���ձ���ԭ���Ĺ۵�,��������ʱ��
�ڴ����������ֲ���,�ֱ��Ǿ�̬��,ջʽ��,�Ͷ�ʽ��.
������̬�洢������ָ�ڱ���ʱ����ȷ��ÿ������Ŀ��������ʱ�̵Ĵ洢�ռ�����,����ڱ���ʱ�Ϳ��Ը�
��������̶����ڴ�ռ�.���ַ������Ҫ���������в������пɱ����ݽṹ(����ɱ�����)�Ĵ���,Ҳ��������Ƕ����
�ݹ��Ľṹ����,��Ϊ���Ƕ��ᵼ��
�������������ȷ�Ĵ洢�ռ�����.
����ջʽ�洢����Ҳ�ɳ�Ϊ��̬�洢����,����һ��������
��ջ������ջ��ʵ�ֵ�.�;�̬�洢�����෴,��ջʽ�洢������,������������������ڱ���ʱ����ȫδ֪��,ֻ�е����е�ʱ����ܹ�֪��,���ǹ涨�������н���һ������ģ��ʱ,����֪���ó���ģ���������������С���ܹ�Ϊ������ڴ�.�����������ݽṹ����֪��ջһ��,ջʽ�洢���䰴���Ƚ������ԭ����з��䡣
������̬�洢����Ҫ���ڱ���ʱ��֪�����б����Ĵ洢Ҫ��,ջʽ�洢����Ҫ���ڹ��̵���ڴ�����֪�����еĴ洢Ҫ��,����ʽ�洢������ר�Ÿ����ڱ���ʱ������ʱģ����ڴ�����ȷ���洢Ҫ������ݽṹ��
�ڴ����,����ɱ䳤�ȴ��Ͷ���ʵ��.���ɴ�Ƭ�Ŀ����ÿ����п����,���е��ڴ����������˳�������ͷ�.
�����Ѻ�ջ�ıȽ�
��������Ķ���ӱ���ԭ���Ľ̲����ܽ����,����̬�洢����֮��,���Եúܴ��������
����,����Ʋ����̬�洢����,���бȽ϶Ѻ�ջ:
�����ӶѺ�ջ�Ĺ��ܺ�������ͨ�ıȽ�,����Ҫ������Ŷ���ģ�ջ��Ҫ������ִ�г����.�����ֲ�ͬ����Ҫ�����ڶѺ�ջ���ص������:
�����ڱ���У�����C/C++�У����еķ������ö���ͨ��ջ�����е�,���еľֲ�����,��ʽ�������Ǵ�ջ�з����ڴ�ռ�ġ�ʵ����Ҳ����ʲô����,ֻ�Ǵ�ջ�� �����þ���,�ͺ����еĴ��ʹ�(conveyor belt)һ��,Stack Pointer���Զ�ָ���㵽�Ŷ�����λ��,����Ҫ����ֻ�ǰѶ�������������.�˳�������ʱ����ջָ��Ϳ���ջ�е���������.������ģʽ�ٶ����, ��ȻҪ�������г�����.��Ҫע�����,�ڷ����ʱ��,����Ϊһ������Ҫ���õij���ģ�����������ʱ,Ӧ����֪������������Ĵ�С,Ҳ��˵����Ȼ�������ڳ� ������ʱ���е�,���Ƿ���Ĵ�С������ȷ����,�����,���������С���١����ڱ���ʱȷ����,����������ʱ.
��������Ӧ�ó��������е�ʱ���������ϵͳ������Լ��ڴ棬���ڴӲ���
ϵͳ�������ڴ����,�����ڷ��������ʱ��Ҫռ��ʱ�䣬����öѵ�Ч�ʷdz���.���Ƕѵ� �ŵ�����,����������֪��Ҫ�Ӷ��������ٴ洢�ռ䣬Ҳ����֪���洢������Ҫ�ڶ���ͣ�����ʱ��,���,�öѱ�������ʱ��õ����������ԡ���ʵ��,�� �����Ķ�̬��,���ڴ�����DZز����ٵ�,��Ϊ��̬��������Ĵ洢�ռ�ֻ��������ʱ�����˶���֮�����ȷ��.��C++�У�Ҫ��һ������ʱ��ֻ���� new���������صĴ��뼴�ɡ�ִ����Щ����ʱ�����ڶ����Զ��������ݵı���.��Ȼ��Ϊ�ﵽ��������ԣ���Ȼ�Ḷ��һ���Ĵ���:�ڶ������洢�ռ�ʱ�Ứ ��������ʱ�䣡��Ҳ���ǵ������Ǹղ���˵��Ч�ʵ͵�ԭ��,��������ͬ־˵�ĺ�,�˵��ŵ�����Ҳ���˵�ȱ��,�˵�ȱ������Ҳ���˵��ŵ�(��~).
����
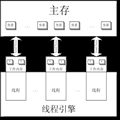
JVM�еĶѺ�ջ
����JVM�ǻ��ڶ�ջ�������.JVMΪÿ���´�����
�߳�������һ����ջ.Ҳ����˵,����һ��Java������˵���������о���ͨ���Զ�ջ�IJ�������ɵġ���ջ��֡Ϊ��λ�����̵߳�״̬��JVM�Զ�ջֻ�������ֲ���:��֡Ϊ��λ��ѹջ�ͳ�ջ������
��������֪��,ij���߳�����ִ�еķ�����Ϊ���̵߳ĵ�ǰ����.���ǿ��ܲ�֪��,��ǰ����ʹ�õ�֡��Ϊ��ǰ֡�����̼߳���һ��Java����,JVM�ͻ�
�����̵� Java��ջ����ѹ��һ��֡�����֡��Ȼ��Ϊ�˵�ǰ֡.�ڴ˷���ִ���ڼ�,���֡�������������,�ֲ�����,�м������̺���������.���֡������ͱ��� ԭ���еĻ��¼�ĸ����Dz���.
