? ? ? ? �ڼ���������е������ڴ洢�ͼ���ʱ������������ʽ���ڡ�����ƽʱʹ�õ� a, b, c���ַ���ҲҪת���ɶ����Ʒ�ʽ���д洢�������ĸ����������ֱ�ʾ�ĸ��ַ����ǰ���Լ���γɵ�һ��ӳ��������������?��
? ? ? ? ���û��ͳһ�ı���ÿ���˶������Լ��ķ�ʽ�����ֽں��ַ���ӳ�䣬�Ǿ����ˡ���ˣ�1967�� ASCII �뵮������������������������ĸ�����������֡����ַ��š�Ȼ�� ASCII Ҳ�������ܵģ���Ҫ���������ֻ�ܱ��� 128 ���ַ����ҽ�������Ӣ�ﻷ��������չ��ʤ�β�����ŷ���ԣ����������ĺ����н�ʮ�����91251����ASCII ����ȫ�������á�
? ? ? ? ������д洢��Ϣ����С��λ���ֽڣ�byte������ 8 �� bit���ܹ���ʾ���ַ���Χ�� 2^8 = 256 ������������������ڶ�����ڶ࣬һ���ֽڸ��������Ա�ʾ���з��ţ�������Ҫ����ֽڡ������ܽᣬ���������ɸ��ֽڣ�����һ���ı�ӳ���ϵ����ɴӶ��������ݺ��ض��ַ���֮���ת�����̣���������?��
���磺?
class="java" name="code">// ������̣���Ŀ���ַ�����ֽ���
byte[] bytes = "����".getBytes("UTF-8");
// ������̣��ֽ����ָ��ɿ����ַ�
String s = new String(bytes, "UTF-8");
?
�ڸ���ϵͳ�����磬�ռ���ʴ�����Ϣ��ʱ�����ֽ������ݣ�����ͱ����Ϊ��Ҫ�ˡ�
?Java �кܶ�ط�Ĭ��ʹ�� ISO-8859-1��������֧��������Ҫע�⡣
GBK �� GB18030 ����ȫ���� GB2312��Ҳ����˵�� GB2312 ���ɵı������У������� GBK �� GB18030 ��������
GB18030 �������� GBK
UTF-16 ����Ч����ߣ�������Ҳ�в��㣺
UTF-8 ����Ч���Ե��� UTF-16���������ŵ�����ԣ�����һ����Ƽ� UTF-8����
ISO-8859-1��
��ʽ���ΪISO/IEC 8859-1:1998���ֳ�Latin-1����ŷ���ԡ����ǹ��ʱ�����֯��ISO/IEC 8859�ĵ�һ��8λ�ַ���������ASCIIΪ�������ڿ��õ�0xA0-0xFF�ķ�Χ�ڣ�����96����ĸ�����ţ����Թ�ʹ�ø��ӷ��ŵ�������ĸ����ʹ�á�
��֮��ASCII ��ֻ�����ڴ�Ӣ�Ļ����£���������һЩ���и��ӷ��ŵ��������֣� ?��?��?��?���Լ��������ţ������� ASCII ��������չ�� ISO-8859-1 ���롣�������ŷ�����ԣ����編������������ȣ���Ҳ�����������������ԣ�����ӡ���������ȣ���
?
ISO-8859-1����������£�

���´�����֤���ɴ�ӡ����ͼչʾ�����
?
public class ISO_8859_1 {
private static final String ISO88591 = "ISO-8859-1";
private static void print() throws Exception {
byte[] bytes = new byte[1];
int count = 0;
for (int code = 0x00; code <= 0xFF; code ++) {
bytes[0] = (byte) code;
System.out.print(new String(bytes, ISO88591) + " ");
if (++count % 16 == 0) {
System.out.println();
count = 0;
}
}
}
public static void main(String[] args) throws Exception {
print();
}
}
??
GB2312��
GB2312��GB2312�C80���л��������ұ����������ַ�����ȫ�ơ���Ϣ�����ú��ֱ����ַ����������������ֳ�GB0�����й����ұ��ַܾ�����1981��5��1��ʵʩ��GB 2312����ͨ�����й���½���¼��µȵ�Ҳ���ô˱��롣�й���½�������е�����ϵͳ���ʻ���������֧��GB2312��
����¼6763�����֣�����һ������3755������������3008����ͬʱ��¼�˰���������ĸ��ϣ����ĸ������ƽ������Ƭ������ĸ�������������ĸ���ڵ�682���ַ���
?
