上个月,我们发布了牛津计划机器学习的情感识别API,能够帮助不同平台的开发者轻松添加智能应用,而无需精通人工智能领域。牛津计划仅仅是微软在人工智能领域探索中的一个实例,而我们的期望是实现更加注重个人使用体验和更优性能的产品,逐渐实现它看、听、说、理解甚至是进行推论的性能。
现在,声纹识别API和视频API已经公开预览,自定义识别智能服务(CRIS)可通过www.ProjectOxford.ai进行访问。
CRIS能提供开发者构建针对特定词库、环境、或用户群的语音识别系统。视频API使得分析和自动编辑视频更加便捷,它能识别出视频中的单个人脸并进行追踪,还能根据一组参数检测出视频中人物或者物体的动作,并且对视频进行流畅性和稳定性处理。
接下来,我们一起来了解声纹识别API的更多背景——如何使用以及它究竟使用了何种技术。
使用场景示例:使用声纹识别API实现更强的身份认证功能
声纹识别API可以根据声音识别出用户和客户(说话者),然而声纹识别API将不会取代更强的验证工具,而是提升验证工具的安全级别。声纹识别API还有另一个功能,就是通过自动识别用户,而无需代理人进行一问一答的过程手动验证客户身份信息,从而提升了客户服务体验。
声纹识别的目标是帮助开发者构建智能自动识别机制,在便捷使用者的同时又能避免欺诈情况的发生,但这并不是一件简单的事。在理想情况下,要进行身份认证需要以下三种信息:
声音有着独特的特征,能够用它来鉴别人,在这方面过去几年内声纹识别系统有着巨大的提升。(详见文章末尾参考文献【1】【3】)
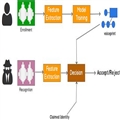
使用声纹识别API有两个阶段——注册登记和识别:
注册阶段:记录下说话者的声音,从中提取大量特征,形成独特的声纹,生成某一个人的唯一标识。这些特征是基于说话者口腔和咽喉的物理状态,然后表示为数学公式。
识别阶段:用提供的语言样本与预先创建的声纹进行对比。

声纹识别两阶段(编辑自Douglas Reynolds PPT)
声纹识别提供了最先进的算法,从音频流中识别人的声音,包括验证和辨识两部分:
说话人验证:根据用户声音或演讲自动识别和确认身份。它与身份验证方案密切相连,通常需要使用密码短语。因此,我们选择了文本依赖识别方式:即在注册和验证阶段说话者都需要选择使用一个特定的密码短语。
说话人辨识:从给定的一组说话者音频中自动识别出样本音频的说话人。将输入音频与所提供的一组音频进行一一配对,如果找到匹配的,则识别出了说话者的身份,这是文本独立识别方式:即在注册和识别阶段对于说话者的内容没有限制。
声纹识别技术综述
包括成熟API在内的现代系统,大都使用了i-矢量方法。文献中的大部分工作都集中在场景验证,不论是与文本无关的NIST评估还是文本依赖型的密码短语,例如RSR数据库。二者通过标准测试,以及针对会议场景(有无排斥反应)内的大型识别任务测试,建立了基准。它在验证任务中获得的结果很有竞争力,有最高的精准度。在辨识方面,精确度超90%,而拒绝率只有约5%。
以下将简要总结不同技术组件,给感兴趣的读者提供参考。
我们简要概括声纹识别系统的i-矢量基本程序,并重点讨论一下身份确认,声音识别在修改评分阶段仅做了简单的修改。
特征提取:特征提取每10ms会生成一个表示语音的向量,梅尔频率倒谱系数(MFCC)被广泛地用于说话者和语音识别中。API中,我们使用一个强健、专有版本的MFCC,相当于60维的MFCC,它广泛用于声纹识别,在嘈杂环境中性能提升显著。
无监督训练:这一步被称为无监督训练,是因为它不使用说话者的标签。相反,它使用大的高斯混合模型来描述听觉空间和总变化矩阵来描述说话者(和信道)空间。构建通用背景模型(UBM)从早期的声纹识别,到使用大量数据和标准GMM训练技术进行构造此模型过程中,都是很有名的。另一方面,关于在联合因子分析(JFA)的背景下研究的T矩阵,建议读者参考【1】介绍。同时使用UBM和T,一个声音可以映射到固定的三维空间中(通常是在几百的量级),在这个空间构造判别变换,并注册登记和评分。
监督训练:在训练中,一旦构造出UBM模型和T矩阵,每一种表述方式和说话者标签都会映射到一个固定维度的向量中,使用这些(向量,标签),构造一个概率线性判别分析模型(PLDA)(可以把它看做一个有助于分解说话者和信道变化的概率线性判别分析模型)。如何训练和使用PLDA,详见【2】。训练PLDA模型,和找到在注册和测试阶段使用的相同变量是非常重要的(例如,在文本依赖型的确认阶段中通道变化和语音变化),这些在实践中都有很好的表现。
登记注册/测试:以上这些步骤是在使用一个大规模数据库的前提下。实际上,上述所有模型都是使用了数以千计小时的音频训练而来,这些在我们的API中都有提供。在注册登记阶段,每一个说话者将使用该系统表示的短语或长句的实例(用于文本依赖验证)。例如,一分钟的段落或者文本独立的确认或识别。使用输入构造出在i-矢量的说话者空间模型。在测试阶段,被测试的表达方式映射到i-矢量空间并与说话者模型进行比较后作出判断。
希望大家很快就能使用这些API,如果你想查看关于在牛津计划中用到的其它技术的文章,请反馈给我们。
参考文献:
【1】NajimDehak, Patrick Kenny, Pierre Dumouchel, Reda Dehak, Pierre Ouellet, ?Front-endfactor analysis for speaker verification ? in IEEE Transactions on Audio,speech and Language Processing 2011.
【2】Simon J.D. Prince, James H. Elder, ?Probabilistic lineardiscriminant analysis for inference about identity ? in Proceedings ICCV 2007.
【3】Anthony Larcher, Kong Aik Lee, Bin Ma, Haizhou Li, ?Text-dependent speaker verification: Classifiers, databases and RSR2015?in Speech Communication, (60), 2014.
最后,小编还有一个呼吁:
立即访问http://market.azure.cn