������Java�����ַ����������,��ջ�ֿ�����������:��ջ(Stack)�Dz���ϵͳ�ڽ���ij������ʱ�����߳�(��֧�ֶ��̵߳IJ���ϵͳ�����߳�)Ϊ����߳̽����Ĵ洢������������Ƚ���������ԡ�
����ÿһ��JavaӦ�ö�Ψһ��Ӧһ��JVMʵ����ÿһ��ʵ��Ψһ��Ӧһ���ѡ�Ӧ�ó�������������������������ʵ�������鶼�����������,����Ӧ�����е��߳� ����.��C/C++��ͬ��Java�з�����ڴ����Զ���ʼ���ġ�Java�����ж���Ĵ洢�ռ䶼���ڶ��з���ģ�����������������ȴ���ڶ�ջ�з���,Ҳ ����˵�ڽ���һ������ʱ�������ط��������ڴ棬�ڶ��з�����ڴ�ʵ�ʽ�����������ڶ�ջ�з�����ڴ�ֻ��һ��ָ������Ѷ����ָ��(����)���ѡ�
���������˵��
����ջ��Ѷ���Java������Ram�д�����ݵĵط�����C++��ͬ��Java�Զ�����ջ�Ͷѣ�
����Ա����ֱ�ӵ�����ջ��ѡ�
����Java�Ķ���һ������ʱ������,��Ķ�����з���ռ䡣��Щ����ͨ��new��newarray��anewarray��multianewarray��ָ ��������Dz���Ҫ�����������ʽ���ͷš���������������������ģ��ѵ������ǿ��Զ�̬�ط����ڴ��С��������Ҳ�������ȸ��߱���������Ϊ����������ʱ�� ̬�����ڴ�ģ�Java�������ռ������Զ�������Щ����ʹ�õ����ݡ���ȱ���ǣ�����Ҫ������ʱ��̬�����ڴ棬��ȡ�ٶȽ�����java�еĶ�������鶼����ڶ��С�
����ջ�������ǣ���ȡ�ٶȱȶ�Ҫ�죬�����ڼĴ�����ջ���ݿ��Թ�������ȱ���ǣ�����ջ�е����ݴ�С�������ڱ�����ȷ���ģ�ȱ������ԡ�ջ����Ҫ���һЩ�������͵ı�����,int, short, long, byte, float, double, boolean, char���Ͷ������á�
����ջ��һ������Ҫ�������ԣ����Ǵ���ջ�е����ݿ��Թ�������������ͬʱ���壺
����int a = 3;
����int b = 3��
�����������ȴ���int a = 3������������ջ�д���һ������Ϊa�����ã�Ȼ�����ջ���Ƿ���3���ֵ�����û�ҵ����ͽ�3��Ž�����Ȼ��aָ��3�����Ŵ���int b = 3���ڴ�����b�����ñ�������Ϊ��ջ���Ѿ���3���ֵ���㽫bֱ��ָ��3���������ͳ�����a��bͬʱ��ָ��3���������ʱ���������a=4����ô������ ����������ջ���Ƿ���4ֵ�����û�У���4��Ž���������aָ��4������Ѿ����ˣ���ֱ�ӽ�aָ�������ַ�����aֵ�ĸı䲻��Ӱ�쵽b��ֵ��Ҫע���� �����ݵĹ������������������ͬʱָ��һ����������ֹ����Dz�ͬ�ģ���Ϊ�������a���IJ�����Ӱ�쵽b, �����ɱ�������ɵģ��������ڽ�ʡ�ռ䡣��һ���������ñ����������������ڲ�״̬����Ӱ�쵽��һ���������ñ�����
����ps:����c++���ڴ����
����һ����C/C++����ij���ռ�õ��ڴ��Ϊ���¼�������
����1��ջ����stack���� �ɱ������Զ������ͷ� ����ź����IJ���ֵ���ֲ�������ֵ�ȡ��������ʽ���������ݽṹ�е�ջ��
����2��������heap�� �� һ���ɳ���Ա�����ͷţ� ������Ա���ͷţ��������ʱ������OS���� ��ע���������ݽṹ�еĶ��������£����䷽ʽ�����������������Ǻǡ�
����3��
ȫ��������̬������static������ȫ�ֱ����;�̬�����Ĵ洢�Ƿ���һ��ģ���ʼ����ȫ�ֱ����;�̬������һ������ δ��ʼ����ȫ�ֱ�����δ��ʼ���ľ�̬���������ڵ���һ������ �C �����������ϵͳ�ͷ�
����4�����ֳ����� �������ַ������Ƿ�������ġ� �����������ϵͳ�ͷ�
����5���������������ź�����Ķ����ƴ��롣
��������
��������
��������һ��ǰ��д�ģ��dz���ϸ
����//main.cpp
����int a = 0; ȫ�ֳ�ʼ����
����char *p1; ȫ��δ��ʼ����
����main()
����{
����int b; ջ
����char s[] = ��abc��; ջ
����char *p2; ջ
����char *p3 = ��123456��; 123456\0�ڳ�������p3��ջ�ϡ�
����static int c =0�� ȫ�֣���̬����ʼ����
����p1 = (char *)malloc(10);
����p2 = (char *)malloc(20);
�������������10��20�ֽڵ�������ڶ�����
����strcpy(p1, ��123456��); 123456\0���ڳ����������������ܻὫ����p3��ָ��ġ�123456���Ż���һ���ط���
����}
ԭ�ģ�http://www.examda.com/Java/zhuanye/20100907/110421485.html