ͨ������ EUC-CN ��Ϊ GB2312 �ı�ʾ����EUC-CN ��Ϊ 4 ���뼯��GB2312 ֻ�õ��뼯0���뼯1����
?
�뼯0�����ֽڱ�ʾ����Χ�� 0x21-0x7E����Ӧ���� ASCII �Ŀ���ʾ�ַ���Χ����ô����Ҫ��Ϊ�˼��� ASCII
�뼯1��˫�ֽڱ�ʾ����һ���ֽڳ�Ϊ����λ�ֽڡ����ڶ����ֽڳ�Ϊ����λ�ֽڡ���
��λ�ֽڣ���Χ�� 0xA1-0xF7�����ڶ��ַ����з���������ÿ�� 94 ���ַ�
��λ�ֽڣ���Χ�� 0xA1-0xFE����Ӧ��������ĸ����ַ���94 ���ַ�
�뼯1�ĸ�λ�ֽ����ڶ��ַ����з���������
?
0xA1-0xA9��01-09����0xA1 = 0x01 + 0xA0��0xA0�ǻ���ֵ���������ַ�
0xB0-0xD7��16-55����һ�����֣���ƴ������ĺ���
0xD8-0xF7��56�C87�����������֣������ף��ʻ�����
?
10�C15����88�C94����δ�б��롣���� GB2312 ����¼��������ӦΪ��(40 + 32) * 94 = 6768 ��������һ���������������� 5 ���ַ�û�б��룬����ʵ����¼��������Ϊ��6768 - 5 = 6763 ����
?
GB2312�ij��֣����������˺��ֵļ����������Ҫ��������¼�ĺ����Ѿ������й���½99.75%��ʹ��Ƶ�ʡ��������������ź���ȷ�����ֵĺ����ֺͷ����֣�GB2312���ܴ�������˺���GBK��GB18030�����ַ�����̳����Խ����Щ���⡣
����������֤��֪��
?
public class GB2312 {
private static final String GB2312 = "GB2312";
private static final int BASE = 0xA0;
private static void printSet0() throws Exception {
byte[] bytes = new byte[1];
for (int code = 0x21; code <= 0x7E; code++) {
bytes[0] = (byte) code;
System.out.print(new String(bytes, GB2312));
}
System.out.println();
}
private static void printSet1(int highBegin, int highEnd) throws Exception {
byte[] bytes = new byte[2];
for (int high = highBegin; high <= highEnd; high++) {
System.out.print(high + ": ");
bytes[0] = (byte) (BASE + high);
for (int low = 1; low <= 94; low++) {
bytes[1] = (byte) (BASE + low);
System.out.print(new String(bytes, GB2312) + "");
}
System.out.println();
}
}
public static void main(String[] args) throws Exception {
System.out.println("\n�뼯0[ASCII����ʾ�ַ�]: ");
printSet0();
System.out.println("\n�뼯1[PART1 �������]: ");
printSet1(1, 9);
System.out.println("\n�뼯1[PART2 һ������]: ");
printSet1(16, 55);
System.out.println("\n�뼯1[PART3 ��������]: ");
printSet1(56, 87);
}
}
??
