᵼ�µ�promotion failed��������Sun�����������˵����
����Sometimes we see these promotion failures even when the
logs show that there is enough free space in tenured generation. The reason is 'fragmentation' - the free space available in tenured generation is not contiguous, and promotions from young generation require a contiguous free block to be available in tenured generation. CMS collector is a non-compacting collector, so can cause fragmentation of space for some type of applications. In his blog, Jon talks in detail on how to deal with this fragmentation problem:
http://blogs.oracle.com/roller-ui/bsc/spider.jsp?entry=c885fd8e0927816c010927b86d0c0603
���߲ο��ҵ���һƪblog��http://blueswind8306.iteye.com/admin/blogs/1194773
��������ܹ�����CMSGC�����ڣ���֤�ڳ���promotion failed֮ǰ�ͽ���CMSGC���Ϳ��Ա�����������ˡ����Կ��ǽ��������ռ���С�������˵���������������Ŀռ䣩�����ҽ�CMSGC�������ʽ��ͣ�ͬʱ��֤Survivor�ռ䲻�䡣�����Ż������Ķ����£�
����-Xmn7800m -> -Xmn7020m
-XX:SurvivorRatio=8 �C> -XX:SurvivorRatio=7
-XX:CMSInitiatingOccupancyFraction=80 -> -XX:CMSInitiatingOccupancyFraction=70
�Ż�����������
����
<jvm-arg>-Xmx13000m</jvm-arg>
<jvm-arg>-Xms13000m</jvm-arg>
<jvm-arg>-Xmn7020m</jvm-arg>
<jvm-arg>-Xss256k</jvm-arg>
<jvm-arg>-XX:PermSize=64m</jvm-arg>
<jvm-arg>-XX:MaxPermSize=128m</jvm-arg>
<jvm-arg>-XX:ParallelGCThreads=20</jvm-arg>
<jvm-arg>-XX:+UseConcMarkSweepGC</jvm-arg>
<jvm-arg>-XX:+UseParNewGC</jvm-arg>
<jvm-arg>-XX:SurvivorRatio=7</jvm-arg>
<jvm-arg>-XX:TargetSurvivorRatio=100</jvm-arg>
<jvm-arg>-XX:MaxTenuringThreshold=15</jvm-arg>
<jvm-arg>-XX:CMSInitiatingOccupancyFraction=70</jvm-arg>
<jvm-arg>-XX:SoftRefLRUPolicyMSPerMB=0</jvm-arg>
<jvm-arg>-XX:+UseCMSCompactAtFullCollection</jvm-arg>
<jvm-arg>-XX:CMSMaxAbortablePrecleanTime=30000</jvm-arg>
<jvm-arg>-XX:CMSScheduleRemarkEdenPenetration=1</jvm-arg>
<jvm-arg>-server</jvm-arg>
<jvm-arg>-XX:+PrintGCDetails</jvm-arg>
<jvm-arg>-XX:+PrintGCDateStamps</jvm-arg>
<jvm-arg>-Xloggc:./log/gc.log</jvm-arg>
�����
- http://my.oschina.net/shootercn/blog/15393
- http://blog.bluedavy.com/?p=200
- http://blog.bluedavy.com/?p=70
- http://blog.bluedavy.com/?p=45
- http://blogs.oracle.com/poonam/entry/understanding_cms_gc_logs
- http://java.sun.com/j2se/reference/whitepapers/memorymanagement_whitepaper.pdf
- Java 6 JVM����ѡ���ȫ�����İ棩
- ���ֲ�ʽJavaӦ�� ������ʵ����





