class="topic_img" alt=""/>
class="topic_img" alt=""/>
��������Դ�� MMLSpark���������� Apache Spark �ĵ����ѧϰ�⡣MMLSpark ����������֪���߰��� OpenCV �������ϡ�
��������������Ȼ SparkML ���Խ�������չ�Ļ���ѧϰƽ̨��������������ߵľ����������˵��õײ� API �ϡ�MMLSpark ּ�ڼ� PySpark �е��ظ��Թ�����
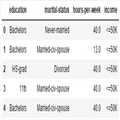
������ UCI �ij��������ղ����ݼ�������ʹ��������ĿԤ�����룺

�������ֱ��ʹ�� SparkML��ÿһ�ж���Ҫ��������������Ϊ��ȷ���������ͣ��� MMLSpark ��ֻ��Ҫ���д��룺
model = mmlspark.TrainClassifier (model=LogisticRegression ()�� labelCol=” income”) .fit (trainData) predictions = model.transform (testData)
������������磨DNN����ͼ��ʶ�������ʶ��������ѷ�����࣬���� DNN ģ�͵�ѵ����Ҫרҵ��Ա���ɽ��У��� SparkML ������Ҳʮ�ֲ��ס�MMLSpark �ṩ�˷���� Python API�����Է����ѵ�� DNN �㷨��MMLSpark ���Է����ʹ������ģ�ͽ��з��������ڷֲ�ʽ GPU �ڵ��Ͻ���ѵ�����Լ�ʹ�� OpenCV ��������չ��ͼ�������ߡ�
�������� 3 �д�����Դ�����֪�����г�ʼ��һ�� DNN ģ�ͣ���ͼ���г�ȡ������
cntkModel = CNTKModel () .setInputCol (“images”) .setOutputCol (“features”) .setModelLocation (resnetModel) .setOutputNode (“z.x”) featurizedImages = cntkModel.transform (imagesWithLabels) .select ([‘labels’��’features’]) model = TrainClassifier (model=LogisticRegression (),labelCol=”labels”) .fit (featurizedImages)
����MMLSpark �Ѿ������� Docker Hub �ϣ�ʹ�������������ڵ�������
docker run -it -p 8888:8888 -e ACCEPT_EULA=yes microsoft/mmlspark
�����鿴Ӣ��ԭ�ģ�
����https://github.com/Azure/mmlspark
����https://blogs.technet.microsoft.com/machinelearning/2017/06/07/announcing-microsoft-machine-learning-library-for-apache-spark/