《聊聊synchronized为什么无法锁住Integer》
?
假设并发环境下,业务代码中存在一些统计操作,为了保证线程安全,开发人员往往会对计数值进行加锁(synchronized),值得注意的是,直接对Integer类型进行加锁,似乎并不会达到预期效果,比如下面这段代码:
Integer num?= new?Integer(0);
public?void?test() throws?InterruptedException {
final?int?THREAD_SIZE?= 10;
final?int?TASK_SIZE?= 100000;
final?CountDownLatch latch?= new?CountDownLatch(THREAD_SIZE);
for?(int?i?= 0; i?< THREAD_SIZE; i++) {
new?Thread() {
public?void?run() {
for?(int?j?= 0; j?< TASK_SIZE?/ THREAD_SIZE; j++) {
synchronized?(num) {
num++;
}
}
latch.countDown();
}
}.start();
}
latch.await();
System.out.println("num-->"?+ num);
}
?
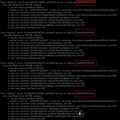
上述代码示例中,总共有10个线程运行,每个线程执行次数为10000(taskSize/threadSize),但是实际程序输出结果却并非是10W次,或许有些同学会觉得诧异,在对计数值num(Integer)进行递增操作前,已经执行了加锁操作,为啥还是非线程安全。我们首先来看一下上述程序的线程堆栈信息:
?
?
上图中,每一个线程锁住的资源其实都并非是同一个,这就可以解释为什么对Integer类型进行加锁仍然是非线程安全的。
?
或许有同学会说,JavaAPI提供有线程安全的AtomicInteger为啥不用,尽管AtomicInteger是线程安全的,但是接下来我们还是要聊一聊为啥锁不住Integer等原始数据类型的封装类型。
?
JAVA5为原始数据类型提供了自动装/拆箱功能,假设对Integer进行递增/递减操作后,其实HashCode已经发生了变化,synchronized自然也不是同一个对象实例,Integer的源码,如下所示:
?
?
从源码中可以看出,当为Integer赋值数值在-128~127区间时,会从Integer中的一个Integer[]中获取一个缓存的Integer对象,而超出区间值得时候,每次都会new一个新的Integer对象,假设下述这段代码:
Integer num?= new?Integer(300);
System.out.println("identityHashCode-->"?+ System.identityHashCode(num));
System.out.println("hashCode-->"?+ num.hashCode());
num?= 300;
System.out.println("identityHashCode-->"?+ System.identityHashCode(num));
System.out.println("hashCode-->"?+ num.hashCode());
?
实际程序输出为:
identityHashCode-->627248822
hashCode-->300
identityHashCode-->523481450
hashCode-->300
?
?
Synchronized锁的是对象,也就是identityHashCode所指向的内存地址中的对象实例(根据对象内存地址生成散列值),而hashcode输出的是值得散列值。所以为啥上述程序示例中,identityHashCode每次不同,而hashCode输出的值却相同。
?
最后总结下,synchronized(Integer)时,当值发生改变时,基本上每次锁住的都是不同的对象实例,想要保证线程安全,推荐使用AtomicInteger之类会更靠谱。
?