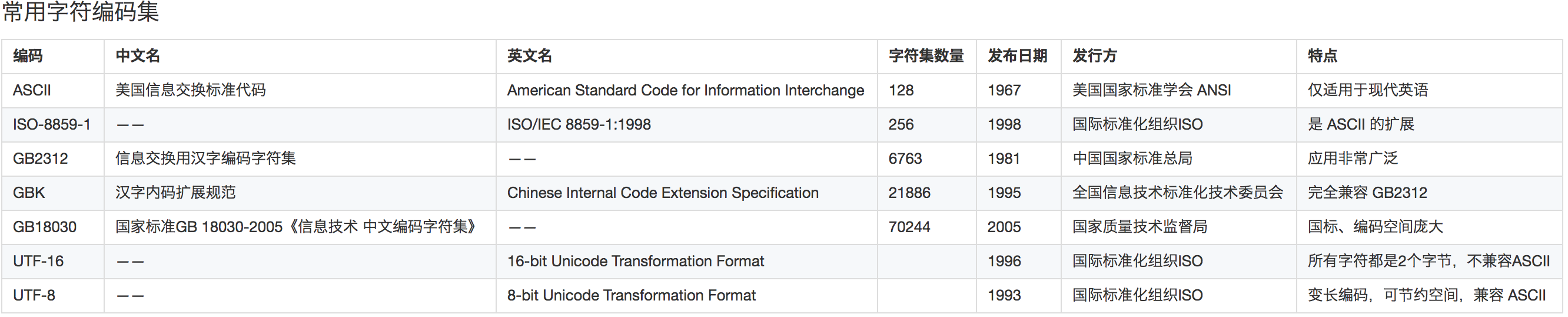
GBK��
����������չ�淶����GBK��ȫ��Ϊ������������չ�淶(GBK)��1.0�棬���л�����ȫ����Ϣ������������ίԱ��1995��12��1���ƶ������Ҽ����ල�ֱ���˾�͵��ӹ�ҵ���Ƽ��������ල˾1995��12��15�������ԡ������꺯[1995]229�š��ļ�����ʽ������ GBK����¼21886�����ֺ�ͼ�η��ţ����к��֣�������������21003����ͼ�η���883����
����GB1312���뷶Χʵ�����ޣ��ܶ���֡��¼��֡�����ȶ���֧�֣������Ƴ��� GBK ���롣GBK ������ȫ���� GB1312��Ҳ����˵ GB1312 ��������ݣ������� GBK �����������롣
?
���뷽ʽ�� GB1312 ���ƣ�Ҳ�������ֽں�˫�ֽ����ַ�ʽ��
���ֽڣ���Χ 00�C7F���� ASCII ��ȫһ�£�ע�� GB1312 ��֧�ֲ��� ASCII
?
˫�ֽڣ���ȫ���� GB1312 ��˫�ֽڣ�
���£�
?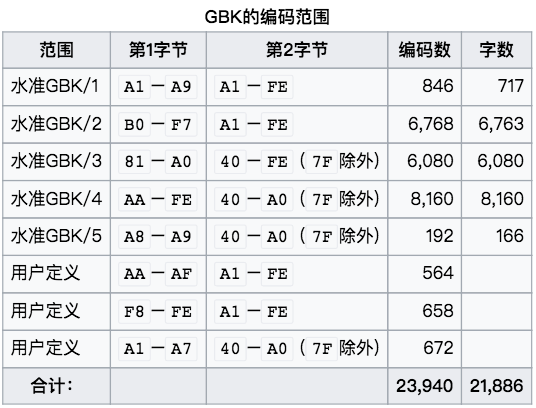
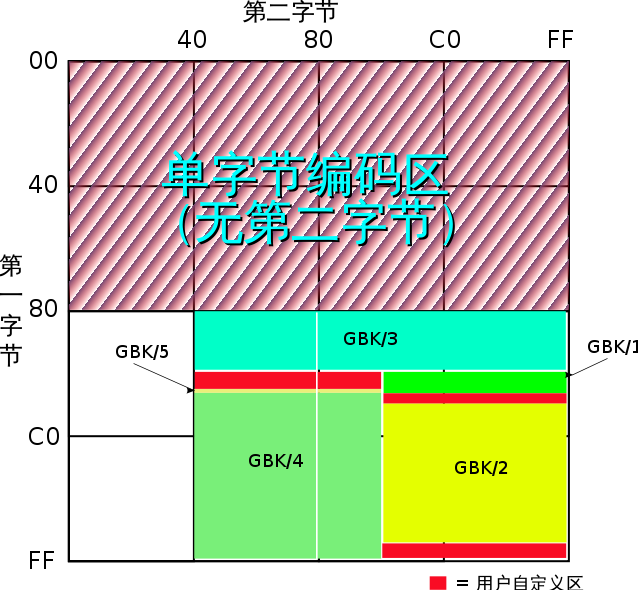
?���Կ�����GBK/1 �� GBK/2 �� GB1312 ��ȫһ�£���������������չ�ı��롣
������ GBK ����ͼ�����Կ���GBK/1��GBK/2������GB 2312-80��ͨ���������������GB2312�ж���AA�CAF��F8�CFE�����ǿյģ�û�и�����롣����GBK������Щ�����������չ������ʣ�ಿ����Ϊ�û���������
?
UTF-8��
UTF-8��8-bit Unicode Transformation Format����һ�����Unicode�Ŀɱ䳤���ַ����룬Ҳ��һ��ǰ�롣������������ʾUnicode���е��κ��ַ�����������еĵ�һ���ֽ�����ASCII���ݣ���ʹ��ԭ������ASCII�ַ������������ֻ�����ٲ����ģ����ɼ���ʹ�á�
Unicode�����ģ�����롢�����롢ͳһ�롢��һ�룩�Ǽ������ѧ�������һ��ҵ��������������ϴֵ�����ϵͳ���������������룬ʹ�õ��Կ����ø�Ϊ�ķ�ʽ�����ֺʹ������֡����ϵ����еĵ����Ա��뷽�������� GB2312��GBK�ȵȣ���ͳһʹ�� 2 ���ֽڣ�����ָ���� UCS-2��UCS-4ʹ�� 4 ���ֽڣ�����ʾ�����ַ���Ҳ����˵���ܱ��뷶Χ�� 65536��
?
U+0000 - U+007F��128 �� ASCII �ַ�
U+0080 - U+07FF�����и��ӷ��ŵ������ġ�ϣ���ġ��������ĸ�����������ϣ�����ġ��������ġ��������ĵ�
U+0800 - U+FFFF����������������ƽ�棨BMP���е��ַ���������˴ֳ����֣���ֵĺ��֣�
U+10000 - U+7FFFFFFF����������ʹ�õ�Unicode ����ƽ����ַ�
Unicodeֻ��һ�����ż�����ֻ�涨�˷��ŵĶ����ƴ��룬ȴû�й涨��������ƴ���Ӧ����δ洢��
���硰�����ֵ�unicodeʮ�����Ʊ����ǣ���4E8C������Ӧ�������ǣ���100111010001100������15λ��Ҳ����˵������Ҫ�����ֽ����洢�������������ˣ���һ�ζ��������������������ַ���1���ֽڡ�����2���ֽڣ�
?
UTF-8 ���� Unicode ��һ��ʵ�ַ�ʽ����������ʵ�ַ�ʽ������ UTF-16��UTF-10�ȣ��������ص�����1-4���ֽ����洢һ���ַ������ǿɱ䳤�ȡ�Unicode �� UTF-8 ��ת����ϵ���£�
?
���� 1 ���ֽڣ����λ���� 8 λ����0�����ʾ���� 1 �� ASCII �ַ�
���� 1 ���ֽڣ��� 11 ��ͷ���������� 1 �ĸ�����ʾ����ַ����ֽ��������� 110xxxxx ��ʾ����˫�ֽ� UTF-8 �ַ������ֽ�
���� 1 ���ֽڣ��� 10 ��ͷ�����ʾ���������ֽڣ���Ҫ��ǰ���ҵõ���ǰ�ַ������ֽ�
UTF-8ʹ��1-6���ֽ�Ϊÿ���ַ����룺
?
U+0000 - U+007F��1 ���ֽ�
U+0080 - U+07FF��2 ���ֽ�
U+0800 - U+FFFF��3 ���ֽ�
U+10000 - U+1FFFFF��4 ���ֽ�
U+200000 - U+3FFFFFF��5 ���ֽ�
U+4000000 - U+7FFFFFFF��6 ���ֽ�
���磺
?
����"��"�ֵ�Unicode������6C49��6C49��0800-FFFF֮�䣬����Ҫ��3�ֽ�ģ�壺1110xxxx 10xxxxxx 10xxxxxx����6C49д�ɶ������ǣ�0110 1100 0100 1001������������������ֽ�ģ��ķֶη�����Ϊ0110 110001 001001�����δ���ģ���е�x���õ���1110-0110 10-110001 10-001001����E6 B1 89�������UTF8���롣
?
���Ľ�ѡ�������������£���������֮�á���л